机器学习必备之matplotlib——数据可视化分析
之前我们已经简单的学习了Numpy和pandas的一些基础知识,get到了基本的数据分析操作;但是这些数据分析还不够直观,现在需要进一步学习更直观的可视化数据分析matplotlib。
matplotlib的图像都位于Figure对象中,可以用plt.figure创建一个新的Figure
[In] fig = plt.figure()
这时候就会弹出来一个空窗口。plt.figure有一些属性,比如说figsize,就是确保当图片保存到磁盘时具有一定的大小和横纵比。注意,不能通过空的Figure绘图,必须用add_subplot创建一个或多个subplot才行:
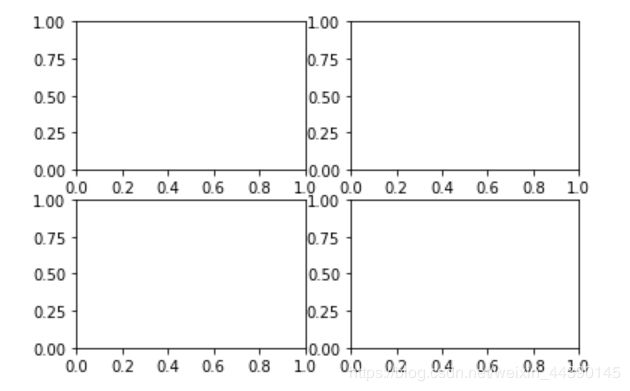
[In] ax1 = fig.add_subplot(2, 2, 1)
这句话的意思是,图像应该是2X2的,且当前选中的是4个subplot中的第一个(编号从1开始),如果再把后面两个subplot加进来
[In] ax2 = fig.add_subplot(2, 2, 2)
[In] ax3 = fig.add_subplot(2, 2, 3)
[In] ax4 = fig.add_subplot(2, 2, 4)
最终得到的图像是如下图所示的:
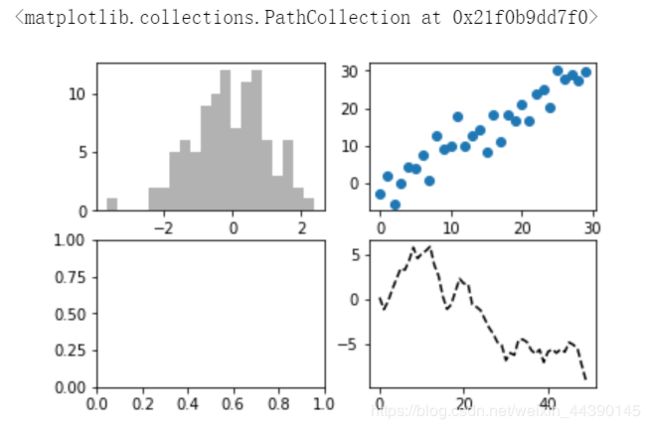
这时如果发出绘图命令,matplotlib就会在最后一个用过subplot上进行绘制(如果没有就创建一个),如果执行下列代码会出现的结果是:
[In] import numpy as np
[In] plt.plot(np.random.randn(50).cumsum(),'k--')

'k–'是一个线性选项,用于告诉matplotlib绘制黑色的虚线,上面那些由fig、.add_subplot所返回的对象是AxesSubplot对象,直接调用他们的实例方法就可以在其他空着的格子里面画了
[In] ax1.hist(np.random.randn(100), bins = 20,color = 'k',alpha = 0.3)
[In] ax2.scatter(np.arange(30),np.arange(30) + 3*np.random.randn(30))
可以再matplotlib的文档中找到各种图表的类型。由于根据特定的布局创建的Figure和subplot是一件非常常见的任务,于是就有了更方便的方法(plt.subplots),他可以创建一个新的Figure,并返回一个含有已创建的subplot对象的Numpy数组:

这是非常实用的方法,可以轻松的对axes数组进行索引,就像是一个二维数组一样,例如axes[0, 1],可以通过sharex和sharey指定subplot应该具有相同的X轴或Y轴。在比较相同范围的数据时,也是非常实用的,否则,matplotlib会自动缩放各图表的界限。
下面是有关pyplot.subplots的选项

