数据分析与数据处理实例(某银行数据)
掌握numpy、matplotlib、pandas模块为前提,kmeans算法为主要分析工具
数据分析与数据处理
数据及含义
这里先上截图,具体的数据及数据含义点击下边链接,自行获取! https://download.csdn.net/download/weixin_44423698/11737958

方法
探索数据、清洗数据、清洗过后的选择需要的数据、对数据进行转换(如果数据很清晰,而且没有联系,可以不写)、标准化数据、Kmeans聚类和绘图得出结果。
代码实现
#引入数据处理与科学分析的三大模块
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
#引入sklearn模块里的机器学习算法k_means(是个函数)
from sklearn.cluster import KMeans
class DiverCar():
#探索数据
def tansuo(self,filepath):
'''
:param filepath: bank-all.csv文件所在位置
:return:
'''
df = pd.read_csv(filepath,sep=';')
df.to_excel('HW_data/bank_data.xls')
pass
#清洗数据
def qingxi(self,filepath):
'''
:param filepath: bank_data.xls文件所在的位置
:return:
'''
df = pd.read_excel(filepath)
filter1 = df['job'] != 'admin.'
filter2 = df['balance'] > 0
filter = filter1 & filter2
df = df[filter]
df.to_excel('HW_data/bank_clean.xls')
pass
#清洗过后的选择需要的数据
def xuanze(self,filepath):
'''
:param filepath: bank_clean.xls文件所在的位置
:return:
'''
df = pd.read_excel(filepath)
df = df[['job','balance','duration','pdays','poutcome']]
df.to_excel('HW_data/bank_choose.xls')
pass
#对数据进行转换(如果数据很清晰,而且没有联系,可以不写)
def zhuanhuan(self,filepath):
'''
:param filepath: bank_choose.xls文件的位置
:return:
'''
#L:工作 R:余额 F:持续电话时间 M:间隔时间 C:上一次成功与否
df = pd.read_excel(filepath)
df['job'].replace(['unemployed','student','retired','self-employed','housemaid','services','blue-collar','technician','management','entrepreneur','unknown'],[0,1,2,3,4,5,6,7,8,9,5],inplace=True)
df['L'] = df['job']
df['R'] = df['balance']
df['F'] = df['duration']
df['M'] = df['pdays']
df['poutcome'].replace(['failure','other','success','unknown'],[0,1,2,1],inplace=True)
df['C'] = df['poutcome']
df = df[['L','R','F','M','C']]
df.to_excel('HW_data/bank_zhuanhuan.xls')
pass
#标准化数据
def biaozhun(self,filepath):
'''
:param filepath:bank_zhuanhuan.xls文件的位置
:return:
'''
df = pd.read_excel(filepath)
df = (df - np.mean(df,axis=0))/np.std(df,axis=0)
df[['L', 'R', 'F', 'M', 'C']].to_excel('HW_data/bank_biaozhun.xls')
pass
#Kmeans聚类和绘图
def kmeans(self,filepath,k=5):
'''
:param filepath:
:return:
'''
df = pd.read_excel(filepath)
kmeans = KMeans(k)
kmeans.fit(df[['L', 'R', 'F', 'M', 'C']])
df['label']=kmeans.labels_
coreData = np.array(kmeans.cluster_centers_)
#绘图
xdata = np.linspace(0,2*np.pi,k,endpoint=False)
xdata = np.concatenate((xdata,[xdata[0]]))
ydata1 = np.concatenate((coreData[0], [coreData[0][0]]))
ydata2 = np.concatenate((coreData[1], [coreData[1][0]]))
ydata3 = np.concatenate((coreData[2], [coreData[2][0]]))
ydata4 = np.concatenate((coreData[3], [coreData[3][0]]))
ydata5 = np.concatenate((coreData[4], [coreData[4][0]]))
fig = plt.figure()
ax = fig.add_subplot(111,polar=True)
ax.plot(xdata, ydata1, 'b--', linewidth=1, label='customer1')
ax.plot(xdata, ydata2, 'r--', linewidth=1, label='customer2')
ax.plot(xdata, ydata3, 'g--', linewidth=1, label='customer3')
ax.plot(xdata, ydata4, 'o--', linewidth=1, label='customer4')
ax.plot(xdata, ydata5, 'y--', linewidth=1, label='customer5')
ax.set_thetagrids(xdata * 180 / np.pi, ['L', 'R', 'F', 'M', 'C']) # 有五个值,将一个圆分为五块
ax.set_rlim(-3, 5) # 轴值范围,圆点是-3,最外层是5
plt.legend(loc='best')
plt.show()
pass
pass
if __name__ == '__main__':
dc = DiverCar()
#一步一步生成excel表,最后的函数方法通过图表展示出结果
# dc.tansuo('HW_data/bank-all.csv')
# dc.qingxi('HW_data/bank_data.xls')
# dc.xuanze('HW_data/bank_clean.xls')
# dc.zhuanhuan('HW_data/bank_choose.xls')
# dc.biaozhun('HW_data/bank_zhuanhuan.xls')
dc.kmeans('HW_data/bank_biaozhun.xls',k=5)
pass
结果
生成的excel表
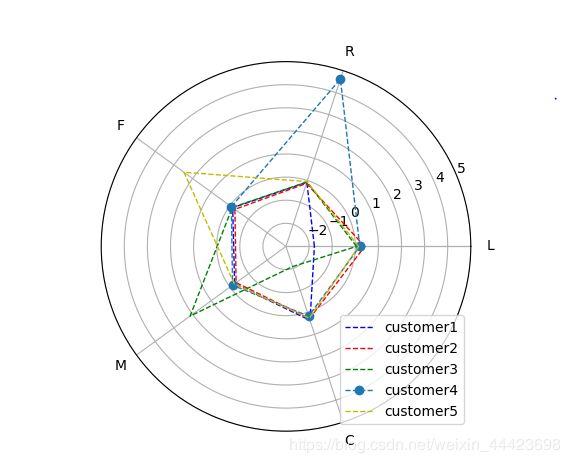
图表
判断依据
工作(数越大可能性越高)、余额(越大可能性越高)、持续间(越长可能性越高)、间隔时间天(越少可能性越高)、上一次的结果(数越大成功的可能性越高)
结果:将没有影响的数置为0,但因为影响较小(不是没有影响),我在这里并没有过多的处理。
有了结果就可以根据设定的标准判断哪些用户属于哪种分类,看看其存款的概率,而决定是否电话联系让其购买产品(存款)