网络爬虫之java 爬取京东手机数据案例
1、明确我们要爬取的数据都有什么
本文章适合对了解maven和springMVC框架的人更有帮助
1、京东的url:https://search.jd.com/Search?keyword=手机&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq=手机&cid2=653&cid3=655&s=56&click=0&page=
当你在京东首页搜索手机的时候,弹出的页面点击下一页,然后复制,将参数中有个page放到结尾。可以参考上面的url。

2、爬取的数据类型
spu:表示这款手机。

sku:表示该手机型号的不同型号(不同颜色),jd识别商品的编号

手机详情信息的Url

获取手机的图片
获取手机的价格
获取手机的标题
3、最后将这些数据存放到mysql中去,其中在加入创建时间和更新时间。
2、项目搭建
在IDEA中创建一个maven项目,完成该项目的目录如图所示:
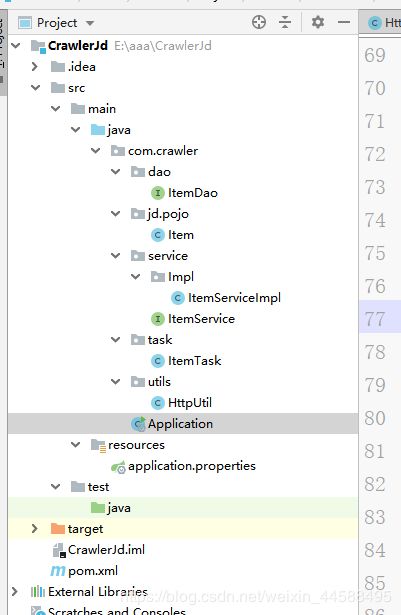
这里就不带大家一步一步创建这个目录了,如果你是小白可以参考https://blog.csdn.net/weixin_44588495/article/details/90580722
3、创建数据库表。
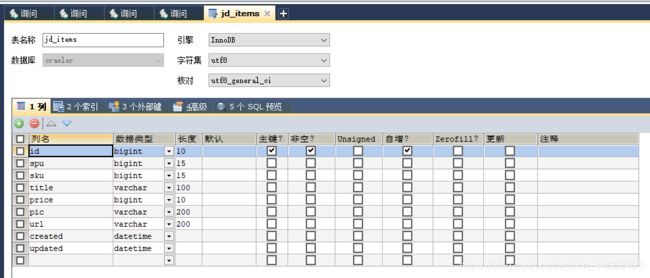
4、首先我们先看配置文件:
在这里我们添加了一些依赖,这里不在多说。如果对依赖有疑惑可以去看看之前的文章。
pom.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.1.5.RELEASE</version>
</parent>
<groupId>com.crawler</groupId>
<artifactId>CrawlerJd</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<!-- SpringMVC-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- SpringData Jpa-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<!-- mysql-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<!-- httpclient-->
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
</dependency>
<!-- jsoup-->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.10.2</version>
</dependency>
<!-- Util-->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
</dependency>
</dependencies>
</project>
application.properties文件
你需要做的就是把表明改了,数据库的账号密码校对,数据库类型。
#DB Configuration
spring.datasource.driverClassName=com.mysql.jdbc.Driver
spring.datasource.url=jdbc:mysql://localhost:3306/crawler?useUnicode=true&characterEncoding=utf8&serverTimezone=UTC
spring.datasource.username=root
spring.datasource.password=111111
#JPA Configuration
spring.jpa.database=MySql
spring.jpa.show-sql=true
5、dao目录下ItemDao类
这个文件就是对数据库进行操作的信息,具体的可以查看JpaRepository类源码。JpaRepository
package com.crawler.dao;
import com.crawler.jd.pojo.Item;
import org.springframework.data.jpa.repository.JpaRepository;
public interface ItemDao extends JpaRepository <Item,Long>{
}
6、jd.pojo目录下Item类
这个类其实就是用于存放在数据库中
package com.crawler.jd.pojo;
import net.bytebuddy.implementation.bind.annotation.Empty;
import javax.persistence.*;
import java.util.Date;
@Entity
@Table(name="jd_items")
public class Item {
//表内的属性
//主键
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private Long spu;
private Long sku;
private String title;
private double price;
private String pic;
private String url;
private Date created;
private Date updated;
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public Long getSpu() {
return spu;
}
public void setSpu(Long spu) {
this.spu = spu;
}
public Long getSku() {
return sku;
}
public void setSku(Long sku) {
this.sku = sku;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public double getPrice() {
return price;
}
public void setPrice(double price) {
this.price = price;
}
public String getPic() {
return pic;
}
public void setPic(String pic) {
this.pic = pic;
}
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
public Date getCreated() {
return created;
}
public void setCreated(Date created) {
this.created = created;
}
public Date getUpdated() {
return updated;
}
public void setUpdated(Date updated) {
this.updated = updated;
}
}
7、service目录下的ItemServiceImpl和ItemService
ItemService接口:这里定义了接口用于对数据库进行操作。
package com.crawler.service;
import com.crawler.jd.pojo.Item;
import java.util.List;
public interface ItemService {
/**
* 保存商品
* @param item
*/
public void save(Item item);
/**
* 查找商品
* @param item
* @return
*/
public List<Item> findAll(Item item);
}
ItemServiceImpl类:接口的实现类,这个类其实就是利用了ItemDao这个类的方法。
package com.crawler.service.Impl;
import com.crawler.dao.ItemDao;
import com.crawler.jd.pojo.Item;
import com.crawler.service.ItemService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.domain.Example;
import org.springframework.stereotype.Service;
import javax.transaction.Transactional;
import java.util.List;
@Service
public class ItemServiceImpl implements ItemService {
@Autowired
private ItemDao itemDao;
/**
* 保存数据
* @param item
*/
@Override
@Transactional //开启事务,提交事务
public void save(Item item) {
this.itemDao.save(item);
}
/**
* 查询数据
* @param item
* @return
*/
@Override
public List<Item> findAll(Item item) {
//声明查询条件
Example<Item> example = Example.of(item);
