SGI STL的二级空间配置器的源码剖析并内存池的实现源码剖析
剖析源码的好处:学习优秀的编程规范 和 设计理念;以及剖析源码的能力。
2019年8月16日23:41:07
文章目录
- 剖析源码的好处:学习优秀的编程规范 和 设计理念;以及剖析源码的能力。
- 1 两个内存池的实现
- 2 SGI STL二级空间配置器
- 2.1 C++ STL和SGI STL的一点区别
- 2.2 SGI STL二级空间配置器allocator
- 2.3 SGI STL二级空间配置器allocator 内存池管理函数
- 2.3.1 static void* allocate(size_t __n) 函数:
- 2.3.2 _S_refill函数
- 2.3.3 _S_chunk_alloc函数 正常情况下的分配情况
- 2.3.4 deallocate 内存释放函数
- 2.3.5 chunk块、_S_chunk_alloc 函数的其他情况处理:
- 需求1:8字节的 前20个chunk块用完,还要分配
- 需求2:8字节的 后20个chunk块用完了,还要分配
- 需求3:8字节的 前20个chunk块用完.但是要分配16字节的chunk块
- 需求4:8字节的 前20个chunk块用完.但是要分配128字节的chunk块
- 2.3.6 _S_chunk_alloc函数的其他情况
- 需求5 在备用内存32字节上,申请40字节的chunk块
- 需求6 :由malloc进行开辟,40字节对应的内存池 但是开辟失败
- 需求7: 但是开辟失败。且找遍了其他元素位,没有空闲块
- 2.3.7 malloc再次失败 处理需求7
- 2.3.8 reallocate函数 内存扩容和减容的源码剖析
1 两个内存池的实现
内容如下:
- SGI STL二级空间配置器源码
- Nginx内存池源码剖析
- 这两种内存池的实现和应用场景都是不一样的。
为什么要内存池呢?
答:C语言的库函数malloc和free C++的new和delete(其底层的内存管理上依旧是malloc和free)。但是在应用场景中,涉及到短时间内 大量的小块内存的开辟和释放:但是malloc和free真正在实现起来的时候 还是比较麻烦的。因此在这种情况:小块内存的频繁 开辟释放使用malloc和free在程序的内存管理上效率就比较的低了,系统的性能就会受到影响。
因此对于短时间内 大量的小块内存的开辟和释放,使用内存池的方式就会好很多。
2 SGI STL二级空间配置器
2.1 C++ STL和SGI STL的一点区别
C++的标准模板库为STL:是可以在任何平台下的任何C++编译器都会被包含在系统当中的,然后#include 头文件其实就可以直接使用了。而SGI STL属于一个优秀的第三方STL:但是里面也都是包含了 一个STL该有的组件。如容器、iterator、泛型算法、函数对象等。
在C++ STL里面的空间配置器 可以详见我的博客:https://blog.csdn.net/weixin_43949535/article/details/95044072#_allocator_508


其模板类型参数:
template
- Tp是实例化容器底层的元素类型
- 其容器空间配置器也是有个默认值的
看一下SGI STL里面的vector的push_back 和 pop_back操作。
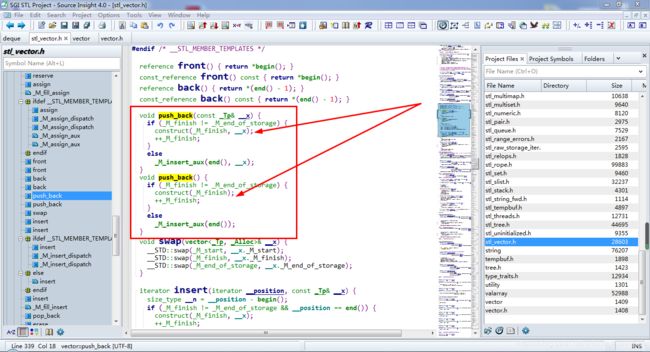
push_back在容器的已经开辟好的内存上,构造一个对象出来。但是上面的两个并没有通过容器的空间配置器,来进行construct 和 destroy。这两个construct 和 destroy是全局的
但是在C++ STL里面:四种操作都是通过容器的allocator来完成的(allocator封装了这4个方法)。如上图所示:对象的构造使用的是一个construct函数,这相当于是一个全局的模板函数,而在其(如上图所示:)底层调用的还是定位 new。这个定位new,在指针指定的内存空间上构造一个值为value的对象。其实这和C++ STL里面的allocator的construct做的事情是一样的。也就是说:在SGI STL里面,对象的构造并没有通过空间配置器,还是由全局的模板函数实现的。

pop_back如上:使用的也是全局的destroy函数,如下: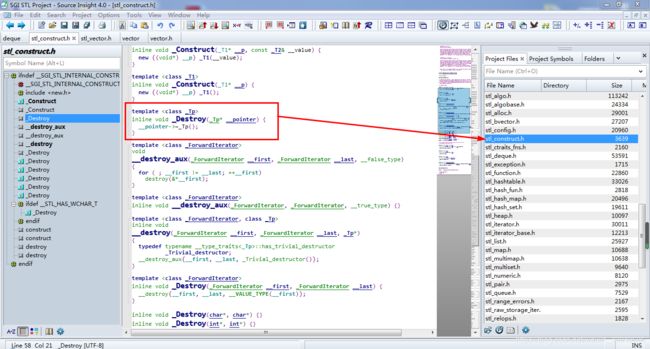
其底层做的还是 通过传入的指针调用相应对象的析构函数的(因为这里做的也仅仅是容器不要的对象的析构,而不是去释放内存:这个内存是容器的内存。以后还是要用的,所以不能直接用delete)。
总结:从上面可以看到SGI STL的容器:如下

那也就是说:SGI STL里面的allocator只剩下allocate 和 deallocate。SGI STL包含了一级空间配置器和二级空间配置器,其中一级空间配置器allocator采用malloc和free来管理内存,和C++标准库中提供的allocator是一样的,但其二级空间配置器allocator采用了基于freelist自由链表原理的内存池机制实现内存管理。
如下:
咱们现在就看一下 其模板类型参数的第二个参数:空间配置器
template <class _Tp, class _Alloc = __STL_DEFAULT_ALLOCATOR(_Tp) >
alloc是给定了一个默认的宏定义__STL_DEFAULT_ALLOCATOR,把实例化容器的元素类型作为实参传入其中。宏定义的地方如下:

# ifndef __STL_DEFAULT_ALLOCATOR
# ifdef __STL_USE_STD_ALLOCATORS
# define __STL_DEFAULT_ALLOCATOR(T) allocator< T >
# else
# define __STL_DEFAULT_ALLOCATOR(T) alloc
# endif
# endif
那个负责控制的宏__STL_USE_STD_ALLOCATORS:使用标准的allocator(这个就和C++ STL里面实现的就一样了)。
allocator() __STL_NOTHROW {}
allocator(const allocator&) __STL_NOTHROW {}
template <class _Tp1> allocator(const allocator<_Tp1>&) __STL_NOTHROW {}
~allocator() __STL_NOTHROW {}
pointer address(reference __x) const { return &__x; }
const_pointer address(const_reference __x) const { return &__x; }
// __n is permitted to be 0. The C++ standard says nothing about what
// the return value is when __n == 0.
_Tp* allocate(size_type __n, const void* = 0) {
return __n != 0 ? static_cast<_Tp*>(_Alloc::allocate(__n * sizeof(_Tp)))
: 0;
}
// __p is not permitted to be a null pointer.
void deallocate(pointer __p, size_type __n)
{ _Alloc::deallocate(__p, __n * sizeof(_Tp)); }
size_type max_size() const __STL_NOTHROW
{ return size_t(-1) / sizeof(_Tp); }
void construct(pointer __p, const _Tp& __val) { new(__p) _Tp(__val); }
void destroy(pointer __p) { __p->~_Tp(); }
};
上面的_Tp* allocate 调用的是_Alloc::allocate;void deallocate调用的是 _Alloc::deallocate 。而_Alloc是alloc的别名。
typedef alloc _Alloc; // The underlying allocator.
而其construct 和 destroy时直接用定位new、指针调用对象析构函数。那这里面使用的就和标准库里面的allocator是一样的。
现在再来看一下:_Alloc::allocate和_Alloc::deallocate 其底层使用的也是malloc和free了。
而这个alloc是malloc_alloc的别名:

