NLP基础入门学习(代码详细解释)
一.imdb数据集下载和探索
我们将使用 IMDB 数据集,其中包含来自互联网电影数据库的 50000 条影评文本。我们将这些影评拆分为训练集(25000 条影评)和测试集(25000 条影评)。训练集和测试集之间达成了平衡,意味着它们包含相同数量的正面和负面影评。
1.数据集下载及可能出现的问题
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)
这里可能会遇到的问题是ValueError: Object arrays cannot be loaded when
allow_pickle=False,这里的原因是Numpy的版本是1.16.3这里我们需要把numpy的版本降低使用pip install numpy==1.16.2即可
2.查看和探索数据
#了解数据结构,每个样本都是一个整数数组,表示影评中的字词。每个标签都是整数值 0 或 1,其中 0 表示负面影评,1 表示正面影评。
print("Training entries: {}, labels: {}".format(len(train_data), len(train_labels)))
Training entries: 25000, labels: 25000
影评文本已转换为整数,(这里的数据预处理后面会说,先要有一个概念就是每个数字对应着一个词即可)其中每个整数都表示字典中的一个特定字词。第一条影评如下所示
print(train_data[0])
[1, 14, 22, 16, 43, 530, 973, 1622, 1385, 65, 458, 4468, 66, 3941, 4, 173, 36, 256, 5, 25, 100, 43, 838, 112, 50, 670, 2, 9, 35, 480, 284, 5, 150, 4, 172, 112, 167, 2, 336, 385, 39, 4, 172, 4536, 1111, 17, 546, 38, 13, 447, 4, 192, 50, 16, 6, 147, 2025, 19, 14, 22, 4, 1920, 4613, 469, 4, 22, 71, 87, 12, 16, 43, 530, 38, 76, 15, 13, 1247, 4, 22, 17, 515, 17, 12, 16, 626, 18, 2, 5, 62, 386, 12, 8, 316, 8, 106, 5, 4, 2223, 5244, 16, 480, 66, 3785, 33, 4, 130, 12, 16, 38, 619, 5, 25, 124, 51, 36, 135, 48, 25, 1415, 33, 6, 22, 12, 215, 28, 77, 52, 5, 14, 407, 16, 82, 2, 8, 4, 107, 117, 5952, 15, 256, 4, 2, 7, 3766, 5, 723, 36, 71, 43, 530, 476, 26, 400, 317, 46, 7, 4, 2, 1029, 13, 104, 88, 4, 381, 15, 297, 98, 32, 2071, 56, 26, 141, 6, 194, 7486, 18, 4, 226, 22, 21, 134, 476, 26, 480, 5, 144, 30, 5535, 18, 51, 36, 28, 224, 92, 25, 104, 4, 226, 65, 16, 38, 1334, 88, 12, 16, 283, 5, 16, 4472, 113, 103, 32, 15, 16, 5345, 19, 178, 32]
影评的长度可能会有所不同。以下代码显示了第一条和第二条影评中的字词数。由于神经网络的输入必须具有相同长度,因此我们稍后需要解决此问题
len(train_data[0]), len(train_data[1])
(218, 189)
3.根据字典的对应关系把数值转回词
word_index = imdb.get_word_index()
# The first indices are reserved
#遍历字典中的键值对返回一个列表
word_index = {k:(v+3) for k,v in word_index.items()}
word_index[""] = 0
word_index[""] = 1
word_index[""] = 2 # unknown
word_index[""] = 3
#这里是由于在数据预处理时是先用词对应的整数,因此要想获得词,需要把字典中的键值对翻转的得到从整数到词的映射
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
#获得所有i(key)对应的词(value)
def decode_review(text):
return ' '.join([reverse_word_index.get(i, '?') for i in text])
接下来要搭建模型进行训练,但是很重要的一点就是神经网络和SVM之间很重要的不同就是SVM的输入维度不一定都是要相同的(因为svm是直接定义一个kernel来计算内积,补充一下其实线性的SVM也可以进行梯度下降,原因是hinge loss最然不可积分,但是他是凸函数,在keras上可以进行gradient decent),这里我们就要标准化所有输入的维度
'''
value=word_index[""]就相当于value=0是用来填充的元素
padding,'可以选pre和post进行首尾0填充,truncating:‘pre’或‘post’,确定当需要截断序列时,从起始还是结尾截断 ,默认是pre
