Ceph MDS问题分析
1. 问题背景
1.1 客户端缓存问题
$ ceph -s
health HEALTH_WARN
mds0: Client xxx-online00.gz01 failing to respond to cache pressure
官方解释
消息: “Client name failing to respond to cache pressure”
代码: MDS_HEALTH_CLIENT_RECALL, MDS_HEALTH_CLIENT_RECALL_MANY
描述:
客户端有各自的元数据缓存,客户端缓存中的条目(比如索引节点)也会存在于 MDS 缓存中,所以当 MDS 需要削减其缓存时(保持在 mds_cache_size 以下),它也会发消息给客户端让它们削减自己的缓存。如果有客户端没响应或者有缺陷,就会妨碍 MDS 将缓存保持在 mds_cache_size 以下, MDS 就有可能耗尽内存而后崩溃。如果某个客户端的响应时间超过了 mds_recall_state_timeout (默认为 60s ),这条消息就会出现。
1.2 服务端内存不释放
同上参考1.1 客户端缓存问题
1.3 mds session的inode过多
客户端session的inode太多,导致内存很高,从而也导致主从mds切换加载inode慢,严重影响服务的可用性。
1.4 mds夯住问题或慢查询
- 客户端搜索遍历查找文件(不可控)
- session的 inode太大导致mds负载过高
- 日志级别开的太大,从而导致mds负载高
2. 分析思路
上面的几个问题都是有一定的联系,互相影响的。所以,我们先从已知的方向逐步深入分析问题,从而优化解决问题。
2.1 组件通信流程图
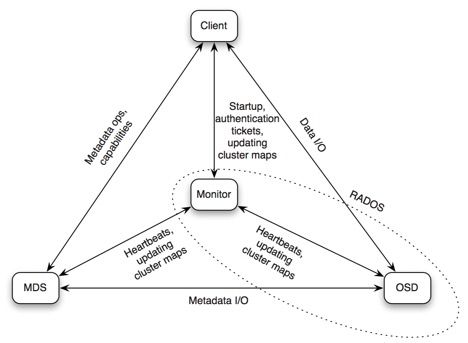
- Client <–> MDS
元数据操作和capalities - Client <–> OSD
数据IO - Client <–> Monitor
认证,集群map信息等 - MDS <–> Monitor
心跳,集群map信息等 - MDS <–> OSD
元数据IO - Monitor <–> OSD
心跳,集群map信息等
2.2 查看客户端session
$ ceph --admin-daemon /var/run/ceph/ceph-mds.ceph-xxxx-osd02.py.asok session ls
[
{
"id": 5122511,
"num_leases": 0,
"num_caps": 655,
"state": "open",
"replay_requests": 0,
"completed_requests": 1,
"reconnecting": false,
"inst": "client.5122511 192.168.1.2:0\/2026289820",
"client_metadata": {
"ceph_sha1": "b1e0532418e4631af01acbc0cedd426f1905f4af",
"ceph_version": "ceph version 0.94.10 (b1e0532418e4631af01acbc0cedd426f1905f4af)",
"entity_id": "log_xxx_cephfs",
"hostname": "ceph-test-osd02",
"mount_point": "\/mnt\/log"
}
}
]
说明:
- id:client唯一id
- num_caps:client获取的caps
- inst:client端的ip和端口链接信息
- ceph_version:client端的ceph-fuse版本,若使用kernel client,则为kernel_version
- hostname:client端的主机名
- mount_point:client在主机上对应的mount point
- pid:client端ceph-fuse进程的pid
2.3 查看客户端的inode数量
跟踪代码发现session里面的num_caps就是统计的客户端的inode数量, 大概统计了下已经打开的inode数量在400w左右。

总结:
可以查看客户端的session信息,包含host、mount、inode等信息
可以统计所有客户端session的inode数量。
2.4 尝试mds主从切换
2.4.1 执行过程如下
2018-04-27 19:24:03.923349 7f53015d7700 1 mds.0.2738 handle_mds_map state change up:boot --> up:replay
2018-04-27 19:24:03.923356 7f53015d7700 1 mds.0.2738 replay_start
2018-04-27 19:24:03.923360 7f53015d7700 1 mds.0.2738 recovery set is
2018-04-27 19:24:03.923365 7f53015d7700 1 mds.0.2738 waiting for osdmap 6339 (which blacklists prior instance)
