Kaldi中文语音识别(1)官方文档初解读
接触语音识别以来,从看文献开始了解语音识别是怎么一回事,它的基本原理、背景、识别流程等等…
现在要用Kaldi进行语音识别真的可以称上小白了,关于文档解读,仅供大家参考。
【以下为Kaldi官方文档目录及内容】
3 kaldi 的使用
3.1 总述
在跑 kaldi 里的样例时,你需要注意三个脚本:cmd.sh path.sh run.sh。下
面分别来说,
- Cmd.sh 脚本为:
【
“queue.pl” uses qsub. The options to it are
options to qsub. If you have GridEngine installed, # change this to a queue you have access to. # Otherwise, use “run.pl”, which will run jobs locally
(make sure your --num-jobs options are no more than
#the number of cpus on your machine.
- #a)
JHU cluster options
#export train_cmd=“queue.pl -l arch=*64” #export decode_cmd=“queue.pl -l arch=*64,mem_free=2G,ram_free=2G” #export mkgraph_cmd=“queue.pl -l arch=*64,ram_free=4G,mem_free=4G” #export cuda_cmd=run.pl
- #b)
BUT cluster options
#export train_cmd=“queue.pl -q all.q@@blade -l
ram_free=1200M,mem_free=1200M” #export decode_cmd=“queue.pl -q all.q@@blade -l
ram_free=1700M,mem_free=1700M” #export decodebig_cmd=“queue.pl -q all.q@@blade -l
ram_free=4G,mem_free=4G” #export cuda_cmd=“queue.pl -q long.q@@pco203 -l gpu=1” #export cuda_cmd=“queue.pl -q long.q@pcspeech-gpu” #export mkgraph_cmd=“queue.pl -q all.q@@servers -l
ram_free=4G,mem_free=4G”
- #c)
run it locally… export train_cmd=run.pl
export decode_cmd=run.pl
export cuda_cmd=run.pl
export mkgraph_cmd=run.pl
】
大家可以很清楚的看到有 3 个分类分别对应 a,b,c。a 和 b 都是集群上去运
行这个样子,c 就是我们需要的。我们在虚拟机上运行的。你需要修改这个脚本。
- Path.sh 的内容:
export KALDI_ROOT=pwd/…/…/… export
PATH= P W D / u t i l s / : PWD/utils/: PWD/utils/:KALDI_ROOT/src/bin: K A L D I R O O T / t o o l s / o p e n f s t / b i n : KALDI_ROOT/tools/openfst/bin: KALDIROOT/tools/openfst/bin:K
ALDI_ROOT/tools/irstlm/bin/: K A L D I R O O T / s r c / f s t b i n / : KALDI_ROOT/src/fstbin/: KALDIROOT/src/fstbin/:KALDI_ROOT/src/gmm
bin/: K A L D I R O O T / s r c / f e a t b i n / : KALDI_ROOT/src/featbin/: KALDIROOT/src/featbin/:KALDI_ROOT/src/lm/: K A L D I R O O T / s r c / s g m m b i n / : KALDI_ROOT/src/sgm mbin/: KALDIROOT/src/sgmmbin/:KALDI_ROOT/src/sgmm2bin/: K A L D I R O O T / s r c / f g m m b i n / : KALDI_ROOT/src/fgmmbin/: KALDIROOT/src/fgmmbin/:KALDI_RO
OT/src/latbin/: K A L D I R O O T / s r c / n n e t b i n : KALDI_ROOT/src/nnetbin: KALDIROOT/src/nnetbin:KALDI_ROOT/src/nnet-cpubin/: K A L D I R O O T / s r c / k w s b i n : KAL DI_ROOT/src/kwsbin: KALDIROOT/src/kwsbin:PWD: P A T H e x p o r t L C A L L = C e x p o r t I R S T L M = PATH export LC_ALL=C export IRSTLM= PATHexportLCALL=CexportIRSTLM=KALDI_ROOT/tools/irstlm
在这里一般只要修改 export KALDI_ROOT=pwd/…/…/…改为你安装 kaldi 的目
录,有时候不修改也可以,大家根据实际情况。
- Run.sh
里大家需要指定你的数据在什么路径下,你只需要修改:
如:
#timit=/export/corpora5/LDC/LDC93S1/timit/TIMIT # @JHU
timit=/mnt/matylda2/data/TIMIT/timit # @BUT
修改为你的 timit 所在的路径。
其他的数据库都一样。
此外,voxforge 或者 vystadial_cz 或者 vystadial_en 这些数据库都提供下载,
没有数据库的可以利用这些来做实验
这里说一下读后感吧:
跑kaldi样例之前
需要注意cmd.sh、path.sh 、run.sh 这三个脚本。
- cmd.sh(cmd = command)
这里主要修改queue.pl为run.pl
#我们需要修改cmd.sh. 如下:
export train_cmd=run.pl #将原来的queue.pl改为run.pl
export decode_cmd="run.pl" #将原来的queue.pl改为run.pl 这里的--mem 4G 还是去掉吧 因为我机器装的虚拟机内存不是很大
export mkgraph_cmd="run.pl" #将原来的queue.pl改为run.pl 这里的--mem 8G 还是去掉吧 因为我机器装的虚拟机内存不是很大
export cuda_cmd="run.pl" #将原来的queue.pl改为run.pl 这里去掉原来的--gpu 1 因为我们不打算用GPU来参与
- path.sh
我在这里的时候咨询了一下师兄,师兄说这里可不改,我就没改。。。 - run.sh
这里我是想先跑一下清华thchs30的脚本
(已经安装好了语料库,后面讲如何安装),
这里主要是改nj = "8"或者“4”,thchs=…(放清华数据库的路径)
所以先进入run.sh
[czy@localhost ~]$ cd
[czy@localhost ~]$ cd kaldi/egs/thchs30/s5
[czy@localhost s5]$ ls
cmd.sh conf local path.sh RESULT run.sh steps thchs30-openslr utils
[czy@localhost s5]$ vim run.sh
我们接下来看看run.sh,前面几行
#!/bin/bash
. ./cmd.sh ## You'll want to change cmd.sh to something that will work on your system.
