概率导论(贝叶斯统计推断)
概率导论-贝叶斯统计推断
- 基本问题
- 统计学与概率论
- 贝叶斯统计与经典统计
- 推断模型与推断变量
- 术语解释
- 贝叶斯统计推断
- 流程
- 最大后验概率准则及应用
- 贝叶斯最小均方估计LMS
- 性质
- 多维度(多次观测及多估计参数)
- 线性最小均方估计
- 一元一次函数
- 多观测值和多参数
基本问题
- 统计推断是什么?
统计推断是从观测数据推断未知变量或未知模型的有关信息的过程。 - 统计推断的用途是什么?
统计推断可用于“参数估计”,“假设检验”,“显著性检验” - 统计推断的研究思路是什么?
主要有两种思路:“贝叶斯统计推断” 和“经典统计推断”。(大局方法) - 统计推断具体使用的"算法"有哪些?
最大后验概率准则,最小均方估计,最大似然估计,回归,似然比检验等。(小方法)
统计学与概率论
“统计学”与“概率论”在认识论上有明显的区别。
概率论是建立在概率公理上的系统自我完善的数学课题。我们会假设一个完整的特定的概率模型满足概率公理,然后用数学方法研究模型的一些性质。概率模型无需与现实世界相一致,它值对概率公理负责。
统计学是针对一个具体的问题,寻求合理的研究方法,希望得到合理的结论。这就存在很大的自由度,采取不同的研究方法,结论可能不同。通常我们会附加一些限制条件,以便得到“理想结论”。
正是由于统计学的这种特征,现实社会存在许多人为制造的"理想结论",这些结论可能来源于真实的数据,但研究方法是人为选定的。
贝叶斯统计与经典统计
贝叶斯统计与经典统计(频率学派)是两种突出但对立的思想学派。
最重要的区别就是如何看待未知模型或变量。贝叶斯学派将其看成已知分布的随机变量。而经典统计将其看成未知的待估计的量。
贝叶斯方法将统计拉回“概率论”的研究领域,使得每个问题只有一个答案。经典统计将未知量看作一种参数,它是一个常数,未知需要估计。
从现实角度来看,贝叶斯统计主张将假设的先验分布公开,即研究过程公开了。贝叶斯统计推断涉及到多维度积分,计算困难,所以贝叶斯学派的最新成功可能集中于如何计算上。
推断模型与推断变量
这两种问题有细微的区别。推断模型是为了研究某种现象或过程的一般规律,以期能够预测未来现象的结果。推断变量是从已知的量,推测未知的量,例如从gps信息推断所处于的位置。
术语解释
- 参数估计:对参数进行估计,使得在某种概率意义下估计接近真实值。
- 假设检验:未知参数根据对立的假设可能取有限个值,选择一个假设,目标是使犯错误的概率最小。
- 显著性检验:
- 最大后验概率(MAP)准则:给待估计的量假设一个分布,在观测条件下,最大化后验概率的值。
- 最小均方(LMS):选择数据的一个估计量或函数,使得参数与估计之间的均方误差达到最小。
- 线性最小均方(LLMS)误差:为了计算简单,简化版的LMS。
贝叶斯统计推断
流程
- 起点是未知随机变量 Θ \Theta Θ的先验分布 p Θ p_{\Theta} pΘ或 f Θ f_{\Theta} fΘ
- 得到观测向量X的 p X ∣ Θ p_{X|\Theta} pX∣Θ或 f X ∣ Θ f_{X|\Theta} fX∣Θ
- 一旦观测到X的一个特定值x后,运用贝叶斯法则计算 Θ \Theta Θ的后验分布 p Θ ∣ X p_{\Theta|X} pΘ∣X或 f Θ ∣ X f_{\Theta|X} fΘ∣X
四种贝叶斯法则计算后验分布:
(省略了括号及括号内的参数,四种情形本质上是一样的,都是贝叶斯公式的运用。连续和离散的区别就是用积分号代替求和,用f代替p.分母其实都是常数,不用直接计算。)
- Θ , X \Theta,X Θ,X均离散。
