FaceID 是新款 iPhone 最受欢迎的功能之一,它取代 TouchID 成为了最前沿的解锁方式。
为了实现 FaceID 技术,苹果采用了先进而小巧的前置深度相机,这使得 iPhone X 能创建用户脸部的 3D 映射。此外,它还引入了红外相机来捕捉用户脸部图片,它拍摄到的图片对外界环境的光线和颜色变化具有更强的鲁棒性。
学习Python中有不明白推荐加入交流群
号:960410445
群里有志同道合的小伙伴,互帮互助,
群里有不错的视频学习教程和PDF!
通过深度学习,智能手机能够非常详细了解用户脸部信息。所以当用户接电话时,手机就会自动识别并解锁。但更令人吃惊的或许是它的安全性,苹果公司技术人员表示,相比于 TouchID ,FaceID 的出错率只有 1:1000000。
我对苹果 FaceID 及其背后的深度学习技术非常感兴趣,想知道如何使用深度学习来实现及优化这项技术的每个步骤。在本文中,我将介绍如何使用深度学习框架 Keras 实现一个类似 FaceID 的算法,解释我所采取的各种架构决策,并使用 Kinect 展示一些最终实验结果。Kinect 是一种非常流行的 RGB 深度相机,它会产生与 iPhone X 前置摄像头类似的结果。
▌理解 FaceID 工作原理
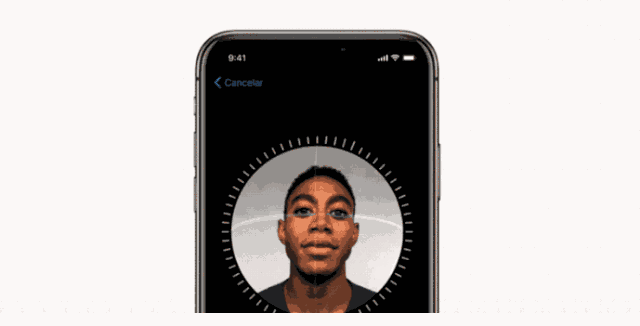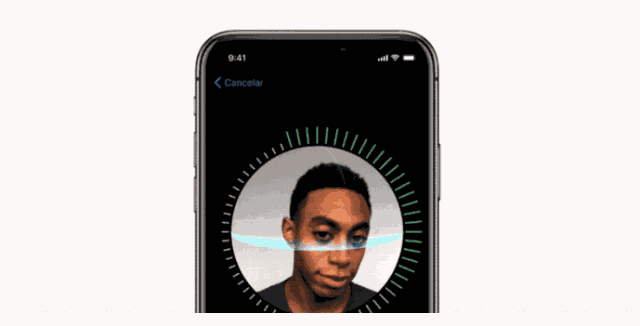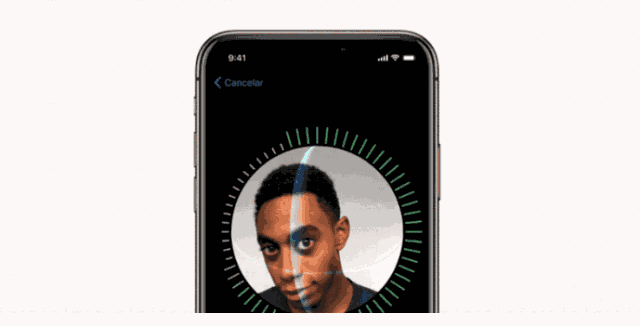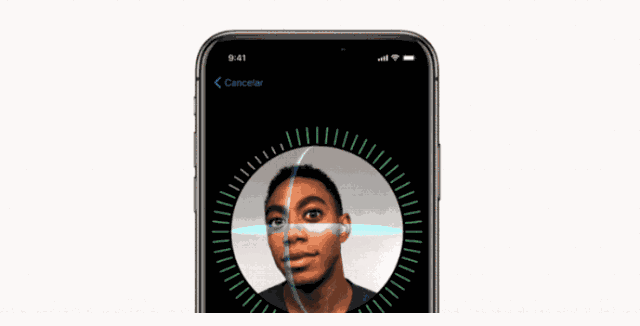
FaceID 的设置过程
首先,我们需要分析 FaceID 的工作原理,了解它是如何在 iPhone X 上运作的。但在这之前,我们还是说一下 TouchID 一些基本操作:当用户使用 TouchID 时,必须按压几次传感器进行初始化,并且记录指纹,大约经过 15-20 次不同角度的触摸之后,指纹信息将在手机上完成注册,这样 TouchID 也就准备就绪了。
同样地,使用 FaceID 也需要用户注册他\她的脸,这个过程非常简单:用户只需以一种自然的方式看手机屏幕,然后慢慢将头部转一圈,以不同姿势记录脸部信息。如此,用户就可以使用手机的人脸解锁功能了。
这样快速的注册过程可以告诉我们一些 FaceID 背后深度学习算法的相关信息。例如,支持 FaceID 的神经网络不仅仅是执行分类这么简单。

