opencv人脸检测和识别
1.Haar级联概念
类Harr特征是一种用于实现实时人脸跟踪的特征。
即使窗口大小不一样,仅在尺度不同的两幅图像也应该具有相似的特征,这些特征集合成为级联。
Harr级联具有尺度不变性。
opencv的Haar级联不具有旋转不变性,即Haar级联不认为导致的人脸图像和直立的人脸图像一样,侧面的人脸图像和正面的人脸图像也不一样。
2.获取Haar级联数据
OpenCV提供了尺度不变Haar级联的分类器和跟踪器,OpenCV3的源码中提供了所有OpenCV的用于人脸检测的XML文件,这些文件可以检测静止图像、视频和摄像头所获得图像中的人脸。
在D:\python\anaconda\Anaconda\Library\etc\haarcascades有个haarcascades的文件夹,文件夹中有用于检测人脸,眼睛,鼻子,嘴的跟踪的级联,这些文件需要正面,直立的人脸图像,在后面创建人脸检测器时会使用这些文件,我们可以创造自己的级联,训练这些级联来检测各种对象。
3.使用opencv进行静态人脸检测
从上面文件夹里复制所有文件到项目文件夹里面的cascades文件夹里面去:
import cv2
filename = 'E:\\fig_data\\biye_2.jpg'
def detect(filename):
face_cascade = cv2.CascadeClassifier('cascades\\haarcascade_frontalface_default.xml')
img = cv2.imread(filename)
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray,1.3,5)#检测人脸需要用灰度图像
for (x,y,w,h) in faces:
img = cv2.rectangle(img,(x,y),(x+w,y+h),(255,0,0),2)
cv2.imshow('Detected',img)
cv2.waitKey()
detect(filename)
face_cascade.detectMultiScale(gray,1.3,5)
第二个参数指每次迭代时图像的压缩率
第三个参数指每个人脸矩形保留近似数目的最小值,这里是五,表示框出检测到五次是人脸的脸
返回的faces为
[[160 346 28 28]
[590 482 124 124]
[313 346 92 92]
[450 647 186 186]
[166 837 73 73]
[636 458 156 156]
[328 383 74 74]
[167 847 195 195]]
为识别出来的没个人脸框的位置,长宽信息
4.使用opencv进行视频中的人脸检测
import cv2
def detect():
face_cascade = cv2.CascadeClassifier('cascades\\haarcascade_frontalface_default.xml')
eye_cascade = cv2.CascadeClassifier('cascades\\haarcascade_eye.xml')
camera = cv2.VideoCapture(0)#初始化摄像头,定义摄像头
while camera.isOpened():
ret,frame = camera.read()#读取摄像头每一帧
gray = cv2.cvtColor(frame,cv2.COLOR_RGB2GRAY)
faces = face_cascade.detectMultiScale(gray,1.3,5)
for(x,y,w,h) in faces:
img = cv2.rectangle(frame,(x,y),(x+w,y+h),(255,0,0),2)
roi_gray = gray[y:y+h,x:x+w]#把这一小块脸部区域取出来
#在这块区域里面识别眼睛
eyes = eye_cascade.detectMultiScale(roi_gray,1.03,5,0,(40,40))
for (ex,ey,ew,eh) in eyes:
# print('face',w,y,w,h)
# print('eye',ex,ey,ew,eh)
cv2.rectangle(img,(x+ex,y+ey),(x+ex+ew,y+ey+eh),(0,255,0),2)
cv2.imshow('camera',frame)
cv2.imshow('gray',roi_gray)
if cv2.waitKey(5) & 0xff == ord('q'):
break
camera.release()
cv2.destroyAllWindows()
detect()
5.人脸识别
生成人脸数据
这里我们从电脑的摄像头里面检测人脸图片,然后将人脸图剪裁,存储,作为学习样本,所以这里的图片有三个条件:
- 都是灰度图,后缀名都是一样的
- 图像是正方形
- 大小为200*200
import cv2
def generate():
face_cascade = cv2.CascadeClassifier('cascades\\haarcascade_frontalface_default.xml')