p Θ ∣ X = p Θ p X ∣ Θ ∑ θ p Θ p X ∣ Θ p_{\Theta|X}=\frac{p_{\Theta}p_{X|\Theta}}{\sum _{\theta}{p_{\Theta}p_{X|\Theta}}} pΘ∣X=∑θpΘpX∣ΘpΘpX∣Θ - Θ \Theta Θ离散, X X X连续
p Θ ∣ X = p Θ f X d x ∑ θ p Θ f X ∣ Θ d x = p Θ f X ∣ Θ ∑ θ p Θ f X ∣ Θ p_{\Theta|X}=\frac{p_{\Theta}f_{X}dx}{\sum _{\theta}p_{\Theta}f_{X|\Theta}dx}=\frac{p_{\Theta}f_{X|\Theta}}{\sum _{\theta}p_{\Theta}f_{X|\Theta}} pΘ∣X=∑θpΘfX∣ΘdxpΘfXdx=∑θpΘfX∣ΘpΘfX∣Θ - Θ \Theta Θ连续, X X X离散
f Θ ∣ X = f Θ ∗ p X ∣ Θ ∫ − ∞ + ∞ ( f Θ p X ∣ Θ ) d θ f_{\Theta|X}=\frac{f_{\Theta}*p_{X|\Theta}}{\int _{-\infty}^{+\infty}({f_{\Theta} p_{X|\Theta})d\theta}} fΘ∣X=∫−∞+∞(fΘpX∣Θ)dθfΘ∗pX∣Θ - Θ \Theta Θ连续, X X X连续
f Θ ∣ X = f Θ ∗ f X ∣ Θ ∫ − ∞ + ∞ ( f Θ f X ∣ Θ ) d θ f_{\Theta|X}=\frac{f_{\Theta}*f_{X|\Theta}}{\int _{-\infty}^{+\infty}({f_{\Theta} f_{X|\Theta})d\theta}} fΘ∣X=∫−∞+∞(fΘfX∣Θ)dθfΘ∗fX∣Θ
举例子:某人上班迟到时间是一个随机变量X,服从参数为 [ 0 , θ ] [0,\theta] [0,θ]上的均匀分布, θ \theta θ未知,是随机变量 Θ \Theta Θ的一个值, Θ \Theta Θ服从 [ 0 , 1 ] [0,1] [0,1]上的均匀分布。假设某次迟到时间为x。用贝叶斯推断估计 θ \theta θ.
使用推断流程:
- f Θ = 1 , 0 ≤ θ ≤ 1 f_\Theta =1,0\le \theta \le 1 fΘ=1,0≤θ≤1
- f X ∣ Θ ( x ∣ θ ) = 1 / θ , 0 ≤ x ≤ θ f_{X|\Theta}(x|\theta)=1/\theta,0\le x \le \theta fX∣Θ(x∣θ)=1/θ,0≤x≤θ
- f Θ ∣ X = c ( x ) / θ , x ≤ θ ≤ 1 f_{\Theta|X}=c(x)/\theta,x\le \theta \le 1 fΘ∣X=c(x)/θ,x≤θ≤1
上面这个例子得出了后验分布以后,怎样估计 θ \theta θ值呢?引出了下一节的内容。
最大后验概率准则及应用
最大后验概率准则(Maximum a posteriori probability):知道后验概率分布以后,求此分布取最大值时的 θ \theta θ值作为估计。其原理是在条件 X = x X=x X=x下,求 θ \theta θ最可能的值。
再次续上上面那个例子:
使用最大后验分布准则:要使 f Θ ∣ X f_{\Theta|X} fΘ∣X最大化,则 θ ^ = x \hat \theta=x θ^=x.