2018-04-27 19:24:03.948526 7f52fc2ca700 0 mds.0.cache creating system inode with ino:100
2018-04-27 19:24:03.948675 7f52fc2ca700 0 mds.0.cache creating system inode with ino:1
2018-04-27 19:24:04.238128 7f52fa2b8700 1 mds.0.2738 replay_done
2018-04-27 19:24:04.238143 7f52fa2b8700 1 mds.0.2738 making mds journal writeable
2018-04-27 19:24:04.924352 7f53015d7700 1 mds.0.2738 handle_mds_map i am now mds.0.2738
2018-04-27 19:24:04.924357 7f53015d7700 1 mds.0.2738 handle_mds_map state change up:replay --> up:reconnect
2018-04-27 19:24:04.924370 7f53015d7700 1 mds.0.2738 reconnect_start
2018-04-27 19:24:04.924371 7f53015d7700 1 mds.0.2738 reopen_log
2018-04-27 19:24:04.924380 7f53015d7700 1 mds.0.server reconnect_clients -- 19 sessions
2018-04-27 19:24:04.926357 7f53015d7700 0 log_channel(cluster) log [DBG] : reconnect by client.4375 192.168.1.3:0/1796553051 after 0.001950
2018-04-27 19:24:04.926429 7f53015d7700 0 log_channel(cluster) log [DBG] : reconnect by client.4403 192.168.1.3:0/1032897847 after 0.002036
2018-04-27 19:24:15.228507 7f53015d7700 1 mds.0.2738 reconnect_done
2018-04-27 19:24:15.984143 7f53015d7700 1 mds.0.2738 handle_mds_map i am now mds.0.2738
2018-04-27 19:24:15.984148 7f53015d7700 1 mds.0.2738 handle_mds_map state change up:reconnect --> up:rejoin
2018-04-27 19:24:15.984156 7f53015d7700 1 mds.0.2738 rejoin_start
2018-04-27 19:25:15.987531 7f53015d7700 1 mds.0.2738 rejoin_joint_start
2018-04-27 19:27:40.105134 7f52fd4ce700 1 mds.0.2738 rejoin_done
2018-04-27 19:27:42.206654 7f53015d7700 1 mds.0.2738 handle_mds_map i am now mds.0.2738
2018-04-27 19:27:42.206658 7f53015d7700 1 mds.0.2738 handle_mds_map state change up:rejoin --> up:active
2018-04-27 19:27:42.206666 7f53015d7700 1 mds.0.2738 recovery_done -- successful recovery!
主从切换流程:
- handle_mds_map state change up:boot --> up:replay
- handle_mds_map state change up:replay --> up:reconnect
- handle_mds_map state change up:reconnect --> up:rejoin
- handle_mds_map state change up:rejoin --> up:active
up:boot
- 此状态在启动期间被广播到CEPH监视器。这种状态是不可见的,因为监视器立即将MDS分配给可用的秩或命令MDS作为备用操作。这里记录了完整性的状态。
up:replay
- 日志恢复阶段,他将日志内容读入内存后,在内存中进行回放操作。
up:reconnect
- 恢复的mds需要与之前的客户端重新建立连接,并且需要查询之前客户端发布的文件句柄,重新在mds的缓存中创建一致性功能和锁的状态。
mds不会同步记录文件打开的信息,原因是需要避免在访问mds时产生多余的延迟,并且大多数文件是以只读方式打开。
up:rejoin
- 把客户端的inode加载到mds cache。(耗时最多的地方)
为什么mds切换耗时比较高?