调整subplot周围的间距
默认的情况下,matplotlib会自动在subplot的外围留下一定的边距,并在subplot之间留下一定的间距,这个间距和图像的高度和宽度有关,因此调整图像大小时,间距也会自动调整。
利用Figure的subplots_adjust方法可以方便的调节间距,而且她还是个顶级函数

wspace和hspace用于控制宽度和高度的百分比,可以用作subplot之间的间距,下面是一个将间距缩小到0的实例:
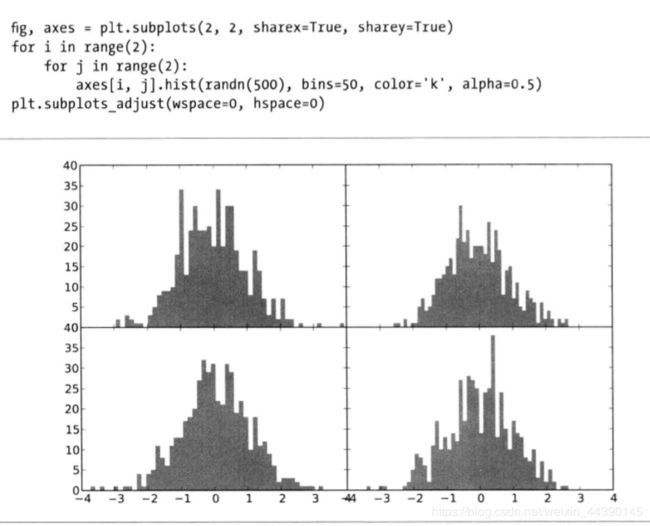
其中的标签出现了重叠的现象,这个没办法,matplotlib不会自动帮你检查这个,所以只有你自己设定好刻度位置和刻度标签了。
颜色、标记、线型
matplotlib的plot函数除了接受一组XY坐标外,还可以接受一个表示颜色和线型的字符串缩写;
若要执行根据x和y绘制绿色的虚线,可以执行以下代码:
ax.plot(x, y, 'g--')
不过一下代码也能达到同样的效果:
ax.plot(x, y, linestyle = '--', color = 'g')
常见的颜色都有固定的缩写,如果要使用其他颜色,可以通过制动其RGB值的形式使用(如,‘#CECECE’),完整的linestyle参见plot文档。
线型图还可以加上一些标记,强调实际的数据点。由于matplotlib创建的是连续的线型图,所以不容易看出来真实的数据点的位置。
对于大多数图表的装饰项,主要的实现方式有二:
使用过程型pyplot接口;
使用更为面向对象的原声matplotlib API。
pyplot接口的设计目的就是交互式使用,xlim、xticks、xticklabels分别控制图表的范围、刻度位置、刻度标签等,使用的注意点有以下几方面:
1.若调用时不带参数,则返回当前的参数值
2.调用时带参数,则设置为参数值
所有这些方法都是对当前或最近创建的AxesSubplot起作用的,他们各自对应subplot上的2个方法,比如xlim对应的方法就是ax.get_xlim和ax.set_xlim等。
设置标题、轴标签、刻度、以及刻度标签
若要修改X轴的刻度,最简单的方法时使用set_xticks和set_xticklabels。
set_xticks指明了要将刻度放在数据范围中的哪些位置,在默认情况下,这些位置也就是刻度标签,但是也可以通过set_xticklabels来指明任何其他的值来作为刻度标签;
然后再用set_xlabel为x轴设置一个名称,用set_title设置一个标题。
Y轴的设置方式和X轴完全相同,仅需要把X改成Y即可。

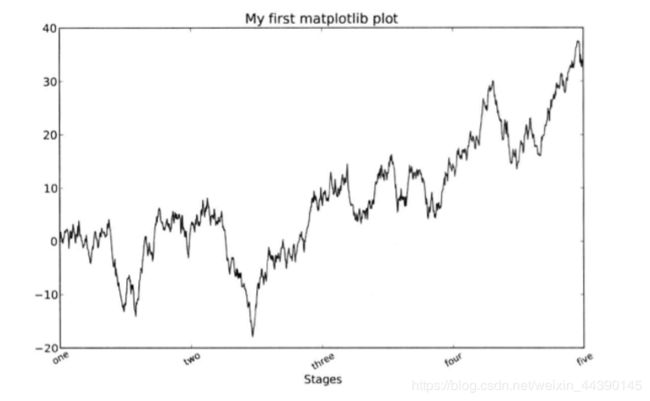
添加图例
添加图例的方式有两种,最简单的就是在添加subplot的时候传入label参数:


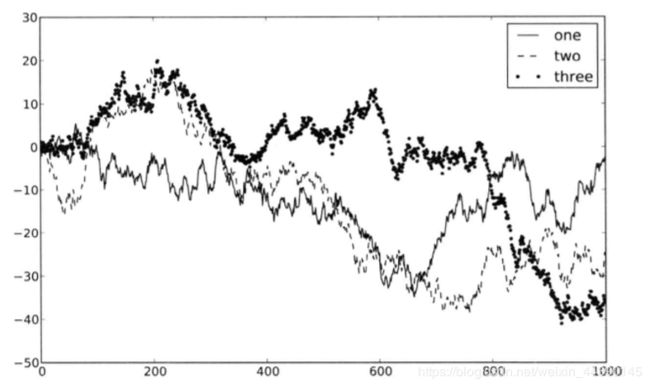
如图所示,loc可以告诉matplotlib要将图例放在哪里,如果你要求不是那么严格,‘best’是不错的选择,因为他会选择最不碍事的位置;要从图例中去除一个或多个元素,不传入label或label = 'nolegend’即可。
添加注解以及在subplot上面绘图
注解可以通过text、arrow、annotate等函数进行添加。
text可以将文本绘制在图表的指定坐标(x, y),还可以加上一些自定义格式:
ax.text(x, y, 'Hello world!', family='monospace', fontsize=10)
这样就会在指定的X、Y位置以text的格式画出响应的文字。
如果想要在图表中添加一个图形,你需要创建一个块对象shp,然后通过ax.add_patch(shp)将其添加到subplot中去

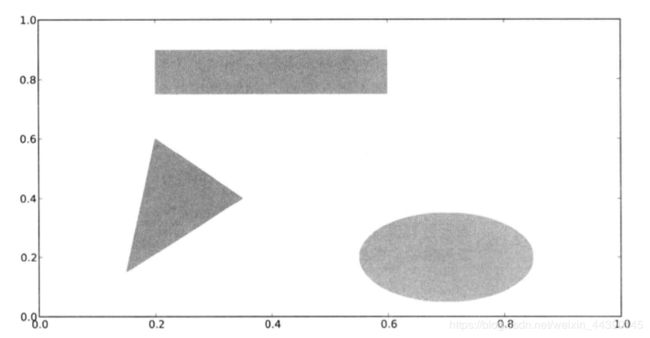
如果要查看常见的图表对象的具体实现代码,会发现他们其实就是由块组装起来的。
matplotlib中自带一些配色的方案,以及生成初版质量的图片而设定的默认配置信息,更好的是,几乎所有默认的行为都能通过一组全局参数进行自定义,以设置图像的大小、subplot边距、配色方案、字体大小、网格类型等。
操作matplotlib的配置系统的方式主要有两种,其中一种就是Python编程方式,利用rc方法:
比如:plt.rc('figure', figsize=(10, 10))
rc的第一个参数是希望自定义的对象,比如‘figure’,‘axes’,‘xtick’,‘ytick’,‘grid’,‘legend’等。其后面可以跟上一系列的关键字参数,最简单的方法就是将这些选项写成一个字典:

关于更多的自定义选项,还需要去查阅matplotlib的配置文件matplotlibrc,但是我们初期只需要了解基本的用法就可以了,后期在相关比赛中再进行再次强化。
pandas中的绘图函数
事实上,matplotlib是一种比较低级的工具,想要组装成一张图,就要用到他的基础组件才行:数据展示、图例、标题、刻度标签以及其他的注解型信息(因为要根据数据绘制一张完整的图表需要用到多个对象),也就是说,要制作一张完整的图表,原本需要一大堆的matplotlib代码,现在只需要一两条简洁的语句就ok了,pandas有许多能够利用DataFrame对象数据组织特点来创建标准图表的高级绘图方法。
Series和DataFrame都有一个用于生成各类图表的plot方法,默认情况下,他们生成的是线型图