下面使用画图解释:
画出 θ − x \theta-x θ−x的取值范围图:
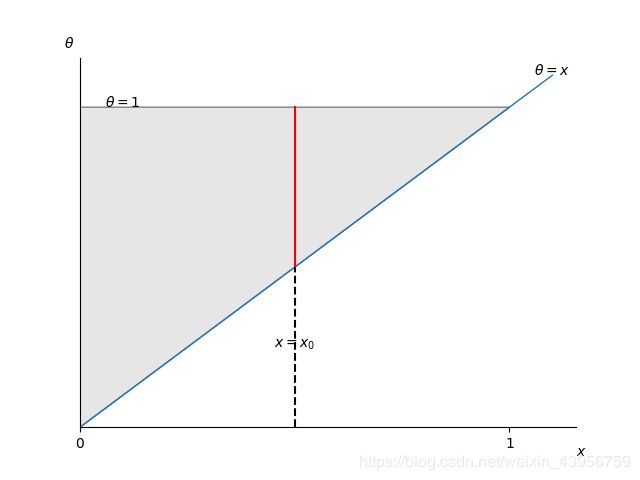
θ \theta θ的取值范围图中阴影部分。对于观测值 x = x 0 , θ x=x_0,\theta x=x0,θ的取值范围为图中红线部分(但不一定是均匀分布的)。显然当 θ = x \theta =x θ=x时能使后验概率达到最大。
可以看出,贝叶斯推断就是在确定 θ \theta θ取值范围之后,找寻 θ = g ( x ) \theta=g(x) θ=g(x)满足某种条件。
如果使用条件期望估计即 θ = E ( Θ ∣ X = x ) \theta=E(\Theta|X=x) θ=E(Θ∣X=x),注意 Θ = g ( x ) \Theta=g(x) Θ=g(x)不一定是线性的。此时可以得出 θ \theta θ的另一个估计。
贝叶斯最小均方估计LMS
顾名思义,最小均方估计就是求 θ ^ = g ( x ) \hat \theta=g(x) θ^=g(x)使得估计误差 θ ^ − Θ \hat \theta - \Theta θ^−Θ的均方误差(不是方差)达到最小。
E [ ( θ ^ − Θ ) 2 ] = v a r ( Θ ) + [ E ( Θ ) − θ ^ ] 2 E[(\hat \theta - \Theta)^2]=var(\Theta)+[E(\Theta)-\hat \theta]^2 E[(θ^−Θ)2]=var(Θ)+[E(Θ)−θ^]2
所以最小均方误差取最小值时有:
θ ^ = E ( Θ ) \hat \theta=E(\Theta) θ^=E(Θ)
现在考虑在观测条件 X = x X=x X=x下,最小均方误差为:
E [ ( θ ^ − Θ ) 2 ∣ X = x ] = v a r ( Θ ∣ X = x ) + [ E ( Θ ∣ x ) − θ ^ ) ] E[(\hat \theta-\Theta)^2|X=x]=var(\Theta |X=x)+[E(\Theta|x)-\hat \theta)] E[(θ^−Θ)2∣X=x]=var(Θ∣X=x)+[E(Θ∣x)−θ^)]
此时:
θ ^ = g ( x ) = E ( Θ ∣ X = x ) \hat\theta=g(x)=E(\Theta|X=x) θ^=g(x)=E(Θ∣X=x)
E ( Θ ∣ X = x ) E(\Theta|X=x) E(Θ∣X=x)是所有 g ( x ) g(x) g(x)中能使均方误差最小的 g ( x ) g(x) g(x).