maxlen设置最大长度前面我们可以先打印数据长度来决定是padding还是truncating,但是这个我觉得有点问题,希望可以共同讨论
'''
train_data = keras.preprocessing.sequence.pad_sequences(train_data,
value=word_index[""],
padding='post',
maxlen=256)
test_data = keras.preprocessing.sequence.pad_sequences(test_data,
value=word_index[""],
padding='post',
maxlen=256)
现在,我们来看看样本的长度
len(train_data[0]), len(train_data[1])
(256, 256)
并检查(现已填充的)第一条影评:
print(train_data[0])
[ 1 14 22 16 43 530 973 1622 1385 65 458 4468 66 3941
4 173 36 256 5 25 100 43 838 112 50 670 2 9
35 480 284 5 150 4 172 112 167 2 336 385 39 4
172 4536 1111 17 546 38 13 447 4 192 50 16 6 147
2025 19 14 22 4 1920 4613 469 4 22 71 87 12 16
43 530 38 76 15 13 1247 4 22 17 515 17 12 16
626 18 2 5 62 386 12 8 316 8 106 5 4 2223
5244 16 480 66 3785 33 4 130 12 16 38 619 5 25
124 51 36 135 48 25 1415 33 6 22 12 215 28 77
52 5 14 407 16 82 2 8 4 107 117 5952 15 256
4 2 7 3766 5 723 36 71 43 530 476 26 400 317
46 7 4 2 1029 13 104 88 4 381 15 297 98 32
2071 56 26 141 6 194 7486 18 4 226 22 21 134 476
26 480 5 144 30 5535 18 51 36 28 224 92 25 104
4 226 65 16 38 1334 88 12 16 283 5 16 4472 113
103 32 15 16 5345 19 178 32 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0]
4.构建模型和训练
神经网络通过堆叠层创建而成,这需要做出两个架构方面的主要决策:
要在模型中使用多少个层?
要针对每个层使用多少个隐藏单元?
在本示例中,输入数据由字词-索引数组构成。要预测的标签是 0 或 1。接下来,我们为此问题构建一个模型:
# input shape is the vocabulary count used for the movie reviews (10,000 words)
vocab_size = 10000
model = keras.Sequential()
#NLP的word embedding, embedding只能作为第一层
model.add(keras.layers.Embedding(vocab_size, 16))
#平均池化
model.add(keras.layers.GlobalAveragePooling1D())
#过激活函数隐藏层用relu函数
model.add(keras.layers.Dense(16, activation=tf.nn.relu))
model.add(keras.layers.Dense(1, activation=tf.nn.sigmoid))
#获取模型所有参数
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, None, 16) 160000
_________________________________________________________________
global_average_pooling1d (Gl (None, 16) 0
_________________________________________________________________
dense (Dense) (None, 16) 272
_________________________________________________________________
dense_1 (Dense) (None, 1) 17
=================================================================
Total params: 160,289
Trainable params: 160,289
Non-trainable params: 0
_________________________________________________________________
损失函数和优化器
模型在训练时需要一个损失函数和一个优化器。由于这是一个二元分类问题且模型会输出一个概率(应用 S 型激活函数的单个单元层),因此我们将使用 binary_crossentropy (二分类的交叉熵)损失函数。
该函数并不是唯一的损失函数,例如,您可以选择 mean_squared_error。但一般来说,binary_crossentropy 更适合处理概率问题,它可测量概率分布之间的“差距”,在本例中则为实际分布和预测之间的“差距”。