Apple Keynote 推出 iPhone X 和 FaceID 新功能
对神经网络而言,一个目标分类任务意味着模型需要去推测一张脸是否与该用户匹配。通常情况下,解决这类问题要使用一些数据来训练模型,让模型学习如何辨别真(Ture)假(False)。不过,这种方法却不能应用到 FaceID 的模型训练中,它不同于其他深度学习案例。
首先,神经网络需要重新使用从用户脸上获得的新数据进行训练,而这需要大量时间、能耗和庞杂的人脸训练数据,这种方法不切实际。当然,你也可以用迁移学习,对预训练好的网络进行微调,情况可能会有所好转,但也无法从根本上解决问题。此外,这种方法也无法利用苹果实验室中离线训练好的复杂网络,这样也就不能将更先进的网络模型部署到手机上了。
那 FaceID 的模型训练究竟如何呢?
实际上,FaceID 使用的是类似暹罗式卷积神经网络(siamese-like convolutional neural network)来驱动。这种网络模型是由苹果离线训练好的,能将脸部信息映射到低维潜在空间,通过使用对比损失(contrastive loss)来最大化不同人脸之间的差异。如此,你就得到了一个准确的、适用于少样本学习(one-shot learning)的模型结构,而这种模型在只有少量训练样本的情况下,也能够学习样本特征并进行推测分类。

▌****暹罗神经网络及其优势****
一般而言,它由两种相同神经网络组成,这两种神经网络共享所有权重。该网络结构可以计算特定类型的数据(如图像)之间的距离。通过暹罗网络传递数据,或者简单地通过两个不同步骤向同一网络传递数据,网络会将其映射到一个低维特征空间,好比一个 n 维数组。然后,你需要训练网络产生特征映射,从而获取尽可能多的不同类别的数据点,而同一类别的数据点尽可能是接近的。
我们所希望的是,该网络能够从数据中提取并学习到最有意义的特征,并将其压缩成一个数组,来创建一个有意义的映射。
为了能更直观地理解这一过程,想象一下如何使用 small vector 来描述狗的品种,使得相似的狗具有更接近的向量。你可能会用一个数字来编码狗的毛色、狗的大小、毛的长度等等。这样,相似的狗就会具有相似的特征向量。同样地,一个暹罗神经网络可以帮你完成这件事,用不同编码来表示目标的不同特征,就像是一个自动编码器。
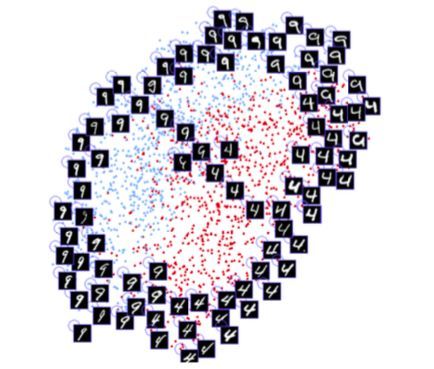
上图来自 Hadsell,Chopra 和 LeCun 发表的论文“Dimensionality Reduction by Learning an Invariant Mapping”。注意,模型是如何学习数字之间的相似性,并在二维空间中自动地将它们分组的。FaceID 就采用了与这类似的技术。
通过这种技术,人们可以使用大量人脸数据来训练这样的模型结构,最终目标是让模型自动识别哪些人脸是最相似的。此外,我们不仅需要对模型的计算成本有准确预算,还要让模型能够适应越来越难的人脸案例,譬如使神经网络对识别诸如双胞胎、对抗性攻击(掩模)等事物时也具有强鲁棒性。
苹果的这种方法的优势在哪里?
我们最终拥有的是一个现用模型,只需在初始设置过程中拍摄一些人脸照片后,计算人脸位于所在的脸部映射空间中的位置即可,而不需要再进一步训练或优化模型以识别不同用户。正如前面狗的品种分类问题一样,它为一只新品种的狗编码其特征向量,并将其存储到特征空间。此外,FaceID 能够自适应用户的面部变化,如一些突兀的变化(眼镜、帽子和化妆)和一些轻微的变化(面部毛发)。这些特征变化通常只需通过在脸部特征空间添加一些参考面向量即可,之后再根据这些向量进行新的面部特征计算。