而这个malloc_alloc,就是:
也就是:
其底层使用的就是:malloc和 free。
以上就是其 一级空间配置器的实现了,类似于C++ STL的空间配置器。
若是没有这个宏:__STL_USE_STD_ALLOCATORS,那么就使用的是二级空间配置器。

那么这个alloc就是:
于是:SGI STL默认应用的就是这个 二级空间配置器。其第一个参数:节点分配线程是否支持线程安全__NODE_ALLOCATOR_THREADS是
如果是:有这个宏__STL_THREADS 那么就是说这个基于内存池实现的二级空间配置器是一个线程安全的,可以直接使用在多线程的环境下。(而C++ STL里面的容器 空间配置器等都不是线程安全的操作)
2.2 SGI STL二级空间配置器allocator
SGI STL包含了一级空间配置器和二级空间配置器,其中一级空间配置器allocator采用malloc和free来管理内存,和C++标准库中提供的allocator是一样的,但其二级空间配置器allocator采用了基于freelist自由链表原理的内存池机制实现内存管理。
template <class _Tp, class _Alloc = __STL_DEFAULT_ALLOCATOR(_Tp) >
class vector : protected _Vector_base<_Tp, _Alloc>
可以看到,容器的默认空间配置器是__STL_DEFAULT_ALLOCATOR( _Tp),它是一个宏定义,如下:
# ifndef __STL_DEFAULT_ALLOCATOR
# ifdef __STL_USE_STD_ALLOCATORS
# define __STL_DEFAULT_ALLOCATOR(T) allocator< T >
# else
# define __STL_DEFAULT_ALLOCATOR(T) alloc
# endif
# endif
从上面可以看到__STL_DEFAULT_ALLOCATOR通过宏控制有两种实现,一种是allocator< T >,另一种是alloc,这两种分别就是SGI STL的一级空间配置器和二级空间配置器的实现。
template <int __inst>
class __malloc_alloc_template//一级空间配置器内存管理类--通过malloc和free管理内存
template <bool threads, int inst>
class __default_alloc_template { // 二级空间配置器内存管理类 --
//通过自定义内存池实现内存管理
二级空间配置器如下:

template <bool threads, int inst>
class __default_alloc_template {
这两个参数都是模板非类型参数:第一个 是否支持线程安全。
以下就是这个 二级空间配置器的一些重要类型和定义:

// 内存池的粒度信息
enum {_ALIGN = 8};
enum {_MAX_BYTES = 128};
enum {_NFREELISTS = 16};
上面的这3个枚举:以8字节对齐、最大字节数128字节、自由链表的个数是16个。也即:这个二级空间配置器的内存池的操作实现:下面是一个数组空间,16个元素(每一个数组元素下面挂的都是一个自由链表)。而且这个自由链表上的节点的大小是和上面数组的这一个元素标识的大小是一致的。(也就是上 这几串自由链表上 节点的大小都是和静态链表:数组的 这个位置的标识大小一样的,最大也就128字节)。

注:若是大于128字节,则就表示 是大内存块,由一级空间配置器进行开辟 释放吧。
每一个节点块的头信息:

// 每一个内存chunk块的头信息
union _Obj {
union _Obj* _M_free_list_link;
char _M_client_data[1]; /* The client sees this. */
};
如上:_M_free_list_link可以视为:节点的next域。通过静态链表的方式,实现的自由链表。
注:动态链表的每一个节点都是单独new出来的,节点之间不是连续的;而静态链表:所有的节点内存都是连续的。
组织所有自由链表的数组 如下:
// 组织所有自由链表的数组,数组的每一个元素的类型是_Obj*,全部初始化为0
static _Obj* __STL_VOLATILE _S_free_list[_NFREELISTS];
在多线程环境中,静态的指针数组是在数据段上。前面加上volatile,防止多线程对这个数组进行缓存,而导致一个线程对其进行修改,而其他线程无法及时看到。(因此在多线程环境下,堆上和数据段都会加上volatile,防止线程缓存 而导致的多个线程看到的数据版本不一致,无法及时看到其他线程对这个共享内存的修改。)_S_free_list就是这个数组的数组名,元素个数16.数组的每一个元素,都是一个个的Obj * 。如上 这个静态的成员变量 其初始化在:
全都是初始化为0 标志16 个元素obj *,现在全部都是初始化为空。
下面是3个非常重要的记录:chunk块的分配情况
// Chunk allocation state. 记录内存chunk块的分配情况
static char* _S_start_free;//起始的内存
static char* _S_end_free;//末尾的内存
static size_t _S_heap_size;//堆的大小
//3个静态成员变量的初始化
template <bool __threads, int __inst>
char* __default_alloc_template<__threads, __inst>::_S_start_free = 0;
template <bool __threads, int __inst>
char* __default_alloc_template<__threads, __inst>::_S_end_free = 0;
template <bool __threads, int __inst>
size_t __default_alloc_template<__threads, __inst>::_S_heap_size = 0;
下面是2个重要的辅助接口函数
字节对齐函数 和 返回自由链表索引函数。
/*将 __bytes 上调至最邻近的 8 的倍数*/
static size_t _S_round_up(size_t __bytes)
{ return (((__bytes) + (size_t) _ALIGN-1) & ~((size_t) _ALIGN - 1)); }
/*返回 __bytes 大小的chunk块位于 free-list 中的编号*/
static size_t _S_freelist_index(size_t __bytes) {
return (((__bytes) + (size_t)_ALIGN-1)/(size_t)_ALIGN - 1); }

如上图所示:字节对齐函数的作用:在容器去放元素的时候,是需要内存的。然后由空间配置器进行开辟内存,这个字节的大小是得经过_S_round_up函数 上调调整一下的(容器里面需要的空间进行上调,接近到最小的8的倍数 进行对齐)。这个二级空间配置器 在小于128字节的内存开辟都是通过从内存池里面分配的。
- 首先_ALIGN进行了一个类型强转:将_ALIGN转为 无符号整型。unsigned int 这是一个4字节的。
- 先强转,完了-1 接下来是按位取反 如下:

- 上面这么做的目的就是:申请的字节1到8 则统一处理为8;9到16 统一处理为16 等等
- 当上面的_bytes为0的时候,那么就直接是上面的那两行 为0
- 当申请字节为 1到8时,则第一行 肯定会产生进位直接就成了 如下:


7. 此时要是申请 9个字节 就如下:9 到 16都是16
8.
9. 

