用python爬虫制作图片下载器(超有趣!)
这几天小菌给大家分享的大部分都是关于大数据,linux方面的"干货"。有粉丝私聊小菌,希望能分享一些有趣的爬虫小程序。O(∩_∩)O哈哈,是时候露一手了。今天给大家分享的是一个适合所有爬虫爱好者训练的一个有趣的项目—百度图片下载器。这个下载器的优势在于,可以根据你自定义关键字的输入,去百度图片上快速的获取相关的图片,并保存在本地,可谓是十分之便捷了~话不多说,直接上代码ヾ(●´∀`●)
# -*- encoding: utf-8 -*-
"""
@File : 图片自动下载器(百度图片).py
@Time : 2019/10/22 8:38
@Author : 封茗囧菌
@Software: PyCharm
转载请注明原作者
创作不易,仅供分享
"""
import requests
import re
import os
# 定义一个变量用来保存下载图片的张数
i = 1
# 定义下载图片的方法
def downloadPic(url):
global i # 使用global声明这是一个全局变量,方法内无法直接使用全局变量
html = requests.get(url).text
pic_url = re.findall('"objURL":"(.*?)",', html, re.S)
for each in pic_url:
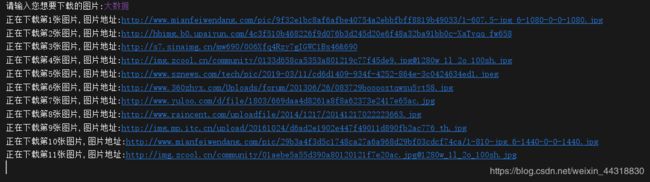
print("正在下载第" + str(i) + "张图片,图片地址:" + each)
try:
pic = requests.get(each, timeout=5) # 可能有些图片存在网址打不开的情况,这里设置一个5秒的超时控制
except Exception: # 出现异常直接跳过
print("【错误】当前图片无法下载")
continue # 跳过本次循环
# 定义变量保存图片的路径
string = 'G:/Python/Crawler/百度图片下载器/' + word + "/" + str(i) + ".jpg"
fp = open(string, 'wb')
fp.write(pic.content)
fp.close()
i += 1
if __name__ == '__main__': # 主程序
word = input("请输入您想要下载的图片:")
# 先根据搜索的关键字判断存放该类别的文件夹是否存在,不存在则创建
road = "G:/Python/Crawler/百度图片下载器/" + word
if not os.path.exists(road):
os.mkdir(road)
# 根据输入的内容构建url列表推导式【前21页内容】
urls = [
'http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=' + word + '&ct=201326592&v=flip&pn={}'.format(
str(i)) for i in range(0, 400, 20)]
for url in urls:
downloadPic(url)
print("下载完成!")
运行效果图如下:
我们先输入想要查找的关键字,然后回车,切换到指定的目录下,就会发现一张张图片像蜂拥似的出现在你的本地目录上(当然,速度有多快取决于你的网速)。上面的爬虫代码中,小菌设置的是百度图片中大概20页的内容,也就是以前一千两百多张图。小伙伴们可根据需求自行修改。
因为该程序的代码本身比较简单,只要是爬虫爱好者基本都能看得懂,因此小菌就不再详细往下讲。本次的分享就到这里了,有疑惑的小伙伴或者有什么好的建议可以在评论区积极留言,小菌都会尽量回复。认为有帮助的小伙伴们不要忘了点赞,如果再来个关注就更好了(灬°ω°灬)