如何有效的获得高质量的大规模标注数据?
本文为亚利桑那州立大学在读计算机博士生周耀的2018年独家投稿,他给大家介绍了一个基于机器教学为基础的自适应交互型众包教学框架——JEDI ,它假设每个 learner 都有指数型的记忆遗忘曲线,并且能够保证教学的有效性,多样性,以及教学样本的质量。作者的原论文(http://cn.arxiv.org/abs/1804.06481)入选了2018的 KDD 会议。以下为投稿全文。
在很多机器学习的问题中,一个模型的表现往往取决于标注数据集的数据规模和标注质量。很多的监督式机器学习(supervised learning)模型,尤其是深度学习,都需要大量的标注数据来进行模型训练。比如说,ImageNet 是一个广为人知的用于计算机视觉领域的图像识别,物体检测,物体定位的数据集,里面包含了 1400 万张有人工标注和分类的图片。然而,很多的研究者都比较关注如何能够有效的使用这些数据进行模型设计和改良,却只有比较少的研究在跟进如何更有效的获得这些高质量的大规模标注数据。目前互联网存在的,人为标注的大规模数据集通常都会使用众包(crowdsourcing)技术来进行标注。

图 1:深度学习和 ImageNet
相比较于外包数据集给专业公司做标注,众包标注的优势有以下几点:
价格低廉。很多非职业的标注者(worker)愿意以较低的报酬在一些平台上,比如说 AMT(Amazon Mechanical Turk),帮助科研工作者或者公司来标注数据。
标注周期短。因为对于标注质量的要求并不是很严格,放置在众包平台的数据往往可以在短期内得到标注。
标注数量大。在众包的标注平台上,一般每个数据(item)都会得到多个标注者的标注,因此每一个数据都会得到大量的冗余标签。

图 2:众包标注的平台
图 2 和图 3 是一个典型的众包标注的例子:目标是让 worker 把图片的类型标注为两类:驯化的猫,野生的猫。如果 AMT 给出了图 2 中的 item,大多数的 worker 都可以很容易的给出正确的标签。
 图 3:众包平台的标注者标注一个简单的家猫图片
图 3:众包平台的标注者标注一个简单的家猫图片
然而,很多时候,图片标注也需要一些专业知识。图 4 中的猫,对与一些 worker 来讲,就不是很好辨别这只猫是驯化过的还是野生的。比如说,和动物打交道比较多的 worker 就可以相对容易的解决这个标注问题,但是一个不太有经验的小女孩就可能给出错误的标签。因此,对于一个特定的标注问题,worker 和 worker 之间有着标注能力的差异,这种差异也会在标注的时候在他们给出的标签上体现出来。这种差异往往会对众包标签融合的算法带来一些挑战。
 图 4:众包平台的标注者标注一个比较难的家猫图片
图 4:众包平台的标注者标注一个比较难的家猫图片
目前,比较成熟的众包标签融合的算法主要有两类方法:
第一类方法主要是用收集的众包标签对 worker 的标注能力进行估计,然后在标签融合的过程中加大优秀 worker 的权重并且降低较差 worker 的权重。
第二类方法一般是通过设计更好的激励机制(incentive mechanism)来引导 worker 提供更优质的 label。
然而,现在常用的方法都忽略了一个很重要的事实,那就是:相比于机器,人类是非常擅长学习一个新的概念(concept),而且可以很容易的将所学的概念很好的泛化并且转移到相似的问题中。图 5 中,人类可以通过看一些插画展示从而学会如何正确标注家猫和野猫的图片。因此,一个更有效的使用众包标注的方式其实应该是在监督 worker 标注的同时对他们进行教学(teach)。
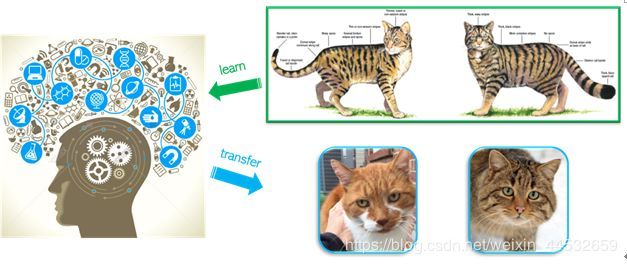
图 5:人类的学习和泛化迁移能力
基于机器教学的众包教学框架——JEDI
为了充分利用 worker 的学习能力,我们提出了一个基于机器教学(machine teaching)的众包教学框架 JEDI。首先,我们会先介绍什么是机器教学?机器教学其实是机器学习的反过程。如图 6 所示,如果给予一个数据集和一个算法(e.g. SVM, Logistic Regression),机器学习的目标是在模型空间(model space)里学习一个概念(concept)。然后,对于机器教学,目标概念(target concept)和算法是已知的,最终的目标是找到最优的数据集。关于数据集最优的定义可以很多元化,e.g. 数据集规模最小,学习速度最快,等等。
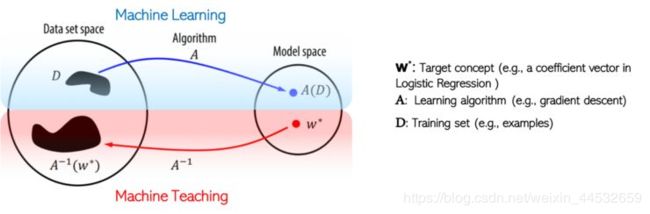
图 6:机器学习和机器教学
我们提出的 JEDI 众包教学实际上是 adJustable Exponentially Decayed memory Interactive Crowd Teaching 的缩写,JEDI 的特点是:
自适应教学,每个 worker/learner 的教学过程都是不同的。
记忆遗忘,每个 worker/learner 都会在学习的过程中逐渐遗忘过往所学。
指数衰减,记忆遗忘的曲线是呈指数衰减的。
交互教学,worker/learner 和 teacher 是有多次交互的。
关与交互教学,图 7 是一个简单的例子:

图 7:交互式教学
如图 8 所示,JEDI 的每一轮教学(这里假设是第 t 轮)包括以下三个步骤:
Teacher 估计 learner 的学习进度,根据 learner 之前的标注反馈得到上一次的学习概念,然后 teacher 向 learner 推荐一个新的样本进行教学。
Teacher 向 learner 展示教学样本(隐藏样本真实标签),要求 learner 提供他自己对当前样本的标注标签。
Teacher 展示样本真实标签,learner 辨识样本真实标签,并结合样本本身进行概念学习。
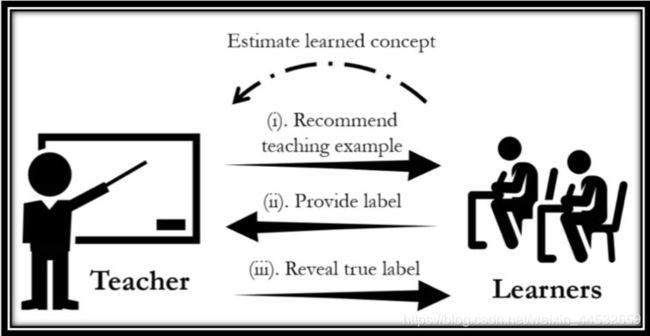
图 8:JEDI 的交互式教学示意图
学生(learner)模型:
-每一个 learner 的学习过程都假设遵循梯度下降的规律:
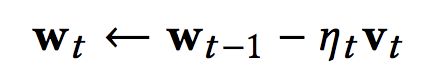
-我们进一步假设每一个 learner 对于学过的 concepts 的可收回度(retrievability)呈指数型递减:
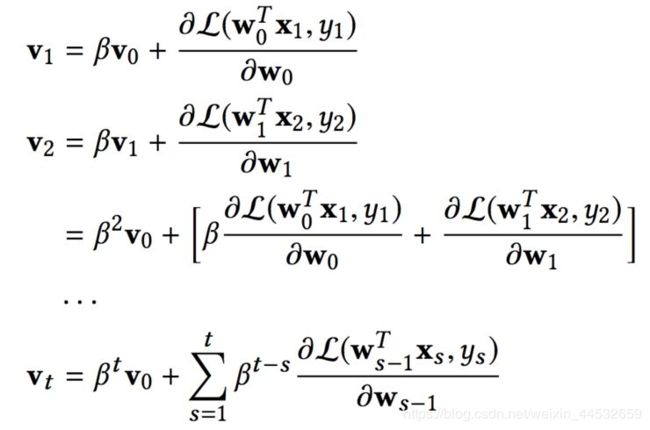
老师(teacher)模型:
-Teacher 的目标是通过教学减少 learner 学到的当前概念(current concept)和目标概念之间的差异,所以教学的目标方程是:

-这个目标方程可以被分解,具体细节请参考论文:

-如果我们将预测错误的概率简写为如下表达,总体的教学目标可以进一步简化为:

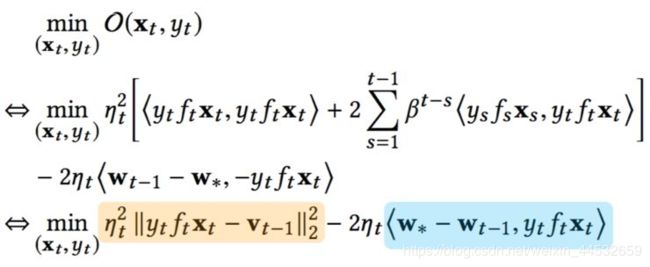
JEDI 模型的具体运作
JEDI 模型理解:
-教学有效性(usefulness)和教学多样性(diversity)的平衡(tradeoff):JEDI 的目标函数经过简化,优化问题的目标函数会包括有效性和多样性两部分组成。直观的来讲,这个平衡意味着 JEDI 可以通过最大化下一个教学样本的有效性和最大化教学样本之间的多样性从而引导 learner 向着目标概念的方向学习。

图 9:教学有效性和多样性的平衡
-探索(exploration)和利用(exploitation)的选择:如图 10 所示,如果 teacher 选择的下一个教学样本 xt 和上一个教学样本 xt-1 有标签相同,我们称之为利用(exploitation);如果 teacher 选择的下一个教学样本 xt 和上一个教学样本 xt-1 有标签不同,我们称之为探索(exploration)。

图 10:教学中的探索和利用
-教学样本的质量:如果上一个教学样本 xt-1 是一个有效性(usefulness)比较低的样本,JEDI 众包教学可以保证下一个教学样本 xt 具有以下特性:
在 exploitation 的教学场景下,teacher 会推荐跟 xt-1 特征非常不同的教学样本 xt。因为 xt-1 的有效性比较低,同一个类型(class)的但是特征(feature)非常不同的样本可能会有比较高的教学有效性。
在 exploration 的教学场景下,teacher 会会推荐跟 xt-1 特征非常接近的教学样本 xt。因为不同类型(class)的但是特征(feature)非常接近的样本可能会有比较有代表性,从而有较高的教学有效性。
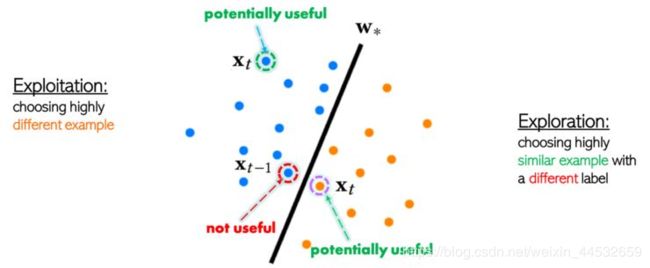
图 11:JEDI 教学的教学样本
真实场景的教学:
-JEDI 教学在现实场景中是无法直接估计 learner 学到的当前概念 wt 的,因此我们在 JEDI 里使用原目标函数的下限来解决这个优化问题:
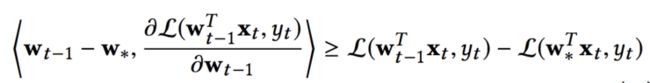
-JEDI 教学也需要样本的预测为正类的概率和预测为负类的概率作为输入,这两个参量也不是直接给予的,我们使用 harmonic function 来对他们进行估计:

总结:
JEDI 是一个基于机器教学为基础的自适应交互型众包教学框架,它假设每个 learner 都有指数型的记忆遗忘曲线,并且能够保证教学的有效性,多样性,以及教学样本的质量。
具体信息请参考我们的论文:
http://www.public.asu.edu/~yzhou174/
源代码:
https://github.com/collwe/JEDI-Crowd-Teaching
demo 展示:
http://198.11.228.162:9000/memory/index/
视频讲解:
https://www.youtube.com/watch?v=345o0QazwO8&t=4s
本文转载自:AI科技评论
更多数据:https://www.datatang.com/