【玩转华为云】决战黑客松——手把手教你实现Baseline赛题

本篇推文共计2000个字,阅读时间约3分钟。
华为云—华为公司倾力打造的云战略品牌,2011年成立,致力于为全球客户提供领先的公有云服务,包含弹性云服务器、云数据库、云安全等云计算服务,软件开发服务,面向企业的大数据和人工智能服务,以及场景化的解决方案。

华为云用在线的方式将华为30多年在ICT基础设施领域的技术积累和产品解决方案开放给客户,致力于提供稳定可靠、安全可信、可持续创新的云服务,做智能世界的“黑土地”,推进实现“用得起、用得好、用得放心”的普惠AI。华为云作为底座,为华为全栈全场景AI战略提供强大的算力平台和更易用的开发平台。

华为云官方网站
ModelArts是华为云产品中面向开发者的一站式AI开发平台,为机器学习与深度学习提供海量数据预处理及半自动化标注、大规模分布式Training、自动化模型生成,及端-边-云模型按需部署能力,帮助用户快速创建和部署模型,管理全周期AI工作流。

华为云官方网站

决战黑客松——手把手教你实现Baseline赛题
本实验我们将聚焦于用ModelArts实现华为云开发者AI青年班黑客松大赛的Baseline赛题,手把手教你进行实验,带你用Notebook编写训练代码,带你将生成模型导入模型管理,带你将模型部署成在线服务,最后带你提交模型判分,教你实现黑客松大赛中的Baseline赛题。
决战黑客松——手把手教你实现Baseline赛题
实验流程
1.准备实验环境与创建OBS桶
2.Notebook环境中编写脚本
3.将生成模型导入至模型管理
4.将模型部署成在线服务
5.提交模型判分
1
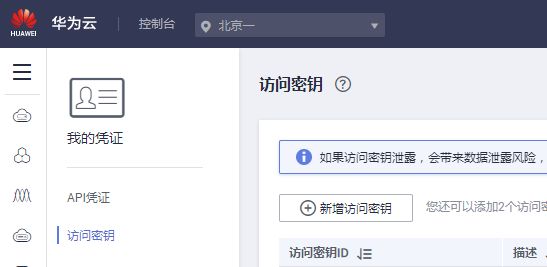
1.1密钥准备
首先需要进入华为云官方网站
https://www.huaweicloud.com/

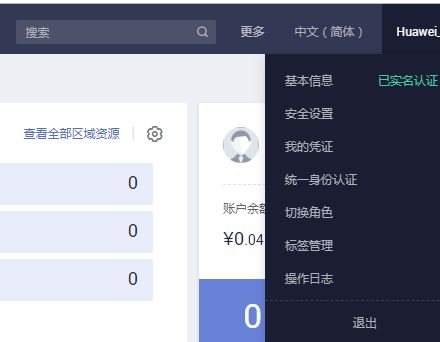
点击页面的“控制台”切换至控制台界面,在账号名称的下拉菜单中点击“我的凭证”,进入创建管理访问密钥(AK/SK)的界面。位置如下图所示:
什么是访问密钥?
访问密钥即AK/SK(Access Key ID/Secret Access Key),是您通过开发工具(API、CLI、SDK)访问华为云时的身份凭证,不能登录控制台。系统通过AK识别访问用户的身份,通过SK进行签名验证,通过加密签名验证可以确保请求的机密性、完整性和请求者身份的正确性。
选择“访问密钥”,点击“新增访问密钥”
妥善保存系统自动下载的“credentials.csv”文件中的AK(Access Key Id)和SK(Secret Access Key)以备后续步骤使用。

