基于知识图谱的问答系统2【代码学习系列】【知识图谱】【问答系统】
1 代码来源
本代码来源于github项目地址,主要是构建以疾病为中心的具有一定规模的医药领域知识图谱,并以该知识图谱完成自动问答与分析服务。与github项目地址基本相同,参见我的博客基于知识图谱的问答系统1,不同之处主要在于问句中实体的提取和意图的识别,问答系统1中采用的是简单的模板匹配,本项目对实体提取在原有硬匹配的基础上增加了近似匹配,对于意图识别,则采用朴素贝叶斯分类进行意图的分类,并进一步进行模板匹配。因此,这里主要对实体提取和意图识别进行详细说明,项目其他部分内容,可参见基于知识图谱的问答系统1。

2 实体提取
实体提取在原有硬匹配的基础上,进行相似匹配,如果硬匹配没有结果,则进一步进行相似度匹配。相似匹配则通过求解输入语句词组与实体特征词间的字重叠率、词向量余弦相似度和DP编辑距离三个指标的平均值,作为与实体特征词的相似度,选取相似度最大且大于0.7的实体特征词作为输入语句的实体提取结果。主要技术点有基于词向量的余弦相似度计算和DP编辑距离。
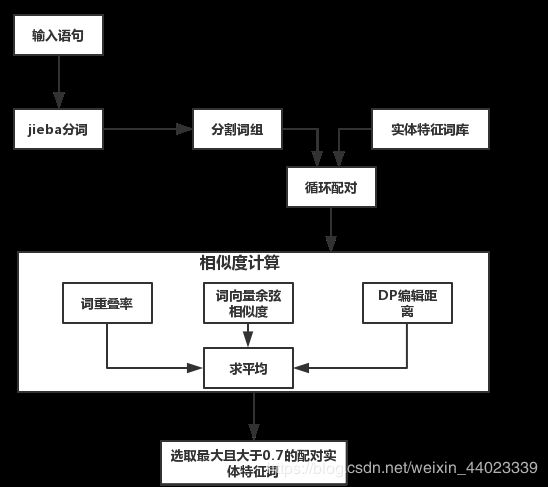
(1) 字重叠率
对于选取的输入语句分割词和实体特征库特征词,计算输入语句分割词的字与特征词的字重叠比例。
// An highlighted block
c = len(set(entity+word))
for w in word: #word是一个词,w表示一个字
if w in entity: #entity是一个词,某类实体的某一个特征词
sim_num += 1
if sim_num != 0:
score1 = sim_num / c # overlap score
temp.append(score1);(2) 词向量余弦相似度
该指标主要利用gensim模块,通过构建语料库,采用word2vec生成词向量,然后基于word2vec,计算输入语句分割词和实体特征库特征词的余弦相似度。项目中没有给出语料库和word2vec生成词向量的训练过程,直接给出了word2vec模型。相关资料可以参见:用gensim学习word2vec(刘建平Pinard),gensim训练word2vec及相关函数与功能理解,gensim训练word2vec及相关函数与功能理解等。
// An highlighted block
from gensim.models import KeyedVectors
self.model = KeyedVectors.load_word2vec_format(self.word2vec_path, binary=False)
score2 = self.model.similarity(word, entity) (3) DP编辑距离
经典问题,可参照编辑距离DP算法。
// An highlighted block
def editDistanceDP(self, s1, s2):
m = len(s1)
n = len(s2)
solution = [[0 for j in range(n + 1)] for i in range(m + 1)]
for i in range(len(s2) + 1):
solution[0][i] = i
for i in range(len(s1) + 1):
solution[i][0] = i
for i in range(1, m + 1):
for j in range(1, n + 1):
if s1[i - 1] == s2[j - 1]:
solution[i][j] = solution[i - 1][j - 1]
else:
solution[i][j] = 1 + min(solution[i][j - 1], min(solution[i - 1][j], solution[i - 1][j - 1]))
return solution[m][n]3 意图分类
意图分类则采用朴素贝叶斯机器学习方法,实际包括特征提取、模型训练、意图预测三部分,项目仅给出了部分特征提取和意图预测代码,没有给出tfidf特征训练和分类模型训练内容,直接给出了模型。
(1) 特征提取
特征包括tfidf特征和其他类特征,其中其他类特征根据问题特征词在问句中出现的比例得到,tfidf特征则采用sklearn模块TfidfVectorizer模型,通过语料库训练得到,项目直接给出了TfidfVectorizer模型,没给出训练过程。
tfidf特征可参见资料sklearn: TfidfVectorizer 中文处理及一些使用参数,使用不同的方法计算TF-IDF值,使用scikit-learn tfidf计算词语权重。
// An highlighted block
from sklearn.externals import joblib
import jieba
self.tfidf_model = joblib.load(self.tfidf_path)
self.nb_model = joblib.load(self.nb_path)
// 计算tfidf特征函数
def tfidf_features(self, text, vectorizer):
jieba.load_userdict(self.vocab_path)
words = [w.strip() for w in jieba.cut(text) if w.strip() and w.strip() not in self.stopwords]
sents = [' '.join(words)]
tfidf = vectorizer.transform(sents).toarray()
return tfidf
// 计算其他特征函数
def other_features(self, text):
features = [0] * 7
for d in self.disase_qwds:
if d in text:
features[0] += 1
...
m = max(features)
n = min(features)
normed_features = []
if m == n:
normed_features = features
else:
for i in features:
j = (i - n) / (m - n)
normed_features.append(j)
// 计算特征并合并特征
tfidf_feature = self.tfidf_features(question, self.tfidf_model)
other_feature = self.other_features(question)
m = other_feature.shape
other_feature = np.reshape(other_feature, (1, m[0]))
feature = np.concatenate((tfidf_feature, other_feature), axis=1)(2) 模型训练
基于语料库,标注10类意图训练数据库,采用朴素贝叶斯方法,基于提取特征,训练生成意图识别模型。可参见Python机器学习 — 朴素贝叶斯算法(Naive Bayes)。
(3) 意图预测
基于特征向量,直接用朴素贝叶斯模型进行预测。
// An highlighted block
from sklearn.externals import joblib
self.nb_model = joblib.load(self.nb_path)
predicted = self.model_predict(feature, self.nb_model)4 总结
该项目相对于基于知识图谱的问答系统1,具有一定改进,具备模糊匹配能力,但意图预测性能受限于语料库大小。