稍后,在探索回归问题(比如预测房价)时,我们将了解如何使用另一个称为均方误差的损失函数。
现在,配置模型以使用优化器和损失函数:
model.compile(optimizer=tf.train.AdamOptimizer(),
loss='binary_crossentropy',
metrics=['accuracy'])
这里我说明一下Adam优化器他是集成了momentum优化器和RMS优化器的特点的一个适应性很好的优化器
创建验证集
在训练时,我们需要检查模型处理从未见过的数据的准确率。我们从原始训练数据中分离出 10000 个样本,创建一个验证集。(为什么现在不使用测试集?我们的目标是仅使用训练数据开发和调整模型,然后仅使用一次测试数据评估准确率。)
x_val = train_data[:10000]
partial_x_train = train_data[10000:]
y_val = train_labels[:10000]
partial_y_train = train_labels[10000:]
训练模型
用有 512 个样本的小批次训练模型 40 个周期。这将对 x_train 和 y_train 张量中的所有样本进行 40 次迭代。在训练期间,监控模型在验证集的 10000 个样本上的损失和准确率:
'''
训练模型用有 512 个样本的小批次训练模型 40 个周期。
verbose:日志显示,0为不在标准输出流输出日志信息,1为输出进度条记录,2为每个epoch输出一行记录
validation_split:0~1之间的浮点数,用来指定训练集的一定比例数据作为验证集。验证集将不参与训练,并在每个epoch结束后测试的模型的指标,如损失函数、精确度等。
validation_data:形式为(X,y)的tuple,是指定的验证集。此参数将覆盖validation_spilt。
'''
history = model.fit(partial_x_train,
partial_y_train,
epochs=40,
batch_size=512,
validation_data=(x_val, y_val),
verbose=1)
下面进行模型评估,计算在测试集上的准确率
results = model.evaluate(test_data, test_labels)
print(results)
25000/25000 [==============================] - 1s 35us/step
[0.32395469411849975, 0.87264]
5.进行模型指标的可视化
model.fit() 返回一个 History 对象,该对象包含一个字典,其中包括训练期间发生的所有情况:
history_dict = history.history
history_dict.keys()
dict_keys(['loss', 'val_loss', 'val_acc', 'acc'])
一共有 4 个条目:每个条目对应训练和验证期间的一个受监控指标。我们可以使用这些指标绘制训练损失与验证损失图表以进行对比,并绘制训练准确率与验证准确率图表:
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
# "bo" is for "blue dot"
plt.plot(epochs, loss, 'bo', label='Training loss')
# b is for "solid blue line"
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
plt.clf() # clear figure
acc_values = history_dict['acc']
val_acc_values = history_dict['val_acc']
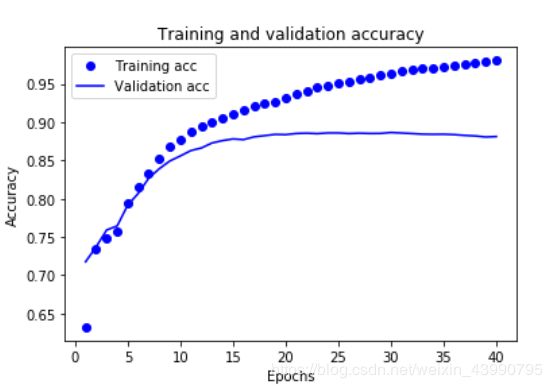
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
2.THUCNews数据集下载和探索代码讲解(这里只说一下数据集预处理也是最重要的)
1.将文本整合到 train、test、val 三个文件中
import os
#删除文本中的换行符,tab,和中文的全角符号
def _read_file(filename):
with open(filename, 'r', encoding='utf-8') as f:
return f.read().replace('\n', '').replace('\t', '').replace('\u3000', '')
#这里的文件就相当于有一个总的文件夹,文件夹下有很多词的分类,每一个类别的下面是词
def save_file(dirname):
f_train = open('data/cnews/cnews.train.txt', 'w', encoding='utf-8')
f_test = open('data/cnews/cnews.test.txt', 'w', encoding='utf-8')
f_val = open('data/cnews/cnews.val.txt', 'w', encoding='utf-8')
for category in os.listdir(dirname):
#把原始目录的路径再加上分类目录路径
cat_dir = os.path.join(dirname, category)
if not os.path.isdir(cat_dir): #判断是不是路径不是则跳出本次循环
continue
files = os.listdir(cat_dir) #打开文件访问每个类别下的词,返回一个词的列表
