pymongo来操作MongoDB数据库,但是直接把对于数据库的操作代码都写在脚本中,这会让应用的代码耦合性太强,而且不利于代码的优化管理
一般应用都是使用MVC框架来设计的,为了更好地维持MVC结构,需要把数据库操作部分作为model抽离出来,这就需要借助MongoEngine
MongoEngine是一个对象文档映射器(ODM),相当于一个基于SQL的对象关系映射器(ORM)
MongoEngine提供的抽象是基于类的,创建的所有模型都是类
1、安装
pip install mongoengine
2、连接+定义
使用时先声明一个继承自MongoEngine.Document的类
在类中声明一些属性,相当于创建一个用来保存数据的数据结构,即数据已类似数据结构的形式存入数据库中,通常把这样的一些类都存放在一个脚本中,作为应用的Model模块
from mongoengine import *
import datetime
# 连接MongoDB数据库中 mongo_engone_learn数据库
connect('mongo_engine_learn')
# 不填写地址默认是连接本地数据库,远程需要填写具体的ip地址、密码及端口
# 创建一张Post数据库表
class Post(Document):
title = StringField(required=True, max_length=200) # 每一个字段
content = IntField(required=True) # 字段
author = StringField(required=True, max_length=50) # 字段
published = DateTimeField(default=datetime.datetime.now) # 字段
# 定义一个数据表对象
post_obj = Post(
title='Sample Post',
content='Some engaging',
author='scott'
)
post_obj.save() # 执行对象的save方法,存储到数据库
print(post_obj.title)
post_obj.title = 'buyi' # 修改对象属性
post_obj.save() # 执行修改操作
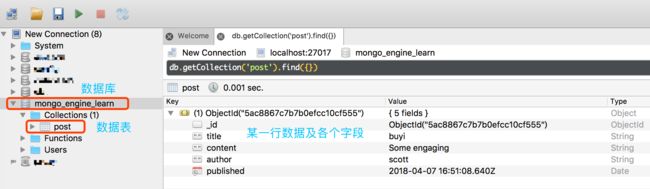
执行结果可视化
配置从读主写
from mongoengine import connect
from pymongo import ReadPreference
connect('mydb', host='mongodb://server1:27017,server2:27017,server3:27017',
replicaSet='replset',
read_preference=ReadPreference.SECONDARY_PREFERRED)
3、查询
- 查询操作
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from mongoengine import *
import datetime
connect('mongo_engine_learn')
class Post(Document):
title = StringField(required=True, max_length=200)
content = IntField(required=True)
author = StringField(required=True, max_length=50)
published = DateTimeField(default=datetime.datetime.now)
buyi_user = Post.objects(title='buyi')
print(type(buyi_user[0]))
print(buyi_user[0].author)
all_obj = Post.objects.all()
print(all_obj)
- 批量写入数据以供查询操作
for i in range(3, 10):
post_obj = Post(
title='buyi%s' % i,
content=str(i),
author='c%s' % i
)
post_obj.save()
- 查询所有操作
obj_all = Post.objects.all()
for i in obj_all:
print(i.content)
# 1 2 3 4 5 6 7 8 9
- 查询 content大于等于3 小于10 的数据,按照title的正序
from mongoengine import *
import datetime
connect('mongo_engine_learn')
class Post(Document):
title = StringField(required=True, max_length=200)
content = IntField(required=True)
author = StringField(required=True, max_length=50)
published = DateTimeField(default=datetime.datetime.now)
search_objects = Post.objects(content__gte=3, content__lt=10).order_by('-title')
for i in search_objects:
print(i.content)
- 倒序
search_objects = Post.objects(content__gte=3, content__lt=10).order_by('-title')
for i in search_objects:
print(i.content)
- 查询自加10操作
from mongoengine import *
import datetime
connect('mongo_engine_learn')
class Post(Document):
title = StringField(required=True, max_length=200)
content = IntField(required=True)
author = StringField(required=True, max_length=50)
published = DateTimeField(default=datetime.datetime.now)
search = Post.objects(author='c6').update(inc__content=10)
search1 = Post.objects(author='c6').first()
print(search1.content)
# 16
- 设置值操作
search = Post.objects(author='c6').update(set__content=666)
search1 = Post.objects(author='c6').first()
print(search1.content)
- 根据对象修改
search_obj = Post.objects(author='c6')first()
search_obj.content = 777
search_obj.save()
search1 = Post.objects(author='c6').first()
print(search1.content)
4、mongoengine 的性能影响
mongoengine 可以理解为对pymongo的封装,跟pymongo比,它最大的消耗在 从pymongo查询的结果,转换为Document实例, 这确实很费资源
mongoengine 在文档实例save的时候,会调用validate来验证每一个field, 这步没有必要,比较耗时, 可以通过传参来停止校验save(validate=False),这种情况下必须保证你修改和存储的数据正确
mongoengin 不支持连表操作,当多表查询时要适当减少数据库连接次数以提高性能