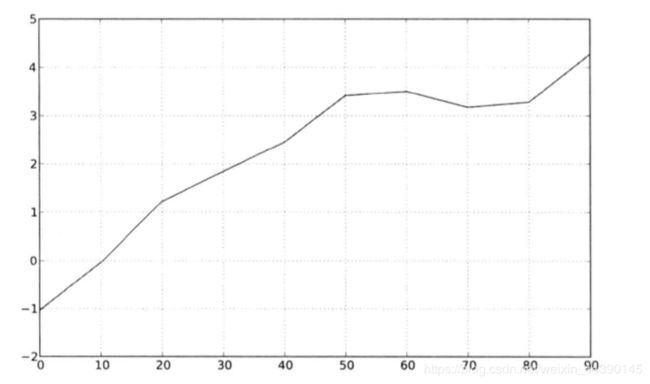
Series的索引会被传给matplotlib,并用来绘制X轴,可以通过use_index = False来禁用该功能。X的刻度和界限可以通过xticks和xlim选项进行调节,Y轴就是用yticks和ylim;
pandas大部分方法会在一个subplot中为各列绘制一条线,并自动创建图例:

这里的Series.plot和DataFrame.plot的方法相关参数有很大的不同,所以分别进行说明:
先给出Series的方法参数:


DataFrame还有一些用于对列的灵活处理的选项,例如,是将所有的列绘制到同一个subplot中还是各自创建格子的subplot。
下面的是DataFrame特有的方法参数:

柱状图
这个在学习了前面的内容后,就变得非常简单了,只需要在生成线型图的代码中加上kind=‘bar’ (垂直柱状图)或kind=‘barh’(水平柱状图),这时,Series和DataFrame的索引将被用于X或Y刻度:
直方图和密度图
直方图是一种可以对值的频率进行离散化显示的柱状图。数据点被拆分到离散的、间隔均匀的面元中,绘制的是各面元中数据点的数量,通过Series的hist方法,就可以绘制出一个直方图了:
这个就是一个直方图的例子;
与这个相关的一种图表类型就是密度图,他是通过计算“可能出现的连续概率分布估计”而产生的,一般过程是将该分布金丝成一组核(诸如正态分布、高斯分布之类的较为简单的分布),因此,密度图也被称为KDE(Kernel Density Estimate,核密度估计)。
调用plot时加上kind='kde’即可生成一张密度图,标准混合正态分布KDE:

直方图和密度图通常会画在一起,直方图以规格化形式给出(以便给出面元化密度),然后再其上绘制核密度估计:

这样对数据的对比就很明显了,也很方便我们观察。
散布图
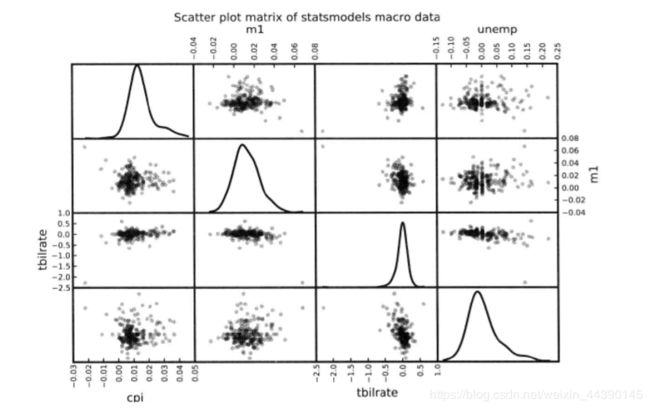
散布图是观察两个一维数组序列之间的关系的有效手段,matplotlib的scatter方法时绘制散布图的主要方法:

在数据分析工作中,同时观察一组变量的散布图是很有意义的,这也被称为散布图矩阵,手工创建这样的图表相当费事,所以pandas提供了一个能从DataFrame创建散布图矩阵的scatter_matrix函数。他还支持在对角线上放置个变量的直方图或密度图