- 分析日志(发现执行rejoin_start,rejoin_joint_start动作耗时比较高)
2018-04-27 19:24:15.984156 7f53015d7700 1 mds.0.2738 rejoin_start
2018-04-27 19:25:15.987531 7f53015d7700 1 mds.0.2738 rejoin_joint_start
2018-04-27 19:27:40.105134 7f52fd4ce700 1 mds.0.2738 rejoin_done
2018-04-27 19:27:42.206654 7f53015d7700 1 mds.0.2738 handle_mds_map i am now mds.0.2738
2018-04-27 19:27:42.206658 7f53015d7700 1 mds.0.2738 handle_mds_map state change up:rejoin --> up:active
-
跟踪代码分析(在执行process_imported_caps超时了, 这个函数主要是打开inodes 加载到cache中)
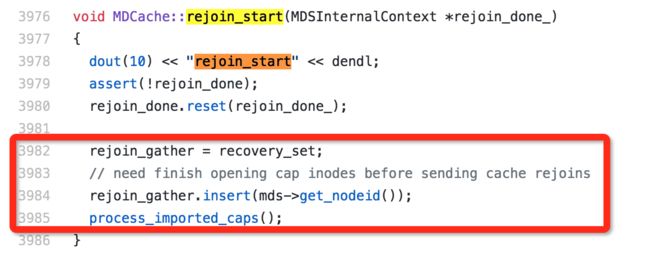 image.png
image.png
总结:
- 主从切换时mds详细状态
- 主从切换时主要耗时的阶段rejoin_start,加载客户端session的inode信息
2.5 释放客户端inode
2.5.1 模拟客户端session inode过多
- 查看客户端session信息
#查看客户端session的inode数量, num_caps:7
$ ceph daemon mds.ceph-xxx-osd01.ys session ls
[
{
"id": 554418,
"num_leases": 0,
"num_caps": 7,
"state": "open",
"replay_requests": 0,
"completed_requests": 0,
"reconnecting": false,
"inst": "client.554418 192.168.1.2:0/1285681097",
"client_metadata": {
"ceph_sha1": "fe3a2269d799a8b950404cb2de11af84c7af0ea4",
"ceph_version": "didi_dss version 12.2.2.4 (fe3a2269d799a8b950404cb2de11af84c7af0ea4) luminous (stable)",
"entity_id": "admin",
"hostname": "ceph-xxx-osd01.ys",
"mount_point": "/mnt",
"pid": "2084",
"root": "/"
}
}
]
- 客户端遍历所有文件
#遍历挂载目录下所有文件
$ tree /mnt/
#查看这个目录下面所有文件夹及文件数量
$ tree /mnt/ | wc -l
347
- 再次查看客户端session信息
#查看客户端session的inode数量, num_caps:346
$ ceph daemon mds.ceph-xxx-osd01.ys session ls
[
{
"id": 554418,
"num_leases": 1,
"num_caps": 346,
"state": "open",
"replay_requests": 0,
"completed_requests": 2,
"reconnecting": false,
"inst": "client.554418 192.168.1.3:0/1285681097",
"client_metadata": {
"ceph_sha1": "fe3a2269d799a8b950404cb2de11af84c7af0ea4",
"ceph_version": "didi_dss version 12.2.2.4 (fe3a2269d799a8b950404cb2de11af84c7af0ea4) luminous (stable)",
"entity_id": "admin",
"hostname": "ceph-xxx-osd01.ys",
"mount_point": "/mnt",
"pid": "2084",
"root": "/"
}
}
]
结论:
- 客户端通过遍历挂载目录下所有文件,发现服务端的session num_caps跟客户端文件夹及文件梳理匹配
- 也就是说客户端读取过的文件句柄,都会在服务端记录下来。 (mds缓存了dentry,并且以lru算法的缓存淘汰方式把dentry缓存在了内存中)
2.5.2 释放客户端session inode
解决方案:
- 方案1:采用多活mds(目前12版 multi active不稳定)
- 方案2:evict client(主动踢出有问题的客户端)
- 方案3:client remount(有问题的客户端重新mount挂载)
- 方案4:drop_cache, limit_cache
- mds limiting cache by memory https://github.com/ceph/ceph/pull/17711
- (官方提供的mds 主动删除cache,补丁在review过程中个,目标版本是ceph-14.0.0) https://github.com/ceph/ceph/pull/21566
 image.png
image.png
3. 深入分析
根据上面的分析,我们基本有一定的思路。 这里我们继续深入到方案2中。
3.1 剔除客户端session
3.1.1 查看客户端session信息