camera = cv2.VideoCapture(0)#初始化摄像头,定义摄像头
count = 0
while camera.isOpened():
ret,frame = camera.read()#读取摄像头每一帧
gray = cv2.cvtColor(frame,cv2.COLOR_RGB2GRAY)
faces = face_cascade.detectMultiScale(gray,1.3,5)
for(x,y,w,h) in faces:
print(x,y,w,h)
img = cv2.rectangle(frame,(x,y),(x+w,y+h),(255,0,0),2)
roi_gray = gray[y:y+h,x:x+w]#把这一小块脸部区域取出来
f = cv2.resize(roi_gray,(200,200))#改变成相同大小的图片
cv2.imwrite('data\\zx\\%s.jpg' %str(count),f)#存下来
count += 1
print(count)
cv2.imshow('camera',img)
cv2.imshow('face',roi_gray)
if cv2.waitKey(5) & (count == 50):
break
camera.release()
cv2.destroyAllWindows()
generate()
cv2.waitKey(5) 一定不要忘记加,我已开始忘记加了,然后camera窗口就一直是未响应,也提取不到帧图像,data里面也存不下人脸图片,然后这样就保存了50张摄像头获取的人脸图像
加载数据
下面需要将数据整合,一个是由摄像头保存下来的图片数据,另一个是csv文件,在X中存储图像数组,在y中存储labels:
import os
import numpy as np
import cv2
def read_images(path,sz = None):
c = 0
X,y = [],[]
names = []
for dirname,dirnames,filenames in os.walk(path):
# print(dirname)#dirname是文件夹名字data,显示下面还有文件夹zx...
# print(dirnames)#显示下面的文件夹名字‘zx’...,并且下面没有文件夹了
# print(filenames)#filenames是每个图片的名字
for subdirname in dirnames:
# print(subdirname)#文件名,又或者说是类名
names.append(subdirname)
subject_path = os.path.join(dirname,subdirname)
# print(subject_path)#subject_path是吧data和子文件夹名字合在一起成data\zx这样了
# print(os.listdir(subject_path))#图片名组成的列表
for filename in os.listdir(subject_path):
# print(filenames)
filepath = os.path.join(subject_path,filename)
# print(filepath)#把文件名都连起来,data\zx\0.jpg
im = cv2.imread(filepath,cv2.IMREAD_GRAYSCALE)
#读取的图片如果不是(200,200)改变大小
if (sz is not None):
im = cv2.resize(im,(200,200))
X.append(np.asarray(im,dtype = np.uint8))
y.append(c)
c = c+1
return [X,y],names
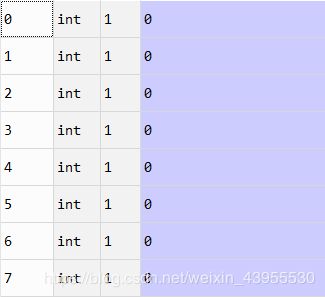
[X,y],names = read_images('data')
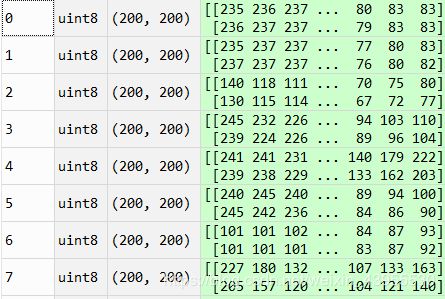
可以看到图像确实变成了训练数据X,20个(200,200)的矩阵,y是20个labels
训练model:
model = cv2.face.EigenFaceRecognizer_create()
model.train(np.asarray(X),np.asarray(y))
人脸识别
在摄像头采集到的图片中检测:
names = ['zx']
def face_rec():
camera = cv2.VideoCapture(0)
face_cascade = cv2.CascadeClassifier('cascades\\haarcascade_frontalface_default.xml')
while camera.isOpened():
ret,frame = camera.read()#读取摄像头每一帧
gray = cv2.cvtColor(frame,cv2.COLOR_RGB2GRAY)