## This relates to the queue.
. ./path.sh
这里我们看到,其实执行run.sh的时候,它也是先要执行cmd.sh和path.sh,其中 cmd.sh就是刚刚我们改的,path.sh一会我们再说。
H=`pwd` #exp home
n=4 #parallel jobs #我们把n=8改为:n=4
这里我们看到H='pwd’完全是为了后面引用这个路径用的,先不用管它.我们把n=8改为:n=4,是因为我们并发的时候为四核心。
#corpus and trans directory
thchs=/home/czy/kaldi/egs/thchs30/s5/thchs30-openslr #我们把原来的/nfs/public/materials/data/thchs30-openslr改为/home/czy/kaldi/egs/thchs30/s5/thchs30-openslr
这里的意思是说,要训练的thchs30数据的目录,
我这里的目录是/home/czy/kaldi/egs/thchs30/s5/thchs30-openslr
[czy@localhost thchs30-openslr]$ pwd
/home/czy/kaldi/egs/thchs30/s5/thchs30-openslr
[czy@localhost thchs30-openslr]$ ls
data_thchs30 data_thchs30.tgz resource resource.tgz
[czy@localhost thchs30-openslr]$
(这里我只下载了两个压缩包)
thchs30的中文语音数据库,网址是http://www.openslr.org/18/
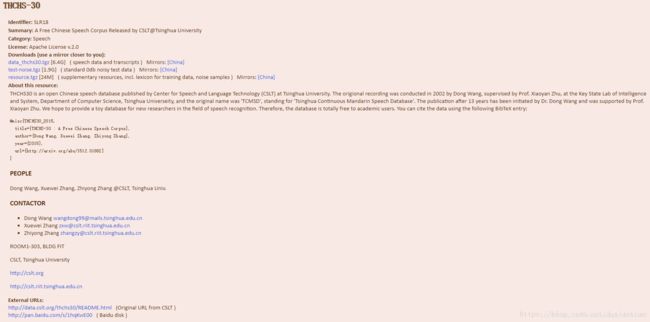 进去以后我们看到,有data_thchs30.tgz resource.tgz test-noise.tgz 这三个语音文件压缩包链接地址,
进去以后我们看到,有data_thchs30.tgz resource.tgz test-noise.tgz 这三个语音文件压缩包链接地址,
在服务器里面
[czy@localhost ~]$ cd
[czy@localhost ~]$ cd kaldi/egs/thchs30/s5
[czy@localhost s5]$ mkdir thchs30-openslr
[czy@localhost s5]$ cd thchs30-openslr
[czy@localhost thchs30-openslr]$
可以使用
wget http://www.openslr.org/resources/18/data_thchs30.tgz
wget http://www.openslr.org/resources/18/test-noise.tgz
wget http://www.openslr.org/resources/18/resource.tgz
分别下载。
[czy@localhost thchs30-openslr]$ wget http://www.openslr.org/resources/18/data_thchs30.tgz
[czy@localhost thchs30-openslr]$ wget http://www.openslr.org/resources/18/test-noise.tgz
[czy@localhost thchs30-openslr]$ wget http://www.openslr.org/resources/18/resource.tgz
(当然也可下载到电脑上用x ftp6上传到服务器,(ps: 用rz 命令可将本地文件上传到服务器,但是文件大小不超过4GB))
下载结束之后,使用解压命令解压
解压到当前文件夹: tar zxvf 文件名.tgz -C./
解压到指定文件夹:tar zxvf 文件名.tgz -C/制定文件夹路径