//根据查询条件进行查询数据
List<Item> list = this.itemDao.findAll(example);
return list;
}
}
8、工具类:HttpUtils
这个类包含了解析HTML和下载图片的方法
package com.crawler.utils;
import org.apache.http.client.config.RequestConfig;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.DefaultHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.impl.conn.PoolingHttpClientConnectionManager;
import org.apache.http.util.EntityUtils;
import org.springframework.stereotype.Component;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStream;
import java.util.UUID;
@Component
public class HttpUtil {
private PoolingHttpClientConnectionManager cm;
public HttpUtil(){
this.cm = new PoolingHttpClientConnectionManager();
//设置最大连接数
this.cm.setMaxTotal(100);
//设置最大主机连接数
this.cm.setDefaultMaxPerRoute(10);
}
public void Cookie(){
}
/**
* 根据请求地址下载页面数据
*/
public String doGetHtml(String url){
//获取HttpClient对象
CloseableHttpClient httpClient = HttpClients.custom().setConnectionManager(this.cm).build();
//创建httpGet请求对象,设置url
HttpGet httpGet = new HttpGet(url);
//设置请求Request Headers中的User-Agent,告诉京东说我这是浏览器访问,您只需要做一个安静的美男子就够了
httpGet.addHeader("User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36");
CloseableHttpResponse response = null;
//设置请求信息
httpGet.setConfig(this.getConfig());
try {
response = httpClient.execute(httpGet);
//判断响应,返回结果
if(response.getStatusLine().getStatusCode() == 200){
//判断响应体Entity是否为空,如果不为空就可以使用EmtityUtils
if(response.getEntity() != null){
String content = EntityUtils.toString(response.getEntity(),"utf-8");
return content;
}
}
} catch (IOException e) {
e.printStackTrace();
}finally{
if (response != null){
try {
response.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return "";
}
/**
* 下载图片
* @param url
* @return 图片名称
*/
public String doGetImage(String url){
//获取HttpClient对象
CloseableHttpClient httpClient = HttpClients.custom().setConnectionManager(this.cm).build();
//创建httpGet请求对象,设置url
HttpGet httpGet = new HttpGet(url);
CloseableHttpResponse response = null;
//设置请求信息
httpGet.setConfig(this.getConfig());
try {
response = httpClient.execute(httpGet);
//判断响应,返回结果
if(response.getStatusLine().getStatusCode() == 200){
//判断响应体Entity是否为空,如果不为空就可以使用EmtityUtils
if(response.getEntity() != null){
// 获取图片的后缀
String extName = url.substring(url.lastIndexOf('.'));
//创建图片名,重命名
String picName = UUID.randomUUID().toString() + extName;
//声明OutputStream
//下载图片
OutputStream outputStream = new FileOutputStream(new File("F:\\crawlerImages\\phone\\"+picName));
response.getEntity().writeTo(outputStream);
//返回图片名称
return picName;
}
}
} catch (IOException e) {
e.printStackTrace();
}finally{
if (response != null){
try {
response.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return "";
}
private RequestConfig getConfig() {
RequestConfig config = RequestConfig.custom()
.setSocketTimeout(1000)
.setConnectionRequestTimeout(500)
.setSocketTimeout(10000).build();
return config;
}
}
小伙伴们看到这里是不是已经很累了,但是上面的内容都不是今天的重点,重点在下面
提起精神、提起精神、提起精神重要的事情说三遍!!!
9、ItemTask类
在这里我要分的细细的给大家进行讲解,先分块最后让大家看整个类的代码,所以大家不要急哦。
这里建立了三个实例,第一个是工具类的对象。第二个是存入数据库的类,这里是接口引用对象。第三个下面会具体说。
@Autowired
private HttpUtil httpUtil;
@Autowired
private ItemService itemService;
private static final ObjectMapper MAPPER = new ObjectMapper();
这里的代码都不难理解,this.parse是我们下面要写的方法,有人可能要问了为什么for循环内是一次加二,这是因为jd本身的代码设定的就是第一页是1、第二页是3、第三页是5。
@Scheduled(fixedDelay = 100 * 1000)
public void itemTask() throws Exception{
//需要声明的解析初始地址
String url = "https://search.jd.com/Search?keyword=%E6%89%8B%E6%9C%BA&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq=%E6%89%8B%E6%9C%BA&cid2=653&cid3=655&s=56&click=0&page=";
//按照页面对手机的搜索结果进行遍历解析
for (int i =1;i < 10;i = i + 2){
String html = httpUtil.doGetHtml(url + i);
//解析页面,获取商品的数据b并存储
this.parse(html);
}
//数据抓取完
System.out.println("手机数据抓取完成");
}
this.parse方法
private void parse(String html)throws Exception {
}
下面都是parse方法的内容:
//解析html获取dom对象
Document document = Jsoup.parse(html);
//获取spu
Elements spuEles = document.select("div#J_goodsList>ul>li");
spuEles为:获取到了所有的li
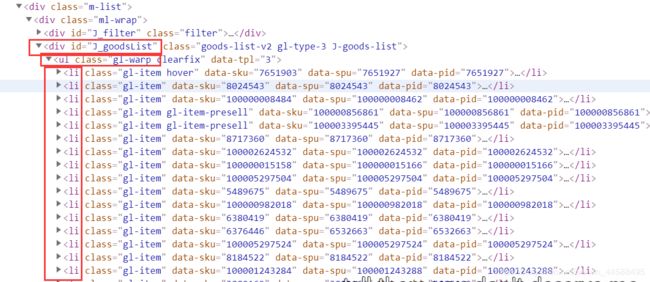
通过遍历spuEles获取其中的内容。首先获取到了spu这个属性,一个Li只对应一个spu。接着获取到了skuEles。
for (Element spuEle:spuEles) {
//获取spu
long spu = Long.parseLong(spuEle.attr("data-spu"));
//获取sku所在li
Elements skuEles = spuEle.select("li.ps-item");
}

