【聊天机器人】深度学习构建检索式聊天机器人原理
一、检索式与生成式聊天机器人对比
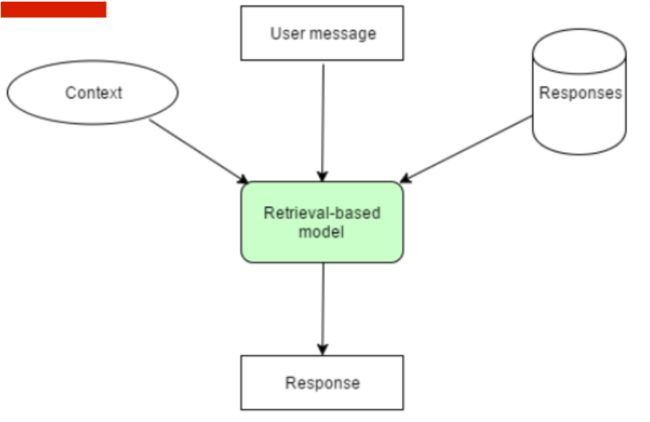
1、基于检索的chatterbot
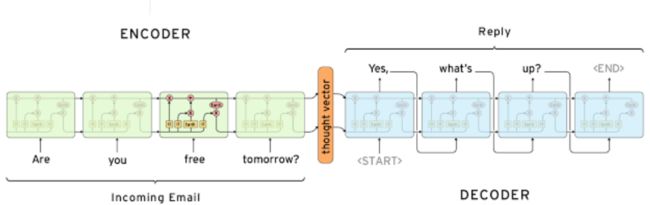
2、基于生成的chatterbot
3、聊天机器人的一些思考:
(1)基于检索的chatterbot
- 根据input和context,结合知识库的算法得到合适回复。
- 从一个固定的数据集中找到合适的内容作为回复
- 检索和匹配的方式有很多种(可以基于机器学习判断属于那种类型的匹配,利用关键字+word2vec进行文本相似度匹配)
- 数据和匹配方法对质量有很大影响
(2)基于生成模型的chatterbot
- 典型的是用seq2seq方法
- 生成的结果需要考虑通畅度和准确度
- 深度学习是学习数据的特征。对于认为很重要的特征,可以最后在全连接层时进行矩阵拼接加入,而不参与特征之间的学习,以免造成影响。
以前者为主,后者为辅;检索方法过程中当模型需要算法是,可以考虑加入深度学习。
4、chatterbot的问题
(1)应答模式的匹配方法太粗暴
- 编辑距离无法捕获深层语义信息
- 核心词+word2vec无法捕获整句话语义(对于我 爱 你和你 爱 我,词向量表示是一样的)
- LSTM等RNN模型能捕获序列信息
- 用深度学习来提高匹配阶段准确率
(2)特定领域+检索+合适的知识库能做到还不错。但开放域比较难
5、转化为机器学习或深度学习能够解决的问题,应该怎么做
(1)匹配本身是一个模糊的场景
转成排序问题
(2)排序问题怎么处理?
转成能输出概率的01分类
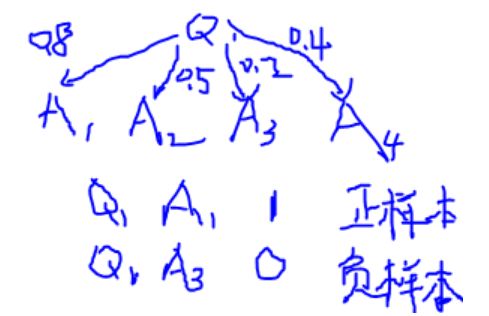
(3)数据构建?
需要正样本(正确的答案)和负样本(不对的答案)
(4)Loss function
分类问题采用对数损失(二元的交叉熵损失)
 )
)
二、使用深度学习完成问答:
1、论文
IMPLEMENTING A RETRIEVAL-BASED MODEL IN TENSORFLOW,WILDML BLOG,2016
2、论文框架图
三、深度学习问答数据
1、中文:
Microsoftz做法是,从其他不同的场景里,以相同的概率抽取答案,成为负样本。当前场景的问答作为正样本。
2、Ubuntu对话语料库:
(1)训练集:
- Ubuntu对话数据集,来自Ubuntu的IRC网络上的对话日志
- 训练集1000000条实例,一半是正例(label为1),一半是负例(label为0,负例为随机生成)
- 样本包括上下文信息(context,即Query)和一段可能的回复内容,即Response;Label为1表示Response和Query的匹配,Label为0表示不匹配
- query的平均长度为86个word,而response的平均长度为17个word。
(2)验证集/测试集:
- 每个样本有一个正样本和9个负样本(也称为干扰样本)
- 建模的目标是给正例的得分尽可能高(排序越靠前),而负例的得分尽可能低(有点类似分类问题)
- 语料做过分词、stemmed、lemmatized等文本预处理
- 用NER(命名实体识别)将文本中的实体,如姓名、地点、组织、URL等替换成特殊字符。
(3)评估准则:
- recall@k(在前k个位置,能够找回标准答案的概率有多高)
- 经模型对候选的response排序后,前k个候选中存在正例数据(正确的那个)的占比
- k值越高,指标值越高,对模型性能的要求越松。
四、基线模型代码实现:
import pandas as pd
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
#导入数据
train_df = pd.read_csv("../data/train.csv")
test_df = pd.read_csv("../data/test.csv")
validation_df = pd.read_csv("../data/valid.csv")
y_test = np.zeros(len(test_df))
#定义评估指标
def evaluate_recall(y,y_test,k=n):
num_examples = float(len(y))
num_correct = 0
for predictions,label in zip(y,y_test):
if label in predictions[:k]:
num_correct += 1
return num_correct/num_examples
#从len(utterances)中随机抽取数字,生成size=10的数组
1、基线模型:
#定义随机预测函数
#从len(utterances)中随机抽取数字,生成size=10的数组
#replace:True表示可以取相同数字,False表示不可以取相同数字