FaceID 能自动适应脸部变化
下面,我将介绍如何在 Python 中用 Keras 框架来实现上述过程。
▌用 Keras 实现 FaceID
对于所有的机器学习项目而言,首先需要的是数据。创建我们自己的人脸数据集需要大量时间和人工成本,这将是个极具挑战性的任务。我在网上看到一个 RGB-D 人脸数据集,发现它非常合适作为我们的人脸数据集。该数据集由一系列面向不同方向,并带不同人脸表情的 RGB-D 图片组成,就像 iPhone X 中 FaceID 所需的人脸数据一样。
然后,我构建了一个基于 SqueezeNet 架构的卷积神经网络。该网络以耦合人脸的 RGBD 图像作为输入,因此输入图像的维度是 4 通道,输出则是两个嵌入值之间的距离。该网络训练时会产生一种对比损失,可以最大限度减少图片中相似的人之间的距离,并使图片中不同的人之间的距离最大化。对比损失函数的数学表达式如下:
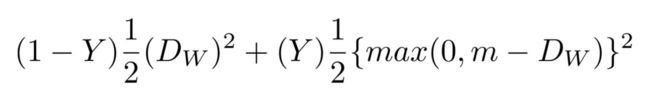
对比损失函数表达式
经过模型训练后,该网络能够将人脸映射成 128 维数组,并将图片中相同的人分在同一组,与图片中其他人的距离尽可能远。这意味着,要解锁你的手机,该网络只需计算在解锁过程中拍摄的人脸照片与注册时所存储的人脸照片之间的距离。 如果这个距离低于某个阈值,则会解锁手机,阈值设置得越小,你的手机将越安全。
此外,我使用了 t-SNE 算法在 2 维空间上可视化 128 维的嵌入空间,用每种颜色对应不同的人:正如下面你所看到的,该网络已经学会如何将这些人脸进行准确分组。值得注意的是,使用 t-SNE 算法进行可视化时,簇(cluster)与簇之间的距离没有意义。此外,当你使用 PCA 降维算法进行可视化时也会看到一些有趣的现象。
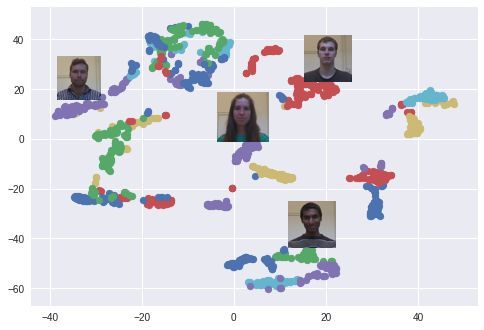
使用 t-SNE 算法在嵌入空间生成不同的人脸簇。每一种颜色代表不同人脸(这里部分颜色被重复使用)
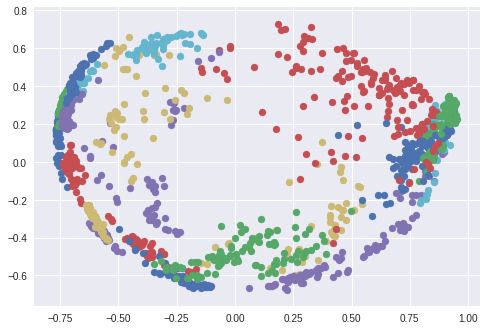
使用 PCA 算法在嵌入空间生成不同人脸簇。每种颜色代表不同人脸(这里部分颜色被重复使用)
▌实验!
现在,我们将模拟一个通用的 FaceID 解锁过程,看看其中的模型是如何进行运作的。首先,注册一个用户的脸部信息;在解锁阶段,其他用户在正常情况下都不能够成功解锁设备。如前所述,神经网络会在解锁阶段计算当前人脸与所注册人脸图片之间的距离,并且会查看该距离是否小于某个阈值。
我们从注册阶段开始,在数据集中采集同一个人的人脸照片,并模拟整个注册阶段。 随后该设备将计算当前每个人脸姿势的嵌入,并将其存储在本地。

一个新用户在 FaceID 上的注册过程

来自深度相机所看到的注册过程
现在来看,当同一用户试图解锁设备时会发生什么?我们可以看到,来自同一用户的不同姿势和面部表情都有着较低的距离,平均距离约为 0.30。

嵌入空间中来自同一用户的人脸距离计算
而不同的人的 RGBD 人脸图像,计算得到的距离值为 1.1。

嵌入空间中来自不同用户的人脸距离计算
因此,将距离阈值设置为 0.4 就足以防止陌生人解锁你的手机。
▌结论
在这篇文章中,从概念到实验验证,展示了如何基于人脸嵌入和暹罗卷积神经网络来实现FaceID 的解锁机制。
所有相关 Python 代码都在这里,收好不谢!
https://github.com/normandipalo/faceID_beta