性质
最小均方误差估计及其误差:
Θ ^ = E ( Θ ∣ X ) , Θ ~ = Θ ^ − Θ \hat \Theta=E(\Theta|X),\tilde\Theta=\hat \Theta-\Theta Θ^=E(Θ∣X),Θ~=Θ^−Θ
- Θ ^ \hat\Theta Θ^是无偏估计,即 E ( Θ ^ ) = E ( Θ ) , E ( Θ ~ ) = 0 , E ( Θ ~ ∣ X = x ) = 0 E(\hat\Theta)=E(\Theta),E(\tilde\Theta)=0,E(\tilde\Theta|X=x)=0 E(Θ^)=E(Θ),E(Θ~)=0,E(Θ~∣X=x)=0
- 估计误差 Θ ~ \tilde\Theta Θ~和估计量 Θ ^ \hat\Theta Θ^不相关: c o v ( Θ ~ , Θ ^ ) = 0 − 0 = 0 cov(\tilde\Theta,\hat\Theta)=0-0=0 cov(Θ~,Θ^)=0−0=0
- v a r ( Θ ) = v a r ( Θ ~ ) + v a r ( Θ ^ ) var(\Theta)=var(\tilde\Theta)+var(\hat\Theta) var(Θ)=var(Θ~)+var(Θ^)
多维度(多次观测及多估计参数)
在多次观测的条件下: Θ ^ = E ( Θ ∣ X 1 , X 2 , . . . , X n ) \hat \Theta=E(\Theta|X_1,X_2,...,X_n) Θ^=E(Θ∣X1,X2,...,Xn)
这个式子难以计算,所以经常附加线性估计的约束条件,简化计算。
在多参数( Θ 1 , Θ 2 , . . . , Θ n \Theta _1,\Theta _2,...,\Theta _n Θ1,Θ2,...,Θn)时:
最小均方的计算式子为: E [ ( Θ 1 − Θ ^ 1 ) 2 + ( Θ 2 − Θ ^ 2 ) 2 . . . . + ( Θ n − Θ ^ n ) 2 ] E[(\Theta _1-\hat\Theta _1)^2+(\Theta _2-\hat\Theta _2)^2....+(\Theta _n-\hat\Theta _n)^2] E[(Θ1−Θ^1)2+(Θ2−Θ^2)2....+(Θn−Θ^n)2]
上面的式子说明在多个待估参数时,等价于分别求单个参数的估计: Θ ^ i = E ( Θ i ∣ X ) \hat\Theta _i=E(\Theta _i|X) Θ^i=E(Θi∣X).
同时有多观测及多参数:
Θ ^ i = E ( Θ i ∣ X 1 , X 2 , . . . , X n ) \hat\Theta _i=E(\Theta _i|X_1,X_2,...,X_n) Θ^i=E(Θi∣X1,X2,...,Xn).
线性最小均方估计
在计算最小均方估计时,为了计算方便,假定 θ ^ \hat\theta θ^是观测值 x x x的线性函数,即 g ( x ) g(x) g(x)是线性函数。
多维度的情况:
Θ ^ = a 1 X 1 + a 2 X 2 + . . . + a n X n + b \hat\Theta=a_1X_1+a_2X_2+...+a_nX_n+b Θ^=a1X1+a2X2+...+anXn+b
写成矩阵形式:
Θ ^ = a X + b \hat\Theta=aX+b Θ^=aX+b
矩阵的计算方法是:最小均方误差就是 Θ ^ \hat\Theta Θ^到 Θ \Theta Θ距离的加权和。利用加权最小二乘法可以解决这个问题。
相应的最小均方误差为:
E [ ( Θ − Θ ^ ) 2 ] = E [ ( Θ − a 1 X 1 − a 2 X 2 + . . . − a n X n − b ) 2 ] E[(\Theta -\hat\Theta )^2]=E[(\Theta -a_1X_1-a_2X_2+...-a_nX_n-b )^2] E[(Θ−Θ^)2]=E[(Θ−a1X1−a2X2+...−anXn−b)2]
现在的问题就是把 a 1 , a 2 , . . . , a n , b a_1,a_2,...,a_n,b a1,a2,...,an,b当作未知数,求使整个式子取最小值时的 a 1 , a 2 , . . . , a n , b a_1,a_2,...,a_n,b a1,a2,...,an,b.