faces = face_cascade.detectMultiScale(gray,1.3,5)
print(faces)
for (x,y,w,h) in faces:
img = cv2.rectangle(frame,(x,y),(x+w,y+h),(255,0,0),2)
# global roi_gray
roi_gray = gray[y:y+h,x:x+w]
roi_gray = cv2.resize(roi_gray,(200,200))
params = model.predict(roi_gray)
print('Label:%s,Confidence:%.2f' %(params[0],params[1]))
cv2.putText(img,names[params[0]],(x,y-20),cv2.FONT_HERSHEY_SIMPLEX,1,255,2)
cv2.imshow('gray',roi_gray)
cv2.imshow('camera',frame)
if cv2.waitKey(5) & 0xff == ord('q'):
break
camera.release()
cv2.destroyAllWindows()
face_rec()
cv2.imshow(‘camera’,frame)我试过写成: cv2.imshow(‘camera’,img)但是这样就只能放在for循环里面了,因为img不是全局的,但是这样会出现一个问题,就是图片的显示上很卡,因为只有检测到人脸,才会imshow,没有检测到的帧是不显示的,这样造成视觉上的效果就是卡,所以用frame取imshow会使视觉上看上去流畅一些
predict()返回两个元素的数组:第一个元素是所识别个体的标签,第二个是置信度评分,用来衡量所识别人脸与原模型的差别
如果要识别多张人脸的话,还是先从摄像头里采集到人脸信息,单独建文件夹,保存不同的人脸:
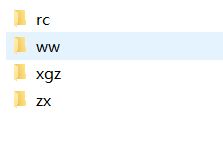
这里建了四个人的人脸文件夹,然后y会产生四个不同的标识,names也会相应改变,识别出来的索引直接得到每个人的名字
当然,也可以用静态的图片识别人脸:
filename = 'E:\\fig_data\\1.jpg'
def detect(filename):
face_cascade = cv2.CascadeClassifier('cascades\\haarcascade_frontalface_default.xml')
img = cv2.imread(filename)
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray,1.1,1)#检测人脸需要用灰度图像
# print(faces)
for (x,y,w,h) in faces:
print(x,y,w,h)
if (w > 100) & (h >100):
img = cv2.rectangle(img,(x,y),(x+w,y+h),(255,0,0),2)
roi_gray = gray[y:y+h,x:x+w]
roi_gray = cv2.resize(roi_gray,(200,200))
params = model.predict(roi_gray)
print('Label:%s,Confidence:%.2f' %(params[0],params[1]))
cv2.putText(img,names[params[0]],(x,y-20),cv2.FONT_HERSHEY_SIMPLEX,1,255,2)
cv2.imshow('Detected',img)
img_2 = img[:,:,[2,1,0]]
plt.imshow(img_2)#plt显示图片的原理跟cv2不一样是RGB所以需要将三个通道换一下
cv2.waitKey()
detect(filename)
其他模型
我们可以看出上面模型是采用EigenFaceRecgonizer的模型:
model = cv2.face.EigenFaceRecognizer_create()
不指定参数的话,里面有两个参数为默认值,一个是想要保留的主成分数目,第二个是置信度阈值
如果要用Fisherfaces的话,只需要改成:
model = cv2.face.FisherFaceRecognizer_create()
两个参数,一个是Feisherface的参数,一个是置信度阈值
如果要用LBPH的模型话:
model = cv2.face.LBPHFaceRecognizer_create()
如果不指定参数的话,保留默认的参数五个,radius = 1,neighbors = 8,grid_x =8,grid_y = 8,置信度 = 123.0
注意: LBPH 不需要调整图片的大小,因为网格中的分割允许在每个单元中比较识别到的模式
Eigenfaces、Fisherface、LBHP的置信度评分完全不同,Eigenfaces和Fisherfaces将产生0-20000的值,而任意低于4000-5000的评分都是相当可靠的识别;LBHP的参考值最好是低于50,任何高于80的参考值都被认为是低的置信度评分