这个函数_S_freelist_index :在基于自由链表的内存池中,当想申请内存 或者 归还内存 的时候 得确定是从这个数组的 那个位置来取得内存块。(或者说 这个内存块应该对应于这个数组的哪个内存位。)_bytes + 7字节,然后除以8 就可以准确地的定位数组的哪个元素位(自由链表数组的下标)。
2.3 SGI STL二级空间配置器allocator 内存池管理函数
// 分配内存的入口函数
static void* allocate(size_t __n)
// 负责把分配好的chunk块进行连接,添加到自由链表当中
static void* _S_refill(size_t __n);
// 分配相应内存字节大小的chunk块,并且给下面三个成员变量初始化
static char* _S_chunk_alloc(size_t __size, int& __nobjs);
// 把chunk块归还到内存池
static void deallocate(void* __p, size_t __n);
// 内存池扩容函数
template <bool threads, int inst>
void*__default_alloc_template<threads, inst>::
reallocate(void* __p,size_t __old_sz,size_t __new_sz);
2.3.1 static void* allocate(size_t __n) 函数:
负责开辟内存的
/* __n must be > 0 */
static void* allocate(size_t __n)
{
void* __ret = 0;//返回值 初始化为0
if (__n > (size_t) _MAX_BYTES) {//希望开辟_n个字节
__ret = malloc_alloc::allocate(__n);//大于 128字节
}
else {
_Obj* __STL_VOLATILE* __my_free_list
= _S_free_list + _S_freelist_index(__n);
// Acquire the lock here with a constructor call.
// This ensures that it is released in exit or during stack
// unwinding.
# ifndef _NOTHREADS
/*REFERENCED*/
_Lock __lock_instance;
# endif
_Obj* __RESTRICT __result = *__my_free_list;
if (__result == 0)
__ret = _S_refill(_S_round_up(__n));
else {
*__my_free_list = __result -> _M_free_list_link;
__ret = __result;
}
}
return __ret;
};
大于128字节:则要使用malloc_alloc::allocate字节了(一级空间配置器);小于等于 则是通过内存池的方式进行。
定义的__my_free_list这个局部变量(二级指针:Obj * *):是由自由链表的数组数组名_S_free_list+_S_freelist_index(__n)进行相加得来的。_S_freelist_index(__n)传入需要开辟的字节数,来确定是从这个数组的 哪个位置来取得内存块。(或者说 这个内存块应该对应于这个数组的哪个内存位。)_bytes + 7字节,然后除以8 就可以准确地的定位数组的哪个元素位(自由链表数组的下标)。
这样数组名+一个确定的自由链表数组的下标,那么就可以 准确的定位到 这个数组的这个确定的元素位。假如此刻要申请的是14个字节,(14+7) / 8 -1=1 。于是__my_free_list二级指针就指向了数组中 16这个元素位的地址。如下:
然后 接下来 :_Lock __lock_instance;

其构造函数 加锁,析构函数进行解锁。这句话利用:栈上对象出作用域自动析构的特点,进行加锁 解锁操作。因为
_Obj* __RESTRICT __result = *__my_free_list;
if (__result == 0)
__ret = _S_refill(_S_round_up(__n));
else {
*__my_free_list = __result -> _M_free_list_link;
__ret = __result;
}
这段代码 就是临界区代码段(这里的自由链表的增删改不是一个线程安全的操作)。在多线程环境下,自由链表的增删改等是需要锁控制来 保证其线程安全操作的。SGI STL的二级空间配置器的内存池的管理是一个线程安全的操作。
这里定义的__result 是对__my_free_list的解引用的。此时__result的值就是 数组16 那个元素位里面的值(元素的类型都是Obj *)。刚才我们初始化这个数组的时候,是全赋0的(没有给这个16元素位下面 分配chunk块)。于是就会有了下面的判断。
首先最开始的时候,肯定是0.然后就得去16元素位下面 分配一个16字节的chunk块。就如下图所示:
这个一长链 就是一个静态链表。是0.然后就得去16元素位下面 分配一个16字节的chunk块。让ret指向这个chunk块,然后最后就把ret进行了 返回。如果16字节下面的chunk块不为空,那么
*__my_free_list = __result -> _M_free_list_link;
__ret = __result;
做的就是:因为result不为0 它就指向了一个存在的chunk块。第一句 :把result指向的当前节点的next域 下一个节点的地址给到 * __my_free_list(__my_free_list这个二级指针是指向了数组中 16这个元素位的地址 )。意思就是: * __my_free_list是存放的是 下面自由链表的第一个chunk块地址,现在要把这个当前chunk块拿走,所以说 * __my_free_list 里面需要放上当前chunk块的后继chunk块的地址。
首先:二级指针__my_free_list用来 遍历这个指针数组。根据申请分配的内存大小,定位到相应的数组的某个元素位。先对__my_free_list指针进行解引用,获取其值 给到result。然后在其下面判断有无 chunk块,(判断result这个 Obj * 是否为空)。为0,则分配一个chunk块 给到ret。result的指向不为空,则将这个当前chunk块的下一个块的地址 给到 * __my_free_list。然后就可以把这个自由链表的第一个chunk块地址给返回了。
2.3.2 _S_refill函数
上节的allocate 函数(空间配置器负责给容器底层开辟内存的入口函数)如下:
/* __n must be > 0 */
static void* allocate(size_t __n)
{
void* __ret = 0;
if (__n > (size_t) _MAX_BYTES) {
__ret = malloc_alloc::allocate(__n);
}
else {
_Obj* __STL_VOLATILE* __my_free_list
= _S_free_list + _S_freelist_index(__n);
// Acquire the lock here with a constructor call.
// This ensures that it is released in exit or during stack
// unwinding.
# ifndef _NOTHREADS
/*REFERENCED*/
_Lock __lock_instance;//考虑的是 线程安全
# endif
_Obj* __RESTRICT __result = *__my_free_list;
if (__result == 0)//内存池没有 chunk块。
__ret = _S_refill(_S_round_up(__n));//分配chunk块的
else {
*__my_free_list = __result -> _M_free_list_link;
__ret = __result;
}
}
return __ret;//最后从内存池 返回申请的这个chunk块
};
本节重点:研究一下 在result 为0的时候,执行的_S_refill函数的操作是什么?
在数组某个元素位 里面的值(Obj * 放的是第一个chunk块的地址)为0的时候,要分配相应字节大小的chunk 块。其参数:_S_round_up(__n) 是将 __bytes (申请内存的大小)上调至最邻近的 8 的倍数。
源码如下:(看大佬们写的代码,简直就是一种特么的享受!!!)
/* Returns an object of size __n, and optionally adds to size __n free list.*/
/* We assume that __n is properly aligned. */
/* We hold the allocation lock. */
template <bool __threads, int __inst>
void*
__default_alloc_template<__threads, __inst>::_S_refill(size_t __n)
{
int __nobjs = 20;//节点的个数
char* __chunk = _S_chunk_alloc(__n, __nobjs);
_Obj* __STL_VOLATILE* __my_free_list;
_Obj* __result;
_Obj* __current_obj;
_Obj* __next_obj;
int __i;
if (1 == __nobjs) return(__chunk);
__my_free_list = _S_free_list + _S_freelist_index(__n);
/* Build free list in chunk */
__result = (_Obj*)__chunk;
*__my_free_list = __next_obj = (_Obj*)(__chunk + __n);
for (__i = 1; ; __i++) {
__current_obj = __next_obj;
__next_obj = (_Obj*)((char*)__next_obj + __n);
if (__nobjs - 1 == __i) {
__current_obj -> _M_free_list_link = 0;
break;
} else {
__current_obj -> _M_free_list_link = __next_obj;
}
}
return(__result);
}
如图所示:假如此刻要给8字节的元素位 开辟一个chunk串(自由链表),现在情况如下:内存池为空的