count = 0
for cur_file in files: #遍历这个列表下的每一个词
filename = os.path.join(cat_dir, cur_file) #获取每个词的路径
content = _read_file(filename) #获取词的列表(一类词的集合)
if count < 5000:
#每一个类别和她对应的内容写入文件5000的训练集
f_train.write(category + '\t' + content + '\n')
elif count<6000:
f_test.write(category + '\t' + content + '\n')
else:
f_val.write(category + '\t' + content + '\n')
count += 1
print('Finished:', category)
f_train.close()
f_test.close()
f_val.close()
if __name__ == '__main__':
save_file('data/thucnews')
print(len(open('data/cnews/cnews.train.txt', 'r', encoding='utf-8').readlines()))
print(len(open('data/cnews/cnews.test.txt', 'r', encoding='utf-8').readlines()))
print(len(open('data/cnews/cnews.val.txt', 'r', encoding='utf-8').readlines()))
2.数据预处理(代码讲解)
import sys
from collections import Counter
import numpy as np
import tensorflow.keras as kr
#这里是pythom2,3之间的相互转换
if sys.version_info[0] > 2:
is_py3 = True
else:
reload(sys)
sys.setdefaultencoding("utf-8")
is_py3 = False
#获取词
def native_word(word, encoding='utf-8'):
"""如果在python2下面使用python3训练的模型,可考虑调用此函数转化一下字符编码"""
if not is_py3:
return word.encode(encoding)
else:
return word
#获取词的列表
def native_content(content):
if not is_py3:
return content.decode('utf-8')
else:
return content
#打开文件,主要是考虑python版本
def open_file(filename, mode='r'):
if is_py3:
return open(filename, mode, encoding='utf-8', errors='ignore')
else:
return open(filename, mode)
def read_file(filename):
contents, labels = [], []
with open_file(filename) as f:
for line in f:
try:
label, content = line.strip().split('\t')#前面处理把用的\t
if content:
contents.append(list(native_content(content))) #把content元素加入contents中内部的函数完全是考虑版本不用多看
labels.append(native_content(label))
except:
pass
return contents, labels
def build_vocab(train_dir, vocab_dir, vocab_size=5000):
data_train, _ = read_file(train_dir)#获取数据data 即content
all_data = []
for content in data_train:
all_data.extend(content) #把datatrain里面的元素加入alldata里面
'''
Counter类的目的是用来跟踪值出现的次数。它是一个无序的容器类型,以字典的键值对形式存储,
其中元素作为key,其计数作为value。计数值可以是任意的Interger(包括0和负数)。
Counter类和其他语言的bags或multisets很相似。
'''
counter = Counter(all_data)
count_pairs = counter.most_common(vocab_size - 1) #返回每一个词出现的次数
words, _ = list(zip(*count_pairs))
# 添加一个 来将所有文本pad为同一长度
words = [''] + list(words)
open_file(vocab_dir, mode='w').write('\n'.join(words) + '\n')#待修改
def read_vocab(vocab_dir):
with open_file(vocab_dir) as fp:
#把返回的列表前后的空格转义字符和其他东西去除只留下词
words = [native_content(_.strip()) for _ in fp.readlines()]
#这里就是前面提到的字典内词对应的整数,最后要反转