$ ceph daemon mds.ceph-xxx-osd01.ys session ls
[
{
"id": 554418,
"num_leases": 0,
"num_caps": 1589,
"state": "open",
"replay_requests": 0,
"completed_requests": 2,
"reconnecting": false,
"inst": "client.554418 192.168.1.2:0/1285681097",
"client_metadata": {
"ceph_sha1": "fe3a2269d799a8b950404cb2de11af84c7af0ea4",
"ceph_version": "didi_dss version 12.2.2.4 (fe3a2269d799a8b950404cb2de11af84c7af0ea4) luminous (stable)",
"entity_id": "admin",
"hostname": "ceph-xxx-osd01.ys",
"mount_point": "/mnt",
"pid": "2084",
"root": "/"
}
}
]
3.1.2 剔除客户端session信息
$ ceph tell mds.ceph-xxx-osd01.ys client evict id=554418
3.1.3 查看osd的blacklist
#超时恢复的时间是1小时,剔除的时间是16:16:30, 恢复的时间是17:16:30
$ ceph osd blacklist ls
listed 1 entries
192.168.1.2:0/1285681097 2018-10-10 17:16:30.819201
3.1.4 查看客户端挂载目录(不能读写)
$ ll /mnt
ls: cannot access /mnt: No such file or directory
3.1.5 恢复剔除的客户端
$ ceph osd blacklist rm 192.168.1.2:0/1285681097
un-blacklisting 192.168.1.2:0/1285681097
3.1.6 查看客户端挂载目录(正常读写)
$ ll /mnt
total 147698
-rw-r--r-- 1 root root 4 Oct 10 15:25 aa.txt
...
3.1.7 osd黑名单的客户端超时时间
- 旧版本超时时间为1小时
- 新版本12.2.2 超时时间为300s
总结:
- 可以通过指令client evict 剔除指定的客户端
- 剔除的客户端会加入到osd黑名单中
- 加入到osd黑名单中的客户端都不能读写
- 恢复剔除的客户端需要删除osd黑名单中的客户端信息
- 删除osd黑名单中客户端信息,客户端立马能正常读写
- fuse客户端可以恢复,kernel客户端无法恢复
- 经过试验证明:
- 剔除的用户虽然释放了inode
- 主mds的内存并未释放
- 主从切换后,备mds内存会释放
- 主从切换后,切换速度少了加载inode耗时的阶段,从而加快切换速度,秒级别
3.2 内存未释放分析
3.2.1 依赖软件
yum install google-perftools
3.2.2 查看mds内存
top - 13:14:06 up 63 days, 21:36, 1 user, load average: 0.06, 0.08, 0.12
Tasks: 1 total, 0 running, 1 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.2 us, 0.1 sy, 0.0 ni, 99.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 13149521+total, 96957576 free, 10023744 used, 24513896 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 11539159+avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
4997 ceph 20 0 4081012 1.447g 11452 S 0.0 1.2 0:54.29 ceph-mds
3.2.3 启动剖析器
$ ceph tell mds.0 heap start_profiler
2018-10-12 13:15:35.979279 7f3430bfa700 0 client.5796596 ms_handle_reset on 192.168.1.2:6804/2252738073
2018-10-12 13:15:36.008686 7f34293fc700 0 client.5796599 ms_handle_reset on 192.168.1.2:6804/2252738073
mds.ceph-xxx-osd01.ys started profiler
3.2.4 转储堆栈信息
$ ceph tell mds.0 heap dump
2018-10-12 13:16:34.891671 7efd04bfa700 0 client.5796659 ms_handle_reset on 192.168.1.2:6804/2252738073
2018-10-12 13:16:34.922696 7efcfd3fc700 0 client.5796662 ms_handle_reset on 192.168.1.2:6804/2252738073
mds.ceph-xxx-osd01.ys dumping heap profile now.