这里的那个_S_chunk_alloc(__n, __nobjs);函数如下:比较复杂,其作用就是:按照数组的某个元素位的字节个数,比如这里的8 来开辟相应字节的chunk块。(每个chunk块类型 都是一个union类型)。
_S_refill函数的每一句源码解释如下:
开辟完内存之后,就会把这块内存池的起始地址返回回来 由__chunk指针进行接收。定义的二级指针__my_free_list 就是用来遍历这个 第一维数组的(这是一个指针类型的数组,所以需要一个二级指针进行遍历)。__nobjs这个变量的值,通过一个引用 传入到下面的_S_chunk_alloc函数里面了,然后在里面进行了修改。如果__nobjs等于1,说明这个8字节的内存池就剩下一个chunk块了。直接返回即可(毕竟此时__chunk指向的是 现在相应字节的可用的chunk块内存池的起始地址)。
__my_free_list = _S_free_list + _S_freelist_index(__n);
数组的起始地址+数组的某个下标
这句话的作用就是:让__my_free_list指针指向了 数组的某一个元素位(下标)的地址。
__result = (_Obj*)__chunk;
上面这句话的意思:把__chunk强转为Obj*类型,然后赋值给__result。现在的情况如下:
现在__result和__chunk都指向了 这个chunk块内存池的起始地址(如上)。
*__my_free_list = __next_obj = (_Obj*)(__chunk + __n);
上一句的作用就是:__chunk指向的是 这个chunk块内存池的起始地址,加上一个n。此时的这个n经过_S_round_up(__n) 把字节对齐,然后传入_S_refill函数。在_S_refill函数里面,已经是8了。(这里我们用的是 第0号下标的元素位),于是此时的__n就是8 。而chunk是char * 的类型,__chunk + __n就是走了8字节。然后类型强转为Obj * 就是上面的union的。并把指针的值都赋给__next_obj和 *__my_free_list 。
之所以上面要用result去记录一下,是因为 我们这里要申请一个chunk块。这个result指向的chunk块就是将要分配出去的那个。此时的chunk指向的就是下一个chunk块了。又因为刚才做了类型强转,赋给__next_obj。__my_free_list原来指向的是数组的第0号元素位,现对其进行解引用,然后还赋值。意思就是:把__next_obj指针的值 直接放在了 第0号元素位里面了,第0号元素位里面的Obj * 指向了刚开辟的整个chunk块内存池的第1号块的内存的起始地址。如下:
_S_refill函数的那个for循环做的就是:每个节点的那个_M_free_list_link指针(存的是下一个节点的地址)的指向,也是在这个函数里面做的。在for循环里面:
__current_obj = __next_obj;
__next_obj = (_Obj*)((char*)__next_obj + __n);
if (__nobjs - 1 == __i)
{
__current_obj -> _M_free_list_link = 0;
break;
}
else
{
__current_obj -> _M_free_list_link = __next_obj;
}
__next_obj先转成 char * ,就可以直接进行加上_n个整数,进行字节的移动(__next_obj偏移了8字节),现在__next_obj指向了下一个chunk块的地址。不可以直接加,__next_obj的类型是Obj * ,而Obj类型是一个联合体。一个char * 一个char 数组,所以这个类型定义的变量的内存大小不是8字节。此处:需要的是走动一个chunk块,这是按字节进行的偏移,所以需要转成char * 。然后又类型强转Obj * 之后又赋值给__next_obj。
接下来 i的初值是1,__nobjs这里的初值是20 。每处理一个节点 i都会++。当__nobjs - 1 == __i成立的时候,最后一个节点的_M_free_list_link置为0 。即: __current_obj -> _M_free_list_link = 0,最后跳出循环。那么这个不成立的时候做的事情就是:__current_obj -> _M_free_list_link = __next_obj;**当前节点的头部指针指向的是下一个节点的地址。这就相当于把这么多的chunk块进行了一个串起来操作。**如下:

因此总结:_S_refill函数做了两件事情:
(1)调用_S_chunk_alloc,负责分配相应字节大小的chunk块内存池的内存
(2)_S_refill函数的那个for循环做的就是:每个节点的那个_M_free_list_link指针(存的是下一个节点的地址)的指向,也是在这个函数里面做的。连接起来之后,形成一个静态链表:虽然总的内存是按照数组的形式分配的,节点之间的内存都是连续的。但是做成了静态链表:每个节点的头部 _M_free_list_link指针存放的是下一个节点的地址。
这个_S_refill函数结束之后,把result返回。这是外面函数要的那个chunk块地址。
2.3.3 _S_chunk_alloc函数 正常情况下的分配情况
/* We allocate memory in large chunks in order to avoid fragmenting */
/* the malloc heap too much. */
/* We assume that size is properly aligned. */
/* We hold the allocation lock. */
template <bool __threads, int __inst>
char*
__default_alloc_template<__threads, __inst>::_S_chunk_alloc(size_t __size,
int& __nobjs)
{
char* __result;
size_t __total_bytes = __size * __nobjs;//内存池需要 总的字节数 也就是20个节点
size_t __bytes_left = _S_end_free - _S_start_free;
if (__bytes_left >= __total_bytes) {
__result = _S_start_free;
_S_start_free += __total_bytes;
return(__result);
} else if (__bytes_left >= __size) {
__nobjs = (int)(__bytes_left/__size);
__total_bytes = __size * __nobjs;
__result = _S_start_free;
_S_start_free += __total_bytes;
return(__result);
} else {
size_t __bytes_to_get =
2 * __total_bytes + _S_round_up(_S_heap_size >> 4);
// Try to make use of the left-over piece.
if (__bytes_left > 0) {
_Obj* __STL_VOLATILE* __my_free_list =
_S_free_list + _S_freelist_index(__bytes_left);
((_Obj*)_S_start_free) -> _M_free_list_link = *__my_free_list;
*__my_free_list = (_Obj*)_S_start_free;
}
_S_start_free = (char*)malloc(__bytes_to_get);
if (0 == _S_start_free) {
size_t __i;
_Obj* __STL_VOLATILE* __my_free_list;
_Obj* __p;
// Try to make do with what we have. That can't
// hurt. We do not try smaller requests, since that tends
// to result in disaster on multi-process machines.
for (__i = __size;
__i <= (size_t) _MAX_BYTES;
__i += (size_t) _ALIGN) {
__my_free_list = _S_free_list + _S_freelist_index(__i);
__p = *__my_free_list;
if (0 != __p) {
*__my_free_list = __p -> _M_free_list_link;
_S_start_free = (char*)__p;
_S_end_free = _S_start_free + __i;
return(_S_chunk_alloc(__size, __nobjs));
// Any leftover piece will eventually make it to the
// right free list.
}
}
_S_end_free = 0; // In case of exception.
_S_start_free = (char*)malloc_alloc::allocate(__bytes_to_get);
// This should either throw an
// exception or remedy the situation. Thus we assume it
// succeeded.
}
_S_heap_size += __bytes_to_get;
_S_end_free = _S_start_free + __bytes_to_get;
return(_S_chunk_alloc(__size, __nobjs));
}
}
内存块的分配:
接收两个参数_S_chunk_alloc(size_t __size, int& __nobjs)
size是要分配的字节数,__nobjs是要分配chunk块的个数。__nobjs传递的是引用:在这个函数里面,修改这个引用变量的时候 就把实参的值修改掉了。_S_chunk_alloc函数分配完成之后,把分配内存池的起始地址进行了返回。
举例:这里以传入的chunk块为8字节,开辟的个数为20 进行讨论
size_t __bytes_left = _S_end_free - _S_start_free;
剩余的字节数:在最开始的时候,二级空间配置器类里面的静态的成员变量_S_end_free _S_start_free和_S_heap_size的初值都设定的是0。所以这里的差值为0
所以直接进入 else的作用域内:_S_heap_size 还是0
size_t __bytes_to_get = 2 * __total_bytes + _S_round_up(_S_heap_size >> 4);
此时的__bytes_to_get 的值 就是320字节。40个 chunk块。
于是接下来只能执行的就是:_S_start_free = (char*)malloc(__bytes_to_get);那么这个也就相当于对于 8字节的元素位来说:开辟了40个chunk块。并把这个内存块的起始地址 赋给 静态变量_S_start_free 。
接下来:暂时不讨论 内存开辟失败的情况:__bytes_to_get的值现在是320字节
_S_heap_size += __bytes_to_get;
_S_end_free = _S_start_free + __bytes_to_get;
return(_S_chunk_alloc(__size, __nobjs));

在 return的时候:return(_S_chunk_alloc(__size, __nobjs));递归调用,接下来如下:
因为刚开始 相应字节大小的chunk块就没有,于是就开始给相应数组元素位上分配chunk块内存池。接下来就可以给调用方 返回一个chunk块了。重新走一下_S_chunk_alloc函数: 相应字节大小的chunk块内存池已经分配好了。__bytes_left 就是320字节,然后320 > 160,所以执行如下:
__result = _S_start_free;
_S_start_free += __total_bytes;
return(__result);
把第一个chunk块 分配出去,先由result进行指向。__total_bytes此时是 160字节 。此时上下都有20个chunk块 。接下来把result进行返回 如下:

但是这仅仅只是完成了调用方_S_refill 对_S_chunk_alloc的调用,成功的得到了一个chunk块。然后就又回到_S_refill函数的执行了。
此时再进行chunk块的分配就方便很多了:

此时将会执行到else
if (__result == 0)//内存池没有 chunk块。
__ret = _S_refill(_S_round_up(__n));//分配chunk块的
else {
*__my_free_list = __result -> _M_free_list_link;
__ret = __result;
}
此时的_result指向的是第 1 号chunk块(第0号的已经被分配出去了),然后又相当于把第 2 个chunk块的地址写入到了 数组8字节 元素位里面了。前面两个都被分配出去了,此时再进行__ret = __result;和return ret;
直到分配最后一个节点的时候:最后一个节点的头(第 19 号元素)的next域是 0 。则再调用allocate的时候,result就成了 空。
这是正常流程下的 allocate的调用。
2.3.4 deallocate 内存释放函数

正常情况下的 chunk块的归还:
指针是指归还的chunk块的内存的起始地址,_n是要归还的chunk块的字节数。大于128字节,因在分配的时候 就采用的是malloc分配的。所以在这里 释放的时候,也是通过free进行的释放。
小于等于128字节的chunk块,则是从内存池分配出去的。归还的时候,也应该归还到 相应字节的元素号的 自由链表 或者 chunk块的内存池当中。
- 首先做的就是 定位数组的某一个 元素号的地址:指针数组的起始地址+数组定位的下标
- 然后类型强转,转成Obj指针 由_q指向_p的这个内存
- 假如此时前两个chunk块的都被 分配出去了,数组的第0号 元素位里面存放的是 这个内存池的第 2 号元素的起始地址。现在要把一个chunk块归还进来,因为要改变 静态链表了,所以需要保证线程安全。(构造函数进行加锁,出了作用域进行解锁)。做的无非就是如下:

- 如上图所示:先对 my_free_list进行解引用,就是数组第 0 号元素的值(也即 这个内存池的第2号chunk块的地址)给定我现在要 归还的chunk块的next域(M_free_list_link域),然后把这个要归还的chunk块的地址 给到* my_free_list,也即数组第 0 号元素的值。
- 也就是做了一次 头插法。如下:

- 于是下一次 需要从这个内存池里面再分配出去一个 chunk块的时候 ,还是首先取找 数组这个对应字节的元素位,取出其第一个 空闲的chunk块,也就还是 刚别人归还的这个,又被分配出去了。
- 假如说 在归还完 第0个chunk块,之后又要归还第 1 个chunk块的话。如下:在第 1 号chunk块的next指针域里面记录,第0 号chunk块的地址,然后把这个要归还的chunk块的内存地址 给到* my_free_list,也即数组第 0 号元素的值。
- 相当于把一个要归还的节点插入到静态链表当中,然后由数组的这个对应字节大小的 元素位里面的值 来存放当前内存池的第一个空闲chunk块的地址。

其实这个和 之前写的new 与 delete运算符重载写的那个 对象池逻辑上是一样的。都是使用一个静态链表,对于节点的分配、归还 用一个指针把所有节点串在一起。
这个可以参见我的博客:https://blog.csdn.net/weixin_43949535/article/details/95167431#newdelete_2005
2.3.5 chunk块、_S_chunk_alloc 函数的其他情况处理:
_S_chunk_alloc函数源代码如下:
/* We allocate memory in large chunks in order to avoid fragmenting */
/* the malloc heap too much. */
/* We assume that size is properly aligned. */
/* We hold the allocation lock. */
template <bool __threads, int __inst>
char*
__default_alloc_template<__threads, __inst>::_S_chunk_alloc(size_t __size,
int& __nobjs)
{
char* __result;
size_t __total_bytes = __size * __nobjs;
size_t __bytes_left = _S_end_free - _S_start_free;
if (__bytes_left >= __total_bytes) {
__result = _S_start_free;
_S_start_free += __total_bytes;
return(__result);
} else if (__bytes_left >= __size) {
__nobjs = (int)(__bytes_left/__size);
__total_bytes = __size * __nobjs;
__result = _S_start_free;
_S_start_free += __total_bytes;
return(__result);
} else {
size_t __bytes_to_get =
2 * __total_bytes + _S_round_up(_S_heap_size >> 4);
// Try to make use of the left-over piece.
if (__bytes_left > 0) {
_Obj* __STL_VOLATILE* __my_free_list =
_S_free_list + _S_freelist_index(__bytes_left);
((_Obj*)_S_start_free) -> _M_free_list_link = *__my_free_list;
*__my_free_list = (_Obj*)_S_start_free;
}
_S_start_free = (char*)malloc(__bytes_to_get);
if (0 == _S_start_free) {
size_t __i;
_Obj* __STL_VOLATILE* __my_free_list;
_Obj* __p;
// Try to make do with what we have. That can't
// hurt. We do not try smaller requests, since that tends
// to result in disaster on multi-process machines.
for (__i = __size;
__i <= (size_t) _MAX_BYTES;
__i += (size_t) _ALIGN) {
__my_free_list = _S_free_list + _S_freelist_index(__i);
__p = *__my_free_list;
if (0 != __p) {
*__my_free_list = __p -> _M_free_list_link;
_S_start_free = (char*)__p;
_S_end_free = _S_start_free + __i;
return(_S_chunk_alloc(__size, __nobjs));
// Any leftover piece will eventually make it to the
// right free list.
}
}
_S_end_free = 0; // In case of exception.
_S_start_free = (char*)malloc_alloc::allocate(__bytes_to_get);
// This should either throw an
// exception or remedy the situation. Thus we assume it
// succeeded.
}
_S_heap_size += __bytes_to_get;
_S_end_free = _S_start_free + __bytes_to_get;
return(_S_chunk_alloc(__size, __nobjs));
}
}
上节课回顾:如果当前 数组的某个元素位(这个字节假定为8 字节)没有分配过chunk块内存池,那么先行计算size_t __total_bytes = __size * __nobjs;__total_bytes 也就是160字节。然后因为没有分配给chunk块,所以__bytes_left 自然就是0 - 0 = 0 。接着进入下面的else,直接执行
size_t __bytes_to_get = 2 * __total_bytes + _S_round_up(_S_heap_size >> 4);计算__bytes_to_get =2 * __total_bytes 320字节,40个chunk块。然后就要去执行
_S_start_free = (char * )malloc(__bytes_to_get);进行资源分配。下面的if (0 == _S_start_free) 就是来判断内存开辟失败的情况,暂时不考虑。继续向下:
_S_heap_size += __bytes_to_get;
_S_end_free = _S_start_free + __bytes_to_get;
return(_S_chunk_alloc(__size, __nobjs));
_S_heap_size 自始至终一直在 往上加,没有减。_S_end_free 就是320字节。然后因为chunk块没有分配给外面,所以这里做的就是递归调用。再次进来之后:__bytes_left 就是320字节,于是就可以进入第一个if中,执行如下:
__result = _S_start_free;
_S_start_free += __total_bytes;
return(__result);
把前20个chunk块给使用起来了。
这个过程相当于 把前20个chunk块 使用起来了,后20个chunk块作为一个备用。这个所谓的备用:虽然现在这是20个 8字节的chunk块,共160字节 它还可以给其他字节(例如16 24等)的内存申请使用。
此时(把前20个chunk块给使用起来了),回头看一下allocate函数:
/* __n must be > 0 */
static void* allocate(size_t __n)
{
void* __ret = 0;
if (__n > (size_t) _MAX_BYTES) {
__ret = malloc_alloc::allocate(__n);
}
else {
_Obj* __STL_VOLATILE* __my_free_list
= _S_free_list + _S_freelist_index(__n);
// Acquire the lock here with a constructor call.
// This ensures that it is released in exit or during stack
// unwinding.
# ifndef _NOTHREADS
/*REFERENCED*/
_Lock __lock_instance;
# endif
_Obj* __RESTRICT __result = *__my_free_list;
if (__result == 0)
__ret = _S_refill(_S_round_up(__n));
else {
*__my_free_list = __result -> _M_free_list_link;
__ret = __result;
}
}
return __ret;
};
__result 把这个元素位上自由链表的第一个空闲chunk块的地址给保存起来了,当然不为0.于是如下:
*__my_free_list = __result -> _M_free_list_link;
__ret = __result;
指针后移,把chunk块地址 保存 之后进行return。(这是正常情况下的分配)
需求1:8字节的 前20个chunk块用完,还要分配
接下来,如果这20个chunk块分配完了,那么最后一个块的next域为空,它把空给了 *__my_free_list,于是8字节chunk块的数组元素位 成了一个nullptr。再去分配的话,__result == 0 于是进入_S_refill函数了
/* Returns an object of size __n, and optionally adds to size __n free list.*/
/* We assume that __n is properly aligned. */
/* We hold the allocation lock. */
template <bool __threads, int __inst>
void*
__default_alloc_template<__threads, __inst>::_S_refill(size_t __n)
{
int __nobjs = 20;
char* __chunk = _S_chunk_alloc(__n, __nobjs);
_Obj* __STL_VOLATILE* __my_free_list;
_Obj* __result;
_Obj* __current_obj;
_Obj* __next_obj;
int __i;
if (1 == __nobjs) return(__chunk);
__my_free_list = _S_free_list + _S_freelist_index(__n);
/* Build free list in chunk */
__result = (_Obj*)__chunk;
*__my_free_list = __next_obj = (_Obj*)(__chunk + __n);
for (__i = 1; ; __i++) {
__current_obj = __next_obj;
__next_obj = (_Obj*)((char*)__next_obj + __n);
if (__nobjs - 1 == __i) {
__current_obj -> _M_free_list_link = 0;
break;
} else {
__current_obj -> _M_free_list_link = __next_obj;
}
}
return(__result);
}
在_S_refill函数里面,调用了_S_chunk_alloc函数。于是我们在回到_S_chunk_alloc函数:
计算__total_bytes 还是160字节,但是此时__bytes_left 是160字节(如下:刚才分配还遗留下来20个chunk块。)于是就可以进入if (__bytes_left >= __total_bytes) ,两者相等
/* We allocate memory in large chunks in order to avoid fragmenting */
/* the malloc heap too much. */
/* We assume that size is properly aligned. */
/* We hold the allocation lock. */
template <bool __threads, int __inst>
char*
__default_alloc_template<__threads, __inst>::_S_chunk_alloc(size_t __size,
int& __nobjs)
{
char* __result;
size_t __total_bytes = __size * __nobjs;//内存池需要 总的字节数 也就是20个节点
size_t __bytes_left = _S_end_free - _S_start_free;
if (__bytes_left >= __total_bytes) {
__result = _S_start_free;
_S_start_free += __total_bytes;
return(__result);
} else if (__bytes_left >= __size) {
__nobjs = (int)(__bytes_left/__size);
__total_bytes = __size * __nobjs;
__result = _S_start_free;
_S_start_free += __total_bytes;
return(__result);
} else {
size_t __bytes_to_get =
2 * __total_bytes + _S_round_up(_S_heap_size >> 4);
// Try to make use of the left-over piece.
if (__bytes_left > 0) {
_Obj* __STL_VOLATILE* __my_free_list =
_S_free_list + _S_freelist_index(__bytes_left);
((_Obj*)_S_start_free) -> _M_free_list_link = *__my_free_list;
*__my_free_list = (_Obj*)_S_start_free;
}
_S_start_free = (char*)malloc(__bytes_to_get);
if (0 == _S_start_free) {
size_t __i;
_Obj* __STL_VOLATILE* __my_free_list;
_Obj* __p;
// Try to make do with what we have. That can't
// hurt. We do not try smaller requests, since that tends
// to result in disaster on multi-process machines.
for (__i = __size;
__i <= (size_t) _MAX_BYTES;
__i += (size_t) _ALIGN) {
__my_free_list = _S_free_list + _S_freelist_index(__i);
__p = *__my_free_list;
if (0 != __p) {
*__my_free_list = __p -> _M_free_list_link;
_S_start_free = (char*)__p;
_S_end_free = _S_start_free + __i;
return(_S_chunk_alloc(__size, __nobjs));
// Any leftover piece will eventually make it to the
// right free list.
}
}
_S_end_free = 0; // In case of exception.
_S_start_free = (char*)malloc_alloc::allocate(__bytes_to_get);
// This should either throw an
// exception or remedy the situation. Thus we assume it
// succeeded.
}
_S_heap_size += __bytes_to_get;
_S_end_free = _S_start_free + __bytes_to_get;
return(_S_chunk_alloc(__size, __nobjs));
}
}
于是执行的是:
if (__bytes_left >= __total_bytes) { 160 >=160
__result = _S_start_free; //result是分配出去的chunk块 地址
_S_start_free += __total_bytes;
return(__result);
把这剩余的20个chunk块分配出去,如下:

需求2:8字节的 后20个chunk块用完了,还要分配
首先后20个 chunk块也用完了,那么最后一个块的next域为空,它把空给了 *__my_free_list,于是8字节chunk块的数组元素位 成了一个nullptr。再去分配的话,__result == 0 于是进入_S_refill函数了。在_S_refill函数里面:调用_S_chunk_alloc函数 如下:
size_t __bytes_left = _S_end_free - _S_start_free;
此时的__bytes_left 为0 了,因为_S_end_free 和_S_start_free是相等的,于是执行的的是第一个else,如下:
size_t __bytes_to_get = 2 * __total_bytes + _S_round_up(_S_heap_size >> 4);
但是此时的_S_heap_size 是320,所以这里的__bytes_to_get 是320 + 24 344字节。配置大小为总需求量的两倍再加上一个随配置次数逐渐增加的附加量 。
也就是这次的重新开辟,也就会更大更多的chunk块(这里由_S_heap_size 进行控制)。
需求3:8字节的 前20个chunk块用完.但是要分配16字节的chunk块
__result == 0 于是进入_S_refill函数了。在_S_refill函数里面,调用了_S_chunk_alloc函数。于是我们在回到_S_chunk_alloc函数:计算__total_bytes 是320字节,但是此时__bytes_left =_S_end_free - _S_start_free。是160字节(如下:刚才分配还遗留下来20个8字节的chunk块。)于是就可以进入else if (__bytes_left >= __size) 在这里面做的事情如下:
__nobjs = (int)(__bytes_left/__size);//160 / 16 =10
__total_bytes = __size * __nobjs;//160字节
__result = _S_start_free;
_S_start_free += __total_bytes;
return(__result);
也就是在分配 其他字节大小的chunk块的时候,并没有进行直接分配。而是先检查之前分配过的 备用的 剩余的chunk块(_S_end_free - _S_start_free),此时 160字节不够总的320字节,但是大于16字节,可以分配10个chunk块。
然后:__result 和 _S_start_free 。然后这一块内存就作为 16字节大小的chunk块进行使用了。

返还给调用方之后,_S_refill函数 就要去做第二件事情了:把这些节点(除了第一个节点)的 _M_free_list_link域相连接起来,且最后一个节点置为0 。因为
__result = (_Obj*)__chunk;
*__my_free_list = __next_obj = (_Obj*)(__chunk + __n);
把这个__result 这个要返还的节点 没有连起来。而是从其下一个节点开始连接起来。同时也把下一个空闲chunk块的地址 写入到数组16字节 元素位里面。

总结:开始虽是按照 8字节进行的分配,但是这个备用内存就是得给8字节进行使用。在新给其他字节大小 申请chunk块的时候,是可以直接使用这个备用内存的。但是是需要计算好 这段内存可以分配出 多少节点就可以了。
至此为止,_S_chunk_alloc函数的if 、else if、和else正常分配就结束了。
需求4:8字节的 前20个chunk块用完.但是要分配128字节的chunk块
__result == 0 于是进入_S_refill函数了。在_S_refill函数里面,调用了_S_chunk_alloc函数。于是我们在回到_S_chunk_alloc函数:计算__total_bytes 是2560字节,但是此时__bytes_left =_S_end_free - _S_start_free。是160字节(如下:刚才分配还遗留下来20个8字节的chunk块。)于是就可以进入else if (__bytes_left >= __size) 在这里面做的事情如下:
__nobjs = (int)(__bytes_left/__size);//160 / 128 =1
__total_bytes = __size * __nobjs;//160字节
__result = _S_start_free;
_S_start_free += __total_bytes;
return(__result);
也就是在分配 其他字节大小的chunk块的时候,并没有进行直接分配。而是先检查之前分配过的 备用的 剩余的chunk块(_S_end_free - _S_start_free),此时 160字节不够总的2560字节,但是大于128字节,可以分配1个chunk块。
在之前的操作中,返还给调用方之后,_S_refill函数 就要去做第二件事情了:把这些节点(除了第一个节点)的 _M_free_list_link域相连接起来,且最后一个节点置为0 。可是现在是 就这么一个chunk块,就不涉及之后的_M_free_list_link域相连接起来了。