1.2创建OBS桶和目录
进入方式,“控制台”->“服务列表”->“存储”->“对象存储服务”,页面右上角点击“创建桶”按钮进入创建页面。

什么是OBS?
对象存储服务(Object Storage Service,OBS)是一个基于对象的海量存储服务,为客户提供海量、安全、高可靠、低成本的数据存储能力,包括:创建、修改、删除桶,上传、下载、删除对象等。
1.3 OBS桶设置
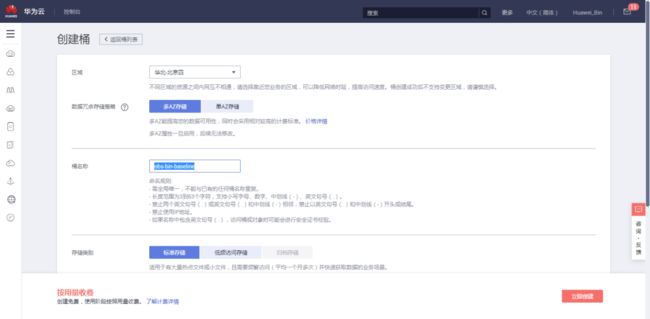
OBS桶设置参数如下:
区域:华北-北京四
桶名称:自定义(注意:此名称会在后续步骤使用)
根据自己的命名习惯,我将此处的桶名称取为
obs-bin-baseline
存储类别:标准存储
桶策略:私有
归档数据直读:关闭
多AZ:开启
点击"立即创建",完成创建
1.4创建文件夹
点击刚刚创建的桶,进入详情页:

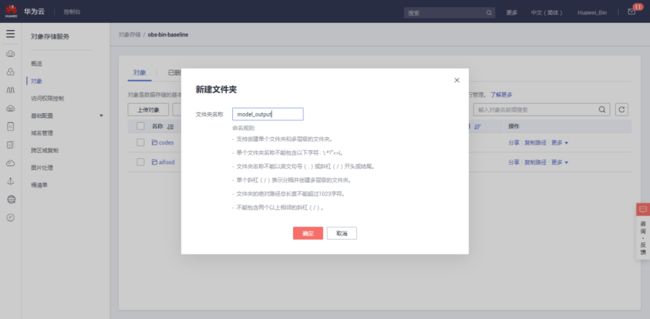
左侧栏选择“对象”,点击“新建文件夹”,在弹出的新建窗口中:
文件夹名称:自定义(此名称会在后续步骤中使用)
根据自己的命名习惯,我将此处的文件夹名称取为aifood
点击“确定”完成添加

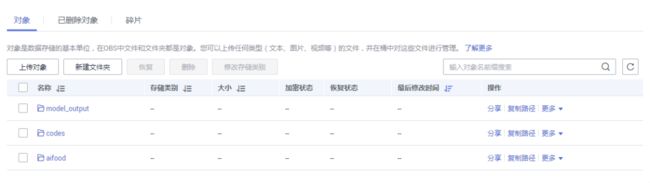
aifood文件夹主要用于存放竞赛数据集
还需要一个文件夹存放代码文件,另外一个文件夹存放训练输出文件
我新建存放代码文件夹为codes:

我新建存放训练输出文件夹为model_output:
新建好了的三个文件夹:
1.5服务授权
由于本实验项目需要使用 ModelArts Notebook、训练作业、模型及服务时可能需要使用数据管理功能,在开始使用前,需为数据管理模块获取访问OBS权限。
在ModelArts管理控制台,进入“数据管理->数据集”页面,单击“服务授权”
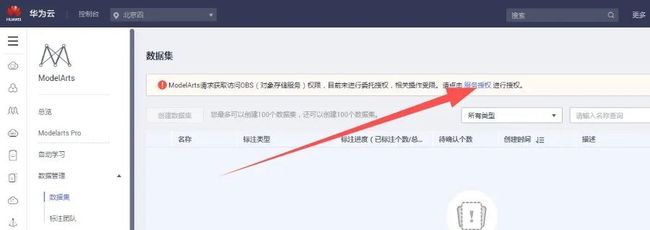
由具备授权的账号“同意授权”后,即可正常使用:

2
2.Notebook环境中编写脚本
在ModelArts平台左侧选择“开发环境”->“Notebook”
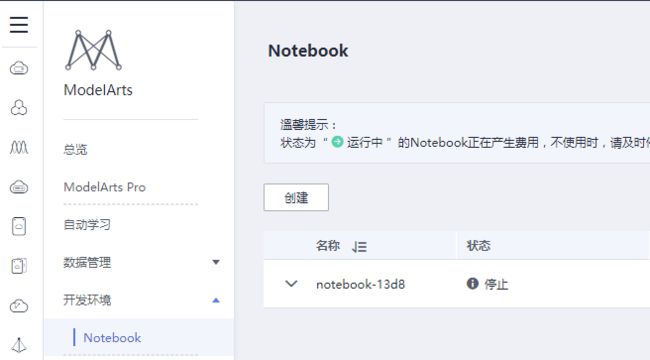
选择“创建”,并按照下列配置,填写相关参数:
名称:自定义(此处我设置的是notebook-bin)
工作环境:Python3
资源池:公共资源池
类型与规格根据你的需求来设置,此处我设置为:
类型:GPU
规格:保持默认
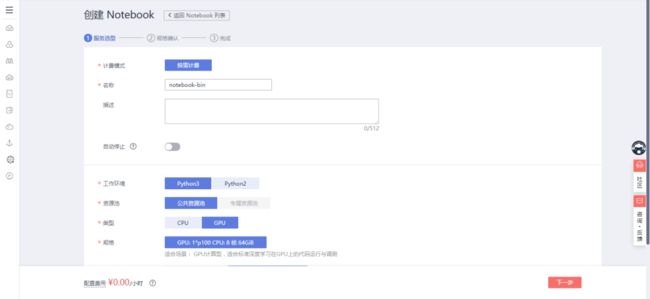
存储配置:对象存储服务(文件夹是刚才创建的codes)
/obs-bin-baseline/codes/
单击“下一步”进行规格确认:
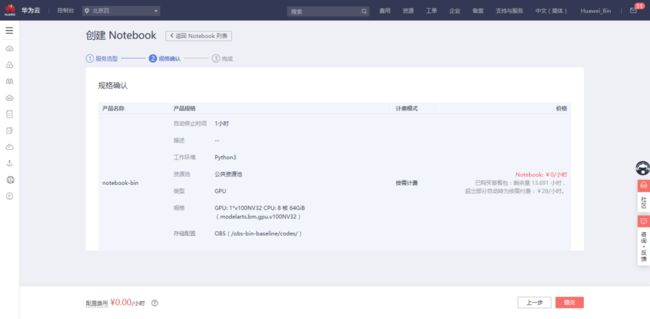
确认无误后单击“提交”,返回 Notebook 列表:
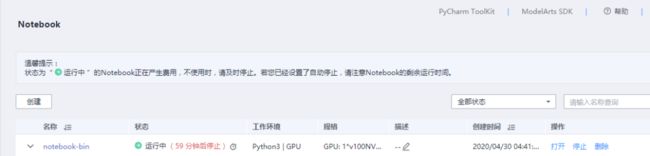
单击Notebook作业列表操作栏中“打开”,打开刚才创建的Notebook:
单击页签右上角“New”,选择“Pytorch-1.0.0”:
进入代码开发界面:
在代码输入栏中输入如下代码:
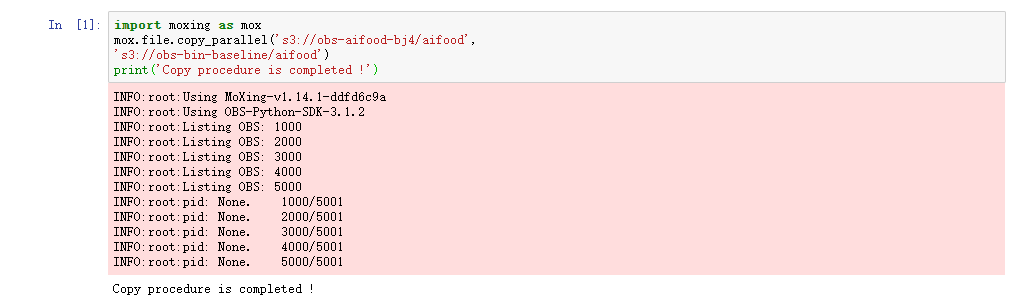
import moxing as mox
mox.file.copy_parallel('s3://obs-aifood-bj4/aifood',
's3://obs-bin-baseline/aifood')
print('Copy procedure is completed !')注意:将“obs-bin-baseline/aifood”替换为您创建的存放竞赛数据集的OBS路径
运行界面如下:
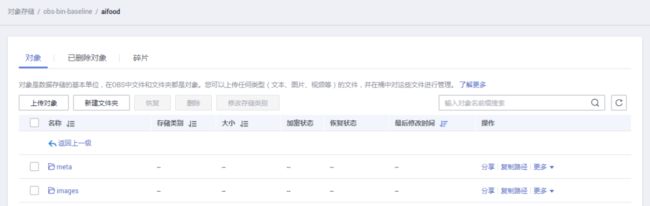
在自己的OBS桶的aifood文件夹中可查看,下载好的数据:
下载baseline赛题压缩包:
https://developer.huaweicloud.com/hero/forum.phpmod=viewthread&tid=52941
若链接失效,可在后台回复“赛题”下载:
打开Notebook进入代码开发界面后,单击“Upload”
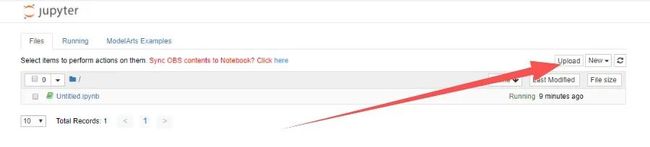
将赛题文件夹中的aifood_baseline.ipynb上传至Notebook:
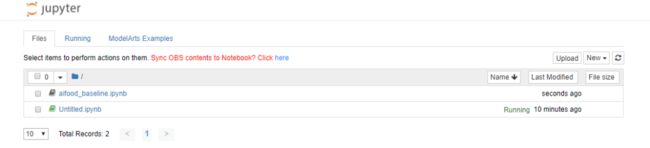
单击aifood_baseline.ipynb文件名称,进入代码编写/运行界面,
按照ipynb文件内容修改参数,运行所有代码。
在控制台,右方New处新建Folder,并取名aifood:
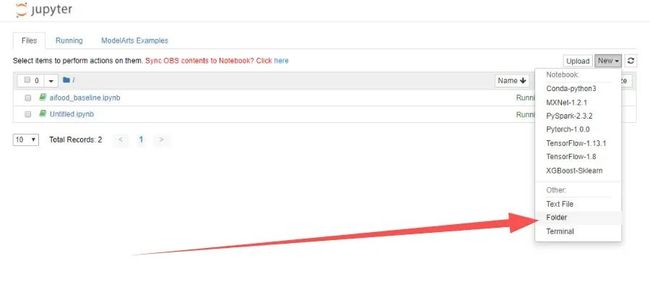
修改后,如下所示:

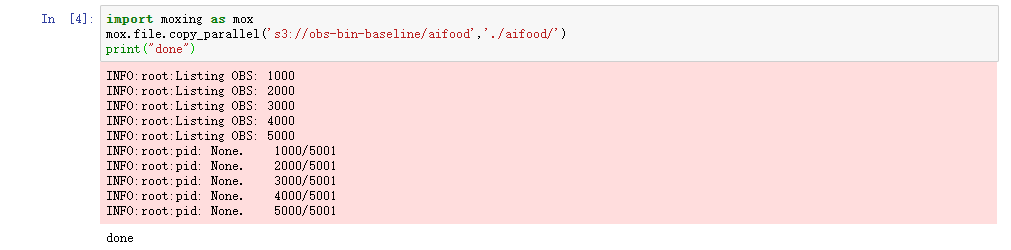
运行下列代码,将OBS桶的数据转移到Notebook的aifood文件夹中:
注意:将“obs-bin-baseline/aifood”替换为您创建的存放竞赛数据集的OBS路径
import moxing as mox
mox.file.copy_parallel('s3://obs-bin-baseline/aifood','./aifood/')
print("done")运行结果如下所示:
运行下列代码,加载依赖:
from __future__ import print_function, division
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
from torch.autograd import Variable
import torchvision
from torchvision import datasets, models, transforms
import time
import os运行结果如下所示:

运行代码1和代码2,是为了实现加载数据集,并将其分为训练集和测试集的目的:
代码1:
dataTrans = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
# image data path
data_dir = './aifood/images'
all_image_datasets = datasets.ImageFolder(data_dir, dataTrans)
#print(all_image_datasets.class_to_idx)
trainsize = int(0.8*len(all_image_datasets))
testsize = len(all_image_datasets) - trainsize
train_dataset, test_dataset = torch.utils.data.random_split(all_image_datasets,[trainsize,testsize])
image_datasets = {'train':train_dataset,'val':test_dataset}
# wrap your data and label into Tensor
dataloders = {x: torch.utils.data.DataLoader(image_datasets[x],
batch_size=64,
shuffle=True,
num_workers=4) for x in ['train', 'val']}
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'val']}
# use gpu or not
use_gpu = torch.cuda.is_available()代码2:
def train_model(model, lossfunc, optimizer, scheduler, num_epochs=10):
start_time = time.time()
best_model_wts = model.state_dict()
best_acc = 0.0
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
# Each epoch has a training and validation phase
for phase in ['train', 'val']:
if phase == 'train':
scheduler.step()
model.train(True) # Set model to training mode
else:
model.train(False) # Set model to evaluate mode
running_loss = 0.0
running_corrects = 0.0
# Iterate over data.
for data in dataloders[phase]:
# get the inputs
inputs, labels = data
# wrap them in Variable
if use_gpu:
inputs = Variable(inputs.cuda())
labels = Variable(labels.cuda())
else:
inputs, labels = Variable(inputs), Variable(labels)
# zero the parameter gradients
optimizer.zero_grad()
# forward
outputs = model(inputs)
_, preds = torch.max(outputs.data, 1)
loss = lossfunc(outputs, labels)
# backward + optimize only if in training phase
if phase == 'train':
loss.backward()
optimizer.step()
# statistics
running_loss += loss.data
running_corrects += torch.sum(preds == labels.data).to(torch.float32)
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects / dataset_sizes[phase]
print('{} Loss: {:.4f} Acc: {:.4f}'.format(
phase, epoch_loss, epoch_acc))
# deep copy the model
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = model.state_dict()
elapsed_time = time.time() - start_time
print('Training complete in {:.0f}m {:.0f}s'.format(
elapsed_time // 60, elapsed_time % 60))
print('Best val Acc: {:4f}'.format(best_acc))
# load best model weights
model.load_state_dict(best_model_wts)
return model运行结果如下所示,无报错:
本实验采用了resnet50神经网络结构训练模型,模型训练需要时间,等待该段代码运行完成后再往下执行:
如果想在最后进行模型优化,可以选择将此神经网络模型换成其它模型
# get model and replace the original fc layer with your fc layer
model_ft = models.resnet50(pretrained=True)
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_ftrs, 10)
if use_gpu:
model_ft = model_ft.cuda()
# define loss function
lossfunc = nn.CrossEntropyLoss()
# setting optimizer and trainable parameters
# params = model_ft.parameters()
# list(model_ft.fc.parameters())+list(model_ft.layer4.parameters())
#params = list(model_ft.fc.parameters())+list( model_ft.parameters())
params = list(model_ft.fc.parameters())
optimizer_ft = optim.SGD(params, lr=0.001, momentum=0.9)
# Decay LR by a factor of 0.1 every 7 epochs
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)
model_ft = train_model(model=model_ft,
lossfunc=lossfunc,
optimizer=optimizer_ft,
scheduler=exp_lr_scheduler,
num_epochs=10)运行结果如下所示:

运行代码,将训练好的模型保存下来:
torch.save(model_ft.state_dict(), './model.pth')运行结果如下:

运行下列代码,将模型保存到OBS桶中model文件夹下,为后续推理测试、模型提交做准备。
将如下代码中"obs-bin-baseline"修改成您OBS桶的名称。
import moxing as mox
mox.file.copy('./model.pth','s3://obs-aifood-baseline/model_output/model/resnet-50.pth')
print("done")运行结果如下:

3
3.将生成模型导入至模型管理
导入模型前,需要利用OBS Browser+将附件中的baseline模型配置文件、推理代码,以及美食图片标签文件labels_10c.txt上传至model文件夹下。如下所示:

注意:文件需要放在model文件夹里面,而不是model_output文件夹下面
做好上述操作后,在 ModelArts 左侧导航栏选择“模型管理”,单击页面中“导入”:
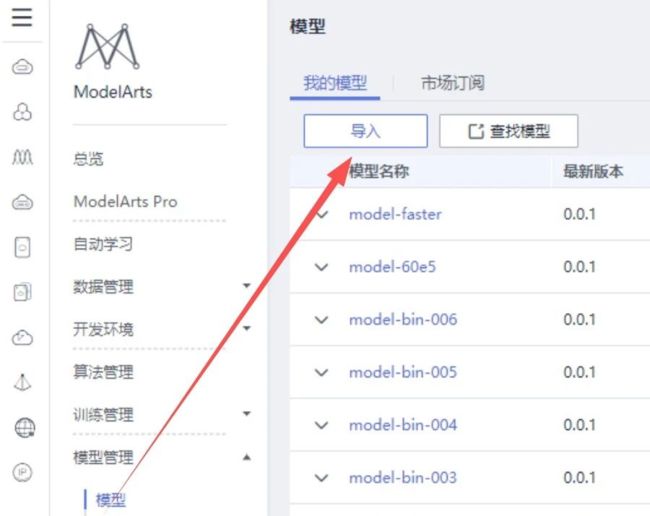
在导入模型页面填写名称,选择元模型来源;其中元模型来源如从OBS中选择,请选择model文件夹上一级目录,其余保持默认。
本baseline model文件夹上一级目录为obs-bin-baseline/model_output:
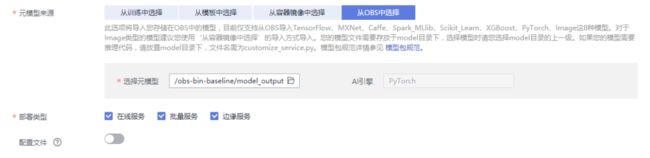
确认无误后,单击“立即创建”
单击模型名称进入模型详情页面,当模型版本状态为“正常”后,即导入模型成功,然后再进行下一步将模型部署为在线服务的操作。
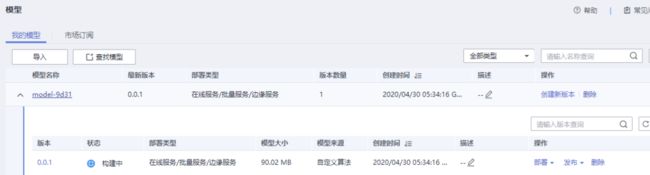
已显示“正常”,进行下一步操作:

4
4.将模型部署为在线服务
点击进入ModelArts主页“部署上线->在线服务”处,点击“部署”:
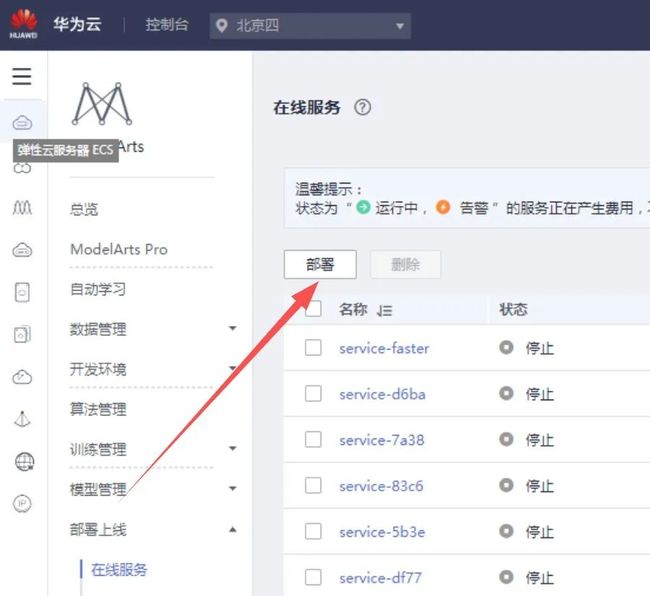
进行参数设置:
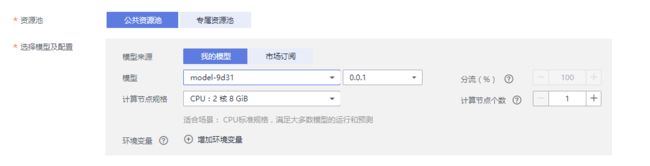
资源池:公共资源池
模型:刚才训练的模型
此处应选择为CPU,规格不能选为GPU,因为代码中设置中是用CPU计算,不然会出错。
点击“下一步”确认无误后:

点击“提交”即可,结下了就是等待部署:
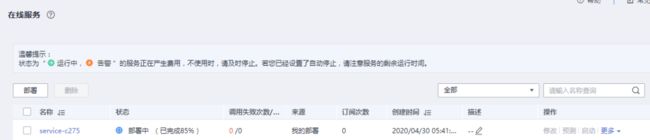
部署成功:
5
5.部署服务
进入ModelArts主页“部署上线->在线服务”处:

点击“部署”:
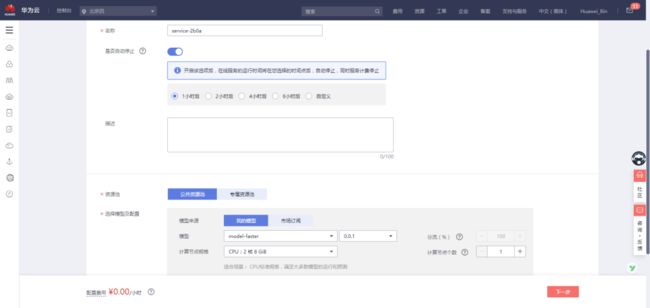
名称:自定义
(此处我设置的是service-faster)
资源池:公共资源池
选择模型及配置:
选择刚才导入的模型:model-faster
计算节点规格:自定义
其余保持默认
确认参数后,点击“下一步”
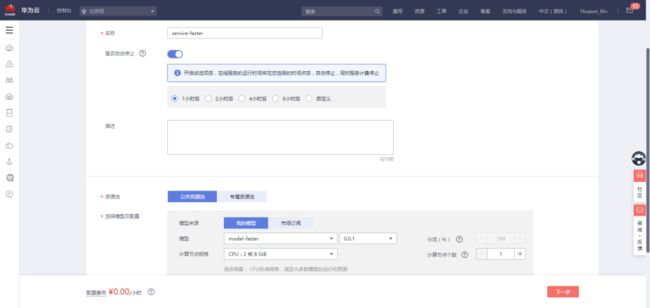
再次确认无误,点击“提交”:
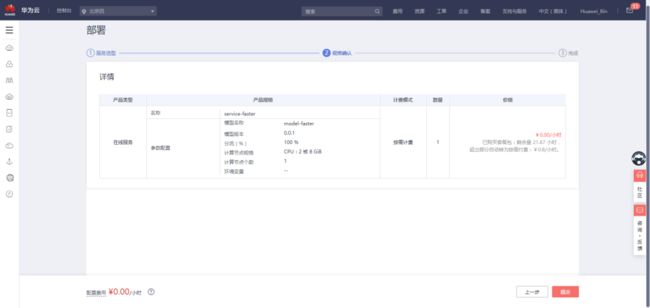
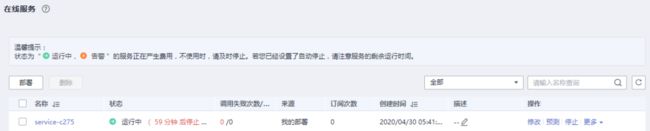
等待部署完成:

部署完成,显示“运行中”

在“部署上线”的“在线服务”处,点击运行中的在线服务右侧的“预测”

进入到测试界面,单击“上传”图片,进行检测:
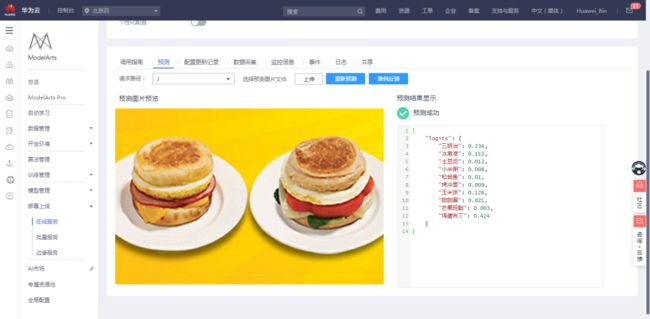
测试图片预测成功。
6
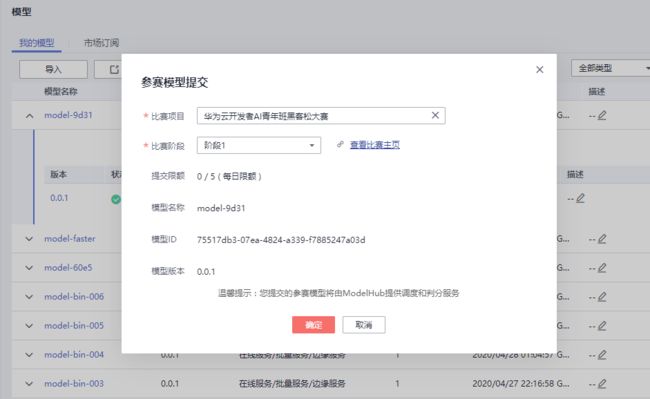
6.提交模型判分
在 ModelArts 左侧导航栏中选择“模型管理”,单击模型名称前方箭头;然后单击页面右侧操作栏中的“发布”,单击“参赛发布”。

确认信息无误,点击“确定”即可完成一次模型提交:
至此实验全部完成。
最后大家使用的云端资源记得全部删除如对象存储服务创建的OBS桶,文件夹;ModelArts创建的数据集,部署的模型等都需要删除,并停用访问密钥,以免造成不必要的花费。
通过对实验结果的比对,可以看出利用
[华为云ModelArts]训练出来的物体检测模型是很棒的,六个字总结就是-高效,快捷,省心。
如您对本系列的实验感兴趣,点击底部阅读原文可体验于4月20日开始的
[华为云开发者青年班第二期 AI实战营],现进行到打卡第七天,每天一天实战演练,让你足不出户免费体验[华为云]高级技术专家亲自指导,学、练、赛的全流程内容,让你轻松Get AI技能。
心动不如行动,快来学习吧。

正因我们国家有许多像华为这样强大的民族企业在国家背后默默做支撑,做奉献。我们国家才能屹立于世界民族之林。
华为,中国骄傲!中华有为!

往期回顾
【玩转华为云】Modelarts零代码开发FasterRCNN物体检测
【玩转华为云】Modelarts基于FasterRCNN算法实现物体检测
【玩转华为云】Modelarts基于YOLO V3算法实现物体检测
【玩转华为云】Modelarts基于海量数据训练猫狗分类模型
【玩转华为云】Modelarts实现猫狗数据集的智能标注
【玩转华为云】ModelArts基于海量数据训练美食分类模型
【玩转华为云】ModelArts零代码开发美食分类模型
【玩转华为云】ModelArts实现垃圾的智能分类
【玩转华为云】ModelArts实现数据集的图片标注
【玩转华为云】ModelArts实现一键目标物体检测
【玩转华为云】ModelArts实现一键行人车辆检测
武汉加油,中国加油!
欢迎各位读者在下方进行提问留言
☆ END ☆

你与世界
只差一个
公众号
扫描上方二维码,获取千元“编程学习资料”大礼包