一元一次函数
先研究 n = 1 n=1 n=1时的情形,此时估计量: Θ ^ = a X + b \hat\Theta=aX+b Θ^=aX+b.
E [ ( Θ − a X − b ) 2 ] = v a r ( Θ − a X ) + [ E ( Θ − a X − b ) ] 2 E[(\Theta-aX-b)^2]=var(\Theta-aX)+[E(\Theta-aX-b)]^2 E[(Θ−aX−b)2]=var(Θ−aX)+[E(Θ−aX−b)]2
对于给定的a,常数b应该: b = E ( Θ − a X ) = E ( Θ ) − a E ( X ) b=E(\Theta -aX)=E(\Theta)-aE(X) b=E(Θ−aX)=E(Θ)−aE(X)
问题转化为:
E [ ( Θ − a X − E Θ + a E X ) 2 ] = v a r ( Θ − a X ) E[(\Theta-aX-E_{\Theta}+aE_{X})^2]=var(\Theta-aX) E[(Θ−aX−EΘ+aEX)2]=var(Θ−aX)
上面是个关于a的一元二次函数,求导数的零点即可得结果:
a = ρ ( Θ , X ) σ Θ σ X a=\rho (\Theta,X)\frac{\sigma _{\Theta}}{\sigma _{X}} a=ρ(Θ,X)σXσΘ
其中相关系数 ρ ( Θ , X ) = c o v ( Θ , X ) σ X σ Θ . \rho (\Theta,X)=\frac{cov(\Theta,X)}{\sigma _X\sigma _\Theta}. ρ(Θ,X)=σXσΘcov(Θ,X).
Θ ^ = a X + b = ρ σ Θ σ X X + μ Θ − ρ σ Θ σ X μ X \hat\Theta=aX+b=\rho \frac{\sigma _{\Theta}}{\sigma _{X}}X+\mu _\Theta -\rho\frac{\sigma _{\Theta}}{\sigma _{X}}\mu _X Θ^=aX+b=ρσXσΘX+μΘ−ρσXσΘμX
Θ ^ = ρ σ Θ σ X ( X − μ X ) + μ Θ = c o v ( Θ , X ) σ X 2 ( X − μ X ) + μ Θ \hat\Theta=\rho\frac{\sigma _{\Theta}}{\sigma _{X}}(X-\mu_X)+\mu_{\Theta}=\frac{cov(\Theta,X)}{\sigma _X^2}(X-\mu_X)+\mu_\Theta Θ^=ρσXσΘ(X−μX)+μΘ=σX2cov(Θ,X)(X−μX)+μΘ
理解:因为是估计 Θ \Theta Θ,所以先给一个基准常数 μ Θ \mu_\Theta μΘ.又因为已假定了 Θ ^ \hat\Theta Θ^与 X X X是线性关系,所以必然会出现相关系数 ρ \rho ρ。对于X只需要取其变化信息,所以采用 ( X − μ X ) (X-\mu_X) (X−μX)去掉 μ X \mu _X μX对于基准常数的影响。而 X X X方差很大时, ( X − μ X ) (X-\mu_X) (X−μX)也很大,方差很大的观测数据是不太好的,所以利用分母的 σ X 2 \sigma_X^2 σX2来抵消这种影响。
估计误差:
v a r ( Θ − Θ ^ ) = v a r ( Θ − a X − b ) = σ Θ 2 + a 2 σ X 2 − 2 a c o v ( X , Θ ) = ( 1 − ρ 2 ) σ Θ 2 var(\Theta-\hat\Theta)=var(\Theta-aX-b)=\sigma_\Theta^2+a^2\sigma_X^2-2acov(X,\Theta)=(1-\rho^2)\sigma_\Theta^2 var(Θ−Θ^)=var(Θ−aX−b)=σΘ2+a2σX2−2acov(X,Θ)=(1−ρ2)σΘ2
多观测值和多参数
与 n = 1 n=1 n=1的情形是类似的,只不过计算更为复杂。