def predict_random(context,utterances):
return np.random.choice(len(utterances),10,replace=False)
#生成随机预测结果
y_random = [predict_random(test_df.Context[x],test_df.iloc[x,1:].values) for x in range(len(test_df))]
#对前k=1,2,5,10分别进行评存在的正样本概率评估
for n in [1,2,5,10]:
print(f'Recall @ ({n},10):{evaluate_recall(y_random,y_test,n):g}')
输出结果:
Recall @ (1,10):0.0992072
Recall @ (2,10):0.199313
Recall @ (5,10):0.50037
Recall @ (10,10):1
2、基线模型:TF-IDF检索
class TFIDFPredictor():
def __init__(self):
self.vectorizer = TfidfVectorizer()
def train(self, data):
self.vectorizer.fit(np.append(data.Context.values,data.Utterance.values))
def predict(self,context,utterances):
#将输入问题Q转化为向量
vector_context = self.vectorizer.transform([context])
#将回答A转化为向量
vector_doc = self.vectorizer.transform(utterances)
#将回答向量与问题向量做矩阵相乘
result = np.dot(vector_doc,vector_context.T).todense()
result = np.asarray(result).flatten()
##将result中的元素从小到大排列,提取其对应的index(索引)。再将索引进行倒叙排列(越在前面,概率越大)
#argsort
return np.argsort(result,axis=0)[::-1]
pred = TFIDFPredictor()
pred.train(train_df)
y = [pred.predict(test_df.Context[x],test_df.iloc[x,1:].values) for x in range(len(test_df))]
for n in [1,2,5,10]:
print(f'Recall @ ({n},10):{evaluate_recall(y,y_test,n):g}')
输出结果:
Recall @ (1,10):0.485624
Recall @ (2,10):0.586681
Recall @ (5,10):0.762474
Recall @ (10,10):1
五、神经网络建模原理
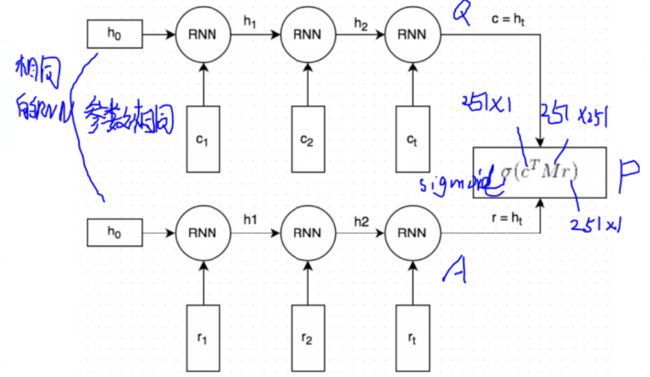
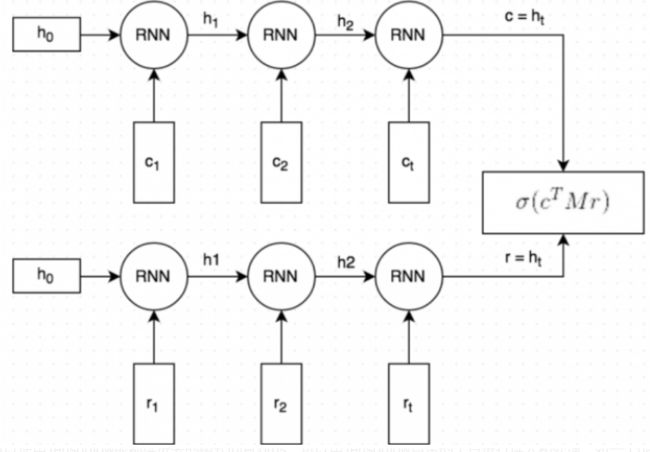
1、Query 和Response都是经过分词和embedding映射的。初始向量使用GloVe/word2vec
2、分词且向量化的Query和Response经过相同的RNN(word by word)(同一组参数)。RNN最终生成一个向量表示,捕捉了Query和Reponse之间的【语义联系】(图中的c和r);这个
向量的维度是可以指定的,这里指定为256维。
3、将向量c与一个矩阵M相乘,来预测一个可能的回复r‘。如果c为一个256维的向量,M维是256*256的矩阵,两者相乘的结果为另一个256维向量,我们可以将其解释为【一个生成式的回复向量】。矩阵M是需要训练的参数
4、通过点乘的方式来预测生成的回复r’和候选的回复r之间的相似程度,点乘结果越大表示候选回复最为回复的可信度越高;之后通过sigmoid函数归一化,转成概率形式。(sigmoid作为压缩函数经常使用)
5、损失函数:二元的交叉熵函数/对数函数。回想逻辑回归,交叉熵损失函数为L = -y * ln(y’)- (1 - y) * ln(1 - y’)。(公式的意义是直观的,即当y=1时,L=-ln(y’),我们希望y’尽量接近1,使得损失韩式的值越小‘反之亦然。)
使用Tensorflow的话训练速度主要受2方面影响。一、读数据(例如,训练数据是512兆的文本数据,100w个长文本。是很大的数据集),开销会很大。可以使用Tensorflow能都读进去的格式tdrecords。可以用Tensorflow自带的工具进行读入和处理。如一个batch或构建一个队列。二、GPU处理的速度。可以构建一个队列 query,在队列里不断去数据,以跟的上入读数据的速度。
神经网络代码实现在下篇文章中具体阐述