这里存放的就是具体的信息。

遍历skuEles
for (Element spuEle:spuEles) {
//获取spu
long spu = Long.parseLong(spuEle.attr("data-spu"));
//获取sku所在li
Elements skuEles = spuEle.select("li.ps-item");
for ( Element skuEle:skuEles ){
}
}
接下来的代码都是第二层for循环中的内容
这里含有一部分查询当前的手机的sku是否再数据库中如果在数据库中就继续执行循环,不添加。在这里sku和spu组合是唯一识别jd商品的编号。这点一定要搞清楚。
//获取sku
long sku = Long.parseLong(skuEle.select("[data-sku]").attr("data-sku"));
//根据sku查询商品的数据
Item item = new Item();
item.setSku(sku);
List<Item> list = this.itemService.findAll(item);
//如果商品存在,就进行下一个循环,该商品不保存
if(list.size() > 0)
continue;
item.setSpu(spu);
这个手机的详情页就是sku.html,大家可以验证一下。
//获取商品详情信息的Url
String itemUrl = "https://item.jd.com/" + sku + ".html";
item.setUrl(itemUrl);
获取图片
//获取商品的图片
String picUrl = "https:" + skuEle.select("img[data-sku]").first().attr("data-lazy-img");
picUrl = picUrl.replace("n9","n1");
String picName = this.httpUtil.doGetImage(picUrl);
item.setPic(picName);
//获取手机的标题
//获取商品的标题
String itemInfo = this.httpUtil.doGetHtml(item.getUrl());
String title = Jsoup.parse(itemInfo).select("div.sku-name").text();
item.setTitle(title);
获取手机价格
//获取商品的价格
String priceJson = this.httpUtil.doGetHtml("https://p.3.cn/prices/mgets?skuIds=J_" + sku);
double price = MAPPER.readTree(priceJson).get(0).get("p").asDouble();
item.setPrice(price);
获取手机价格这个跟其他的获取方式不同:

当你用鼠标再这个三个上面移动的时候,实际上服务器已经发给你了一个回复,还有一个Url

这个是手机的价格信息。执行上面的代码就会获取到价格。

保存数据
//设置时间
item.setCreated(new Date());
item.setUpdated(item.getCreated());
//存储数据
this.itemService.save(item);
其实爬虫最主要的就是对HTML的解析。