十年电影票房数据爬取与分析 | 免费数据教程
3月8日妇女节,我很期待的超级英雄电影《惊奇队长》上映了,票房表现很快过亿,但大众口碑却让人失望。
一个有趣且常见的现象是,隔壁获奖无数,口碑爆炸的《绿皮书》,票房却远远不如《惊奇队长》。
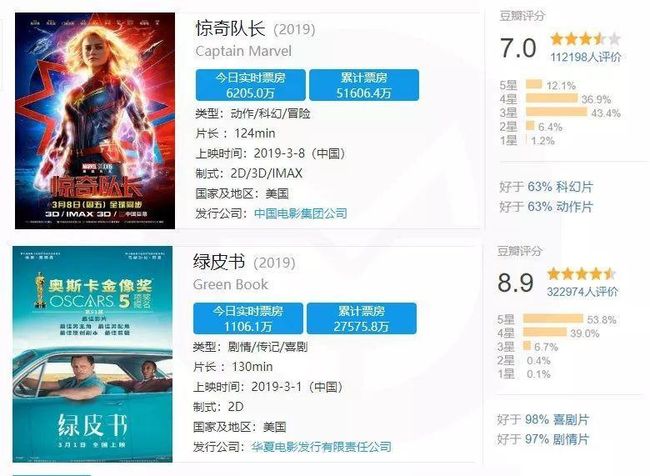
众所周知,中国市场是一个票房和口碑并不真正匹配的市场。因此,我决定从票房数据上看一看那些年中国市场电影的表现。
*本教程面向python及数据零基础爱好者,文末分享免费教程及资料福利。
#数据爬取:中国电影票房
我们选取某票房数据网站“单周票房数据”进行数据收集:
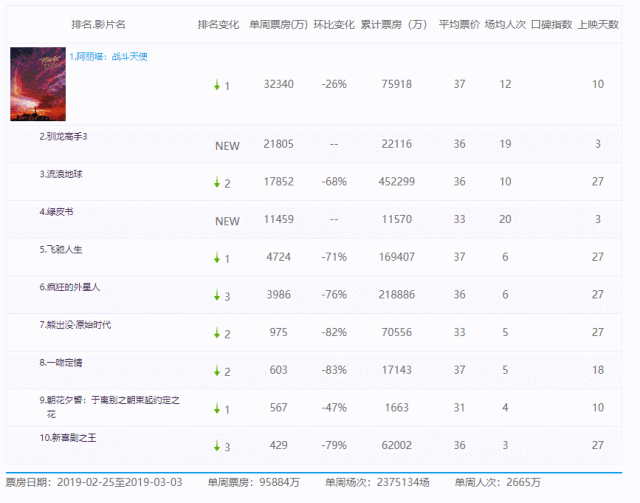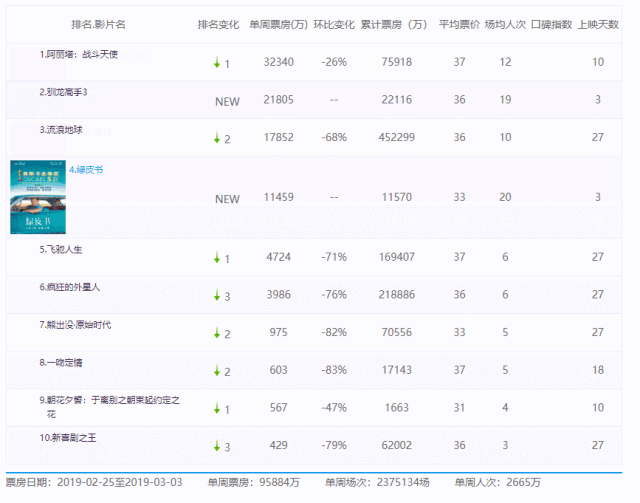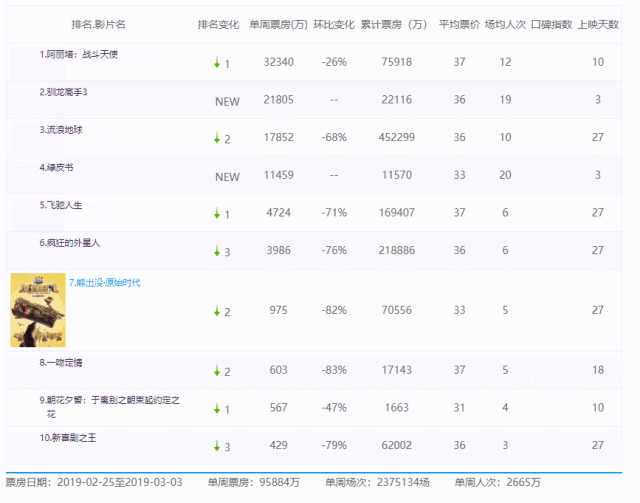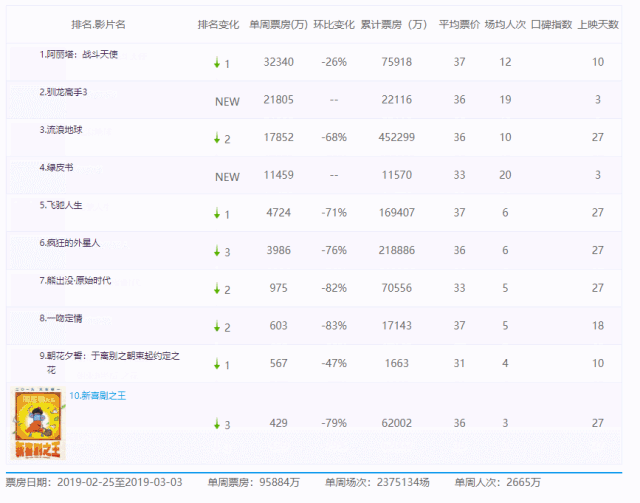
但该网站是一个动态网址,页面上只显示了近几周的票房数据。
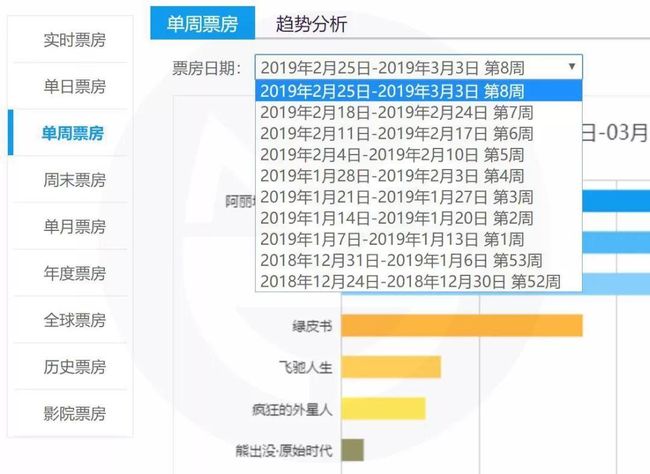
只有这么几周的数据当然不符合我的研究需求。我尝试使用使用fiddler进行抓包后,开心地发现了该网站的json数据及其真实网址:

fiddler是常用的网页抓包工具,它能够记录并检查所有你的电脑和互联网之间的http通讯,设置断点,查看所有的进出”Fiddler的cookie,html,js,css等文件,官网免费下载:https://www.telerik.com/download/fiddler
Json是一种轻量级的数据交换格式 易于人阅读和编写,同时也易于机器解析和生成,并有效地提升网络传输效率。
票房真实网址为:http://www.cbooo.cn/BoxOffice/getWeekInfoData?sdate=2018-04-09
真实网址由两部分组成,前面不变的地址和后面的日期。只需要改变网址最后的日期,就能查到想要的时间段数据了。我们将包含历年数据的网址放入爬取神器“八爪鱼采集器”中,就能访问历年的电影票房数据:
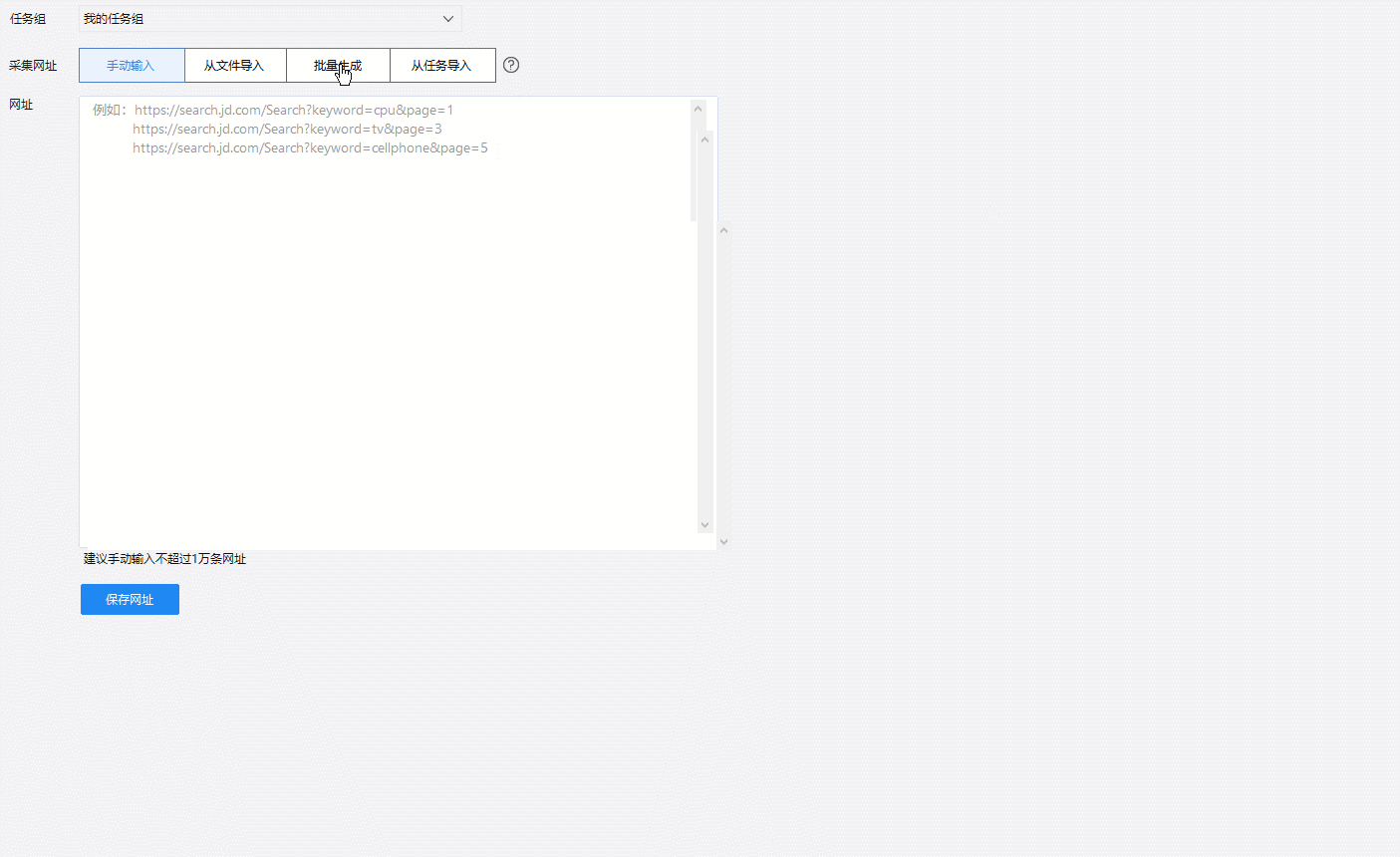