直接把这个惟一的chunk块的地址 返回就行了。
此时的_S_refill_函数就到此结束了。
2.3.6 _S_chunk_alloc函数的其他情况
// Try to make use of the left-over piece.
if (__bytes_left > 0) {
_Obj* __STL_VOLATILE* __my_free_list =
_S_free_list + _S_freelist_index(__bytes_left);
((_Obj*)_S_start_free) -> _M_free_list_link = *__my_free_list;
*__my_free_list = (_Obj*)_S_start_free;
}
上一段代码的处理如下:在上一个 需求4里面,分配128字节成功之后,备用内存还剩余32字节。
需求5 在备用内存32字节上,申请40字节的chunk块
因为数组里面40字节对应的元素位 里面的 Obj* 肯定是0.进入_S_refill函数,然后在里面调用_S_chunk_alloc函数。在_S_chunk_alloc函数里面:__total_bytes =40 * 20 =800 。
size_t __bytes_left = _S_end_free - _S_start_free;//320-288=32
if (__bytes_left >= __total_bytes)和else if (__bytes_left >= __size)都进不去。连一个40字节的chunk块都不够分的。直接进入else里面,如下:
size_t __bytes_to_get = 2 * __total_bytes + _S_round_up(_S_heap_size >> 4);
为2 * 800 + 24=1624 字节(这里的_S_heap_size 只是在增加而没有减)
接下来,就进入了 我们要讨论的重点:
if (__bytes_left > 0) {//32 > 0
_Obj* __STL_VOLATILE* __my_free_list =
_S_free_list + _S_freelist_index(__bytes_left);
((_Obj*)_S_start_free) -> _M_free_list_link = *__my_free_list;
*__my_free_list = (_Obj*)_S_start_free;
}
如上:现在由于_S_end_free 和 _S_start_free不在一个地方,备用内存剩余32字节。
首先把_S_freelist_index(__bytes_left),找到32字节对应的数组 元素位。(32字节还是可以使用到32字节的元素位的内存池上的,不能浪费)。此时的__my_free_list 指向的就是数组32字节的元素位。那么 * __my_free_list就表示空,或者这个字节大小的chunk块内存池的第一个空闲节点的地址。 接下来做的事情就是:
((_Obj*)_S_start_free) -> _M_free_list_link = *__my_free_list;
*__my_free_list = (_Obj*)_S_start_free;
把这个32字节的内存块当做是一个 完整的32字节chunk块给进行 头插法,插入其中。
此时为止 备用内存全部解决掉了。
那么在解决完连一个40字节的都不够分的 备用内存之后,就要去给这个40字节 去开辟它的chunk块内存池了。如下:
_S_start_free = (char*)malloc(__bytes_to_get);
if (0 == _S_start_free) {
size_t __i;
_Obj* __STL_VOLATILE* __my_free_list;
_Obj* __p;
注: 上面的__bytes_to_get 到此刻为止,此时我的计算是开辟1624 字节。但是这个和我的老师 相差巨大(他的计算是60 * 40=2400字节),而且他刚才2019年8月18日12:49:49 还训了我一顿。但是我感觉我没有算错,看我博客的朋友们,也可以暂停一下 也动手计算一下(此时此刻的__bytes_to_get 值)。如与我的计算有所区别,可以在评论区备注。真相越辩越明,大家对待学习 还是要谨慎细心一点。欢迎各位的指正!!!
回到上面,由malloc进行开辟,于是 我们的需求 6就来了。
需求6 :由malloc进行开辟,40字节对应的内存池 但是开辟失败
malloc开辟失败,证明内存是不够用的。
_S_start_free = (char*)malloc(__bytes_to_get);
if (0 == _S_start_free) {
size_t __i;
_Obj* __STL_VOLATILE* __my_free_list;
_Obj* __p;//可以通过访问一个chunk块的头,进而访问下一个节点
// Try to make do with what we have. That can't
// hurt. We do not try smaller requests, since that tends
// to result in disaster on multi-process machines.
for (__i = __size;
__i <= (size_t) _MAX_BYTES;
__i += (size_t) _ALIGN) {
__my_free_list = _S_free_list + _S_freelist_index(__i);
__p = *__my_free_list;
if (0 != __p) {
*__my_free_list = __p -> _M_free_list_link;
_S_start_free = (char*)__p;
_S_end_free = _S_start_free + __i;
return(_S_chunk_alloc(__size, __nobjs));
// Any leftover piece will eventually make it to the
// right free list.
}
}
_S_end_free = 0; // In case of exception.
_S_start_free = (char*)malloc_alloc::allocate(__bytes_to_get);
// This should either throw an
// exception or remedy the situation. Thus we assume it
// succeeded.
}
里面的for循环做的事情:i 从40 字节一直开始遍历,直到128字节。之所以从40字节大小开始,之前的chunk块大小是不够40的,放不下的。
__my_free_list = _S_free_list + _S_freelist_index(__i);
__p = *__my_free_list;
两句的意思就是:这个__my_free_list 二级指针去遍历数组的这几个元素位,把其解引用(放的是每个元素位的 这个对应字节大小的内存池的第一个空闲节点地址,或者为0)给到(Obj * _p指针里面)于是这个_p指针就可以去访问相应 字节的内存池的内容。(40字节的这个chunk块内存池在40字节的数组元素位里面肯定是 0,假如说此刻的48处,指针不为空。它下面有空闲的chunk块,大小当然都是48字节大小的。)
在if里面:
if (0 != __p) {
*__my_free_list = __p -> _M_free_list_link;
_S_start_free = (char*)__p;
_S_end_free = _S_start_free + __i;
return(_S_chunk_alloc(__size, __nobjs));
// Any leftover piece will eventually make it to the
// right free list.
}
把人家48的一个空闲chunk块 摘下来1个。然后接下来做的就是用_S_start_free 和 _S_end_free 把这个chunk块给 标识出来了。如下:

接下来做了一个 return(_S_chunk_alloc(__size, __nobjs));
在接下来的_S_chunk_alloc(40,20)里面,
/* We allocate memory in large chunks in order to avoid fragmenting */
/* the malloc heap too much. */
/* We assume that size is properly aligned. */
/* We hold the allocation lock. */
template <bool __threads, int __inst>
char*
__default_alloc_template<__threads, __inst>::_S_chunk_alloc(size_t __size,
int& __nobjs)
{
char* __result;
size_t __total_bytes = __size * __nobjs;//内存池需要 总的字节数 也就是20个节点
size_t __bytes_left = _S_end_free - _S_start_free;//48 字节了
if (__bytes_left >= __total_bytes) {//进不去
__result = _S_start_free;
_S_start_free += __total_bytes;
return(__result);
} else if (__bytes_left >= __size) {//48 40
__nobjs = (int)(__bytes_left/__size);
__total_bytes = __size * __nobjs;
__result = _S_start_free;
_S_start_free += __total_bytes;
return(__result);
} else {
size_t __bytes_to_get =
2 * __total_bytes + _S_round_up(_S_heap_size >> 4);
// Try to make use of the left-over piece.
if (__bytes_left > 0) {
_Obj* __STL_VOLATILE* __my_free_list =
_S_free_list + _S_freelist_index(__bytes_left);
((_Obj*)_S_start_free) -> _M_free_list_link = *__my_free_list;
*__my_free_list = (_Obj*)_S_start_free;
}
_S_start_free = (char*)malloc(__bytes_to_get);
if (0 == _S_start_free) {
size_t __i;
_Obj* __STL_VOLATILE* __my_free_list;
_Obj* __p;
// Try to make do with what we have. That can't
// hurt. We do not try smaller requests, since that tends
// to result in disaster on multi-process machines.
for (__i = __size;
__i <= (size_t) _MAX_BYTES;
__i += (size_t) _ALIGN) {
__my_free_list = _S_free_list + _S_freelist_index(__i);
__p = *__my_free_list;
if (0 != __p) {
*__my_free_list = __p -> _M_free_list_link;
_S_start_free = (char*)__p;
_S_end_free = _S_start_free + __i;
return(_S_chunk_alloc(__size, __nobjs));
// Any leftover piece will eventually make it to the
// right free list.
}
}
_S_end_free = 0; // In case of exception.
_S_start_free = (char*)malloc_alloc::allocate(__bytes_to_get);
// This should either throw an
// exception or remedy the situation. Thus we assume it
// succeeded.
}
_S_heap_size += __bytes_to_get;
_S_end_free = _S_start_free + __bytes_to_get;
return(_S_chunk_alloc(__size, __nobjs));
}
}
进入的是 else if里面,只能分配一个。但是还剩下 8字节。如下:

把这个40字节的chunk块地址 给返回回去了。但是在以后这个归还的时候,是还给了40字节的内存池里面。至于那个8字节的剩余 备用内存,会在之后的字节申请中 处理掉。(有可能申请大于8 则这个备用内存挂在了 8字节的chunk块内存池上面 或者 申请就是8字节,那么就直接给return了,反正这个备用内存是不会被浪费掉的。)
需求7: 但是开辟失败。且找遍了其他元素位,没有空闲块
所有的_p都是空的,其他的元素位下面都没有 空闲的chunk块。此时for循环结束了,然后如下:
_S_end_free = 0; // In case of exception.
_S_start_free = (char*)malloc_alloc::allocate(__bytes_to_get);
// This should either throw an
// exception or remedy the situation. Thus we assume it
// succeeded.
_S_end_free 置为0,再进行重新malloc。
然后就进入了malloc_alloc::allocate(_bytes_to_get):方法

成功则 return,还没有成功 则调用 S _ oom _malloc了。
2.3.7 malloc再次失败 处理需求7
如果上面的分配,继续失败:由_ S _ oom _malloc方法进行处理:

里面定义了指向一个 返回值为空,参数为空的函数指针类型的变量。接下来在下面的死循环里面,就这个指针__my_malloc_handler 指向 __malloc_alloc_oom_handler这个回调函数。

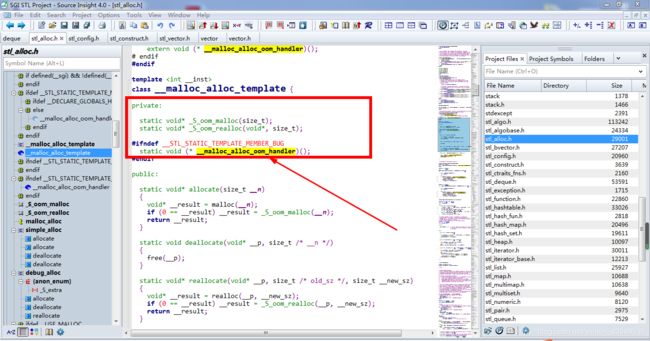
如上图:这个函数指针 也就是提供了这么一种方式:SGI STL在这里允许用户自己去提前设定这么一个回调函数来处理 这种底层内存开辟失败。也即:在发生底层内存开辟失败的时候,我的这个函数可以会被调用,这个回调函数(用户自己定义的,比如可以释放一些资源的代码 )处理完成之后,就会有空间了。然后再由本程序 继续执行,进行
__result = malloc(__n);
if (__result) return(__result);
处理了。
总结:在_S_oom_malloc函数的for循环里面,先用这个函数指针变量 指向了(相当于回调函数的)__malloc_alloc_oom_handler(给这个静态成员变量初始化 默认为0 表示没设置),如果用户也没有预先设置了这么一个回调函数,那么就执行下面的代码:
if (0 == __my_malloc_handler) { __THROW_BAD_ALLOC; }
直接抛出bad_alloc这么一个异常,系统就会终止这个进程了。如果用户也预先设置了这么一个回调函数,那么就执行下面的代码:
(*__my_malloc_handler)();
__result = malloc(__n);
if (__result) return(__result);
在if判断 确认之后,调用这个用户的回调函数(用户自己定义的,比如可以释放一些资源的代码 ),处理完成之后,或许就会有一定的空间了。然后再由本程序 继续执行malloc,如下:进行
__result = malloc(__n);
if (__result) return(__result);
处理了。若是分配成功了,就把这个分配成功的内存的起始地址进行返回就行了。
注:这个设置回调函数要 注意这么一个问题:如果在调用完 用户的回调函数之后,还是分配失败。则会继续再次循环一遍:再调用回调函数、再次malloc、再次判断if 开辟成功。这是一个死循环,然后不断地调用用户你提供的回调函数,直到malloc成功,然后返回。所以说:要真的提供这么一个回调函数,是要想清楚:这个函数是真的可能释放出一些资源的,否则 整个系统就会陷入 死循环之中,且人家根本就不会去抛出异常。
好的,假如上面分配成功了,就会返回 
_S_start_free 接收了上面返回的内存起始地址:
_S_heap_size += __bytes_to_get;
_S_end_free = _S_start_free + __bytes_to_get;
return(_S_chunk_alloc(__size, __nobjs));//新获得了这么一块内存 然后就处理这么内存
又用_S_start_free 和 _S_end_free 把刚才申请的内存标识起来了。再次调用 ,在这个内存上 获得chunk块。
到此为止:_S_chunk_alloc 函数就全部结束了。
内存池的设计目的:

SGI STL二级空间配置器带给我们的启示:
注:针对上面的诸多优点 作上一点补充:我感觉上面的8字节被 划分到数组8字节元素位 下面的chunk块内存池之后,这个8字节的chunk块的使用 和 它头上的40字节的chunk块的使用,就与当前48字节的chunk块 内存池好像没有关系了,这两个块 已经被各自对应的内存池所管理了。
2.3.8 reallocate函数 内存扩容和减容的源码剖析
template <bool threads, int inst>
void*
__default_alloc_template<threads, inst>::reallocate(void* __p,//内存块的起始地址
size_t __old_sz,
size_t __new_sz)
{
void* __result;//两个局部变量
size_t __copy_sz;
if (__old_sz > (size_t) _MAX_BYTES && __new_sz > (size_t) _MAX_BYTES) {
return(realloc(__p, __new_sz));//开辟的方式 不是通过内存池,这里依旧给你
}//调用的是c语言的 库函数
if (_S_round_up(__old_sz) == _S_round_up(__new_sz)) return(__p);
__result = allocate(__new_sz);
__copy_sz = __new_sz > __old_sz? __old_sz : __new_sz;
memcpy(__result, __p, __copy_sz);
deallocate(__p, __old_sz);
return(__result);
}
这里的C的库函数realloc (__p, __new_sz) 根据new_size重新开辟空间,然后进行数据拷贝。若是在原来的地方接着开辟 就不涉及释放内存。在其他处开辟的,则在数据拷贝之后 把原先的内存释放掉。
if (_S_round_up(__old_sz) == _S_round_up(__new_sz)) return(__p);
这上面这句话:假如old 是6字节,而new是7字节,都是在(上调到8)8字节的chunk块上,直接返回 不用去扩容了。
不是的话:(也就是上调 过后,在8的不同倍数的字节数上)
__result = allocate(__new_sz);
__copy_sz = __new_sz > __old_sz? __old_sz : __new_sz;
memcpy(__result, __p, __copy_sz);
deallocate(__p, __old_sz);
return(__result);
首先调用 上面的allocate方法,重新给你分配 传入__new_sz字节的 chunk块。接下来判断是 扩容还是缩容?接着数据拷贝:把数据从old _p指向的chunk块里面,拷贝到新的__result指向的新的chunk块(扩容或者缩容),拷贝的大小就是__copy_sz 。
把_p指向的旧的 __old_sz大小的chunk块给 归还内存池。最后把 扩容或者缩容的chunk块地址进行返还。
到此为止 :SGI STL的二级空间配置器的内存池管理的源码剖析结束。2019年8月18日18:38:29