word_to_id = dict(zip(words, range(len(words))))#把词和他的位置对应起来构建一个字典
return words, word_to_id
def read_category():
"""读取分类目录,固定"""
categories = ['体育', '财经', '房产', '家居', '教育', '科技', '时尚', '时政', '游戏', '娱乐']
categories = [native_content(x) for x in categories] #返回每一个类别
#把类别和对应的id(数字)对应起来
cat_to_id = dict(zip(categories, range(len(categories))))
return categories, cat_to_id
def to_words(content, words):
return ''.join(words[x] for x in content) #把content
def process_file(filename, word_to_id, cat_to_id, max_length=600):
"""将文件转换为id表示"""
contents, labels = read_file(filename)
data_id, label_id = [], []
for i in range(len(contents)):
data_id.append([word_to_id[x] for x in contents[i] if x in word_to_id]) #把之前字典中的值(也就是每个数字)加到data_id里
label_id.append(cat_to_id[labels[i]])
#进行0填充
x_pad = kr.preprocessing.sequence.pad_sequences(data_id, max_length)
y_pad = kr.utils.to_categorical(label_id, num_classes=len(cat_to_id)) # 将标签转换为one-hot表示
return x_pad, y_pad
def batch_iter(x, y, batch_size=64):
""生成批次数据"""
data_len = len(x)
num_batch = int((data_len - 1) / batch_size) + 1
indices = np.random.permutation(np.arange(data_len))#打乱数据,相比于shuffle permutation有返回值
x_shuffle = x[indices]
y_shuffle = y[indices]
for i in range(num_batch):
start_id = i * batch_size
end_id = min((i + 1) * batch_size, data_len)
yield x_shuffle[start_id:end_id], y_shuffle[start_id:end_id] # 这里的yield相当于一个return+generate返回每一段的数据
3.召回率、准确率、ROC曲线、AUC、PR曲线这些基本概念
1.精确率和召回率
精确率,又称查准率(Precision):正样本的预测数/被预测为正样本的数量(注意:精确率和准确率不同),即:
P=TP/(TP+FP) P=TP/(TP+FP)
P=TP/(TP+FP)
召回率(Recall)又称查全率:分类正确的正样本个数占正样本个数的比例,即:
R=TPTP+FN R=TPTP+FN
R=TPTP+FN
2.ROC曲线常用于二分类问题中的模型比较,主要表现为一种真正例率 (TPR) 和假正例率 (FPR) 的权衡。
具体方法是在不同的分类阈值 (threshold) 设定下分别以TPR和FPR为纵、横轴作图。由ROC曲线的两个指标,
TPR=TP/P=TP/(TP+FN) TPR=TP/P=TP/(TP+FN)
TPR=TP/P=TP/(TP+FN)
,
FPR=FP/N=FP/(FP+TN) FPR=FP/N=FP/(FP+TN)
FPR=FP/N=FP/(FP+TN)
可以看出:
当一个样本被分类器判为正例,若其本身是正例,则TPR增加;若其本身是负例,则FPR增加,因此ROC曲线可以看作是随着阈值的不断移动,所有样本中正例与负例之间的“对抗”。
曲线越靠近左上角,意味着越多的正例优先于负例,模型的整体表现也就越好。
3.AUC曲线(Area Under the Curve)
对不同的ROC曲线进行比较的一个指标是曲线下的面积(Area Under Curve,AUC),曲线下面积(AUC)是评估中使用最广泛的指标之一。 它用于二分类问题。分类器的AUC等价于分类器随机选择正样本高于随机选择负样本的概率。 在定义AUC之前,让我们理解两个基本术语:
AUC(Area Under Curve)的值为ROC曲线下面的面积,若如上所述模型十分准确,则AUC为1。
但现实生活中尤其是工业界不会有如此完美的模型,一般AUC均在0.5到1之间,AUC越高,模型的区分能力越好
若AUC=0.5,即与上图中虚线重合,表示模型的区分能力与 随机猜测 没有差别。若AUC真的小于0.5,请检查一下是不是好坏标签标反了,或者是模型真的很差。
PR (Precision Recall) 曲线
PR曲线展示的是Precision vs Recall的曲线,PR曲线与ROC曲线的相同点是都采用了TPR (Recall),都可以用AUC来衡量分类器的效果。不同点是ROC曲线使用了FPR,而PR曲线使用了Precision,因此PR曲线的两个指标都聚焦于正例。
类别不平衡问题中由于主要关心正例,所以在此情况下PR曲线被广泛认为优于ROC曲线。