------------------------------------------------
MALLOC: 1225155304 ( 1168.4 MiB) Bytes in use by application
MALLOC: + 0 ( 0.0 MiB) Bytes in page heap freelist
MALLOC: + 289987072 ( 276.6 MiB) Bytes in central cache freelist
MALLOC: + 11013456 ( 10.5 MiB) Bytes in transfer cache freelist
MALLOC: + 7165384 ( 6.8 MiB) Bytes in thread cache freelists
MALLOC: + 7598240 ( 7.2 MiB) Bytes in malloc metadata
MALLOC: ------------
MALLOC: = 1540919456 ( 1469.5 MiB) Actual memory used (physical + swap)
MALLOC: + 112582656 ( 107.4 MiB) Bytes released to OS (aka unmapped)
MALLOC: ------------
MALLOC: = 1653502112 ( 1576.9 MiB) Virtual address space used
MALLOC:
MALLOC: 94545 Spans in use
MALLOC: 16 Thread heaps in use
MALLOC: 8192 Tcmalloc page size
------------------------------------------------
Call ReleaseFreeMemory() to release freelist memory to the OS (via madvise()).
Bytes released to the OS take up virtual address space but no physical memory.
3.2.5 google-pprof分析内存堆栈
pprof --text bin/ceph-mds out/mds.a.profile.0001.heap
$ pprof --text bin/ceph-mds out/mds.a.profile.0008.heap
Using local file bin/ceph-mds.
Using local file out/mds.a.profile.0008.heap.
Total: 46.6 MB
18.1 38.7% 38.7% 19.5 41.9% Server::prepare_new_inode
6.2 13.3% 52.0% 6.2 13.3% std::_Rb_tree::_M_emplace_hint_unique (inline)
5.0 10.7% 62.7% 5.8 12.3% CDir::add_null_dentry
3.8 8.1% 70.8% 3.8 8.1% std::_Rb_tree::_Rb_tree_impl::_M_initialize (inline)
3.6 7.7% 78.6% 3.6 7.7% ceph::logging::Log::create_entry
3.1 6.7% 85.2% 3.1 6.7% Counter::_count (inline)
2.6 5.5% 90.7% 2.6 5.5% ceph::buffer::raw_combined::create (inline)
0.9 2.0% 92.8% 0.9 2.0% std::_Vector_base::_M_create_storage (inline)
0.8 1.6% 94.4% 0.8 1.6% CDir::add_null_dentry (inline)
0.6 1.2% 95.6% 0.6 1.2% CInode::add_client_cap (inline)
0.5 1.1% 96.6% 0.5 1.1% std::string::_Rep::_S_create
0.5 1.0% 97.6% 0.5 1.0% MDCache::add_inode (inline)
0.2 0.5% 98.2% 0.3 0.6% decode_message
0.2 0.4% 98.5% 0.2 0.5% MDCache::request_start (inline)
0.1 0.2% 98.7% 0.1 0.3% CInode::project_inode
0.1 0.2% 99.0% 0.1 0.2% std::_Rb_tree::_M_insert_unique (inline)
0.1 0.1% 99.1% 0.1 0.1% std::string::_M_data (inline)
4. 总结
cephfs mds目前版本都是单活,对于复杂多变的客户端可能会带来一定的性能影响。
例如:在本地磁盘下去搜索一个文件,如果文件数过多的,对本机cpu以及负载也会带来一定的冲击,更何况是复杂多变的网络磁盘。
目前推荐的优化方案:
- ceph-fuse客户端Qos限速,避免IO一瞬间涌进来导致mds抖动(从客户端限制IOPS,避免资源争抢,对系统资源带来冲击)
- 多活mds, 目录分片(最终解决方案,详见:多活MDS的性能测试 )
- mds在主处理流程中使用了单线程,这导致了其单个MDS的性能受到了限制,最大单个MDS可达8k ops/s,CPU利用率达到的 140%左右。
- 如果mds负载过高或者内存过大,限制内存或者定期的回收cache(减轻mds的压力,提升吞吐 https://github.com/ceph/ceph/pull/17711/files)
- 剔除用户可以释放inode数量,但是不能减少内存,如果此时切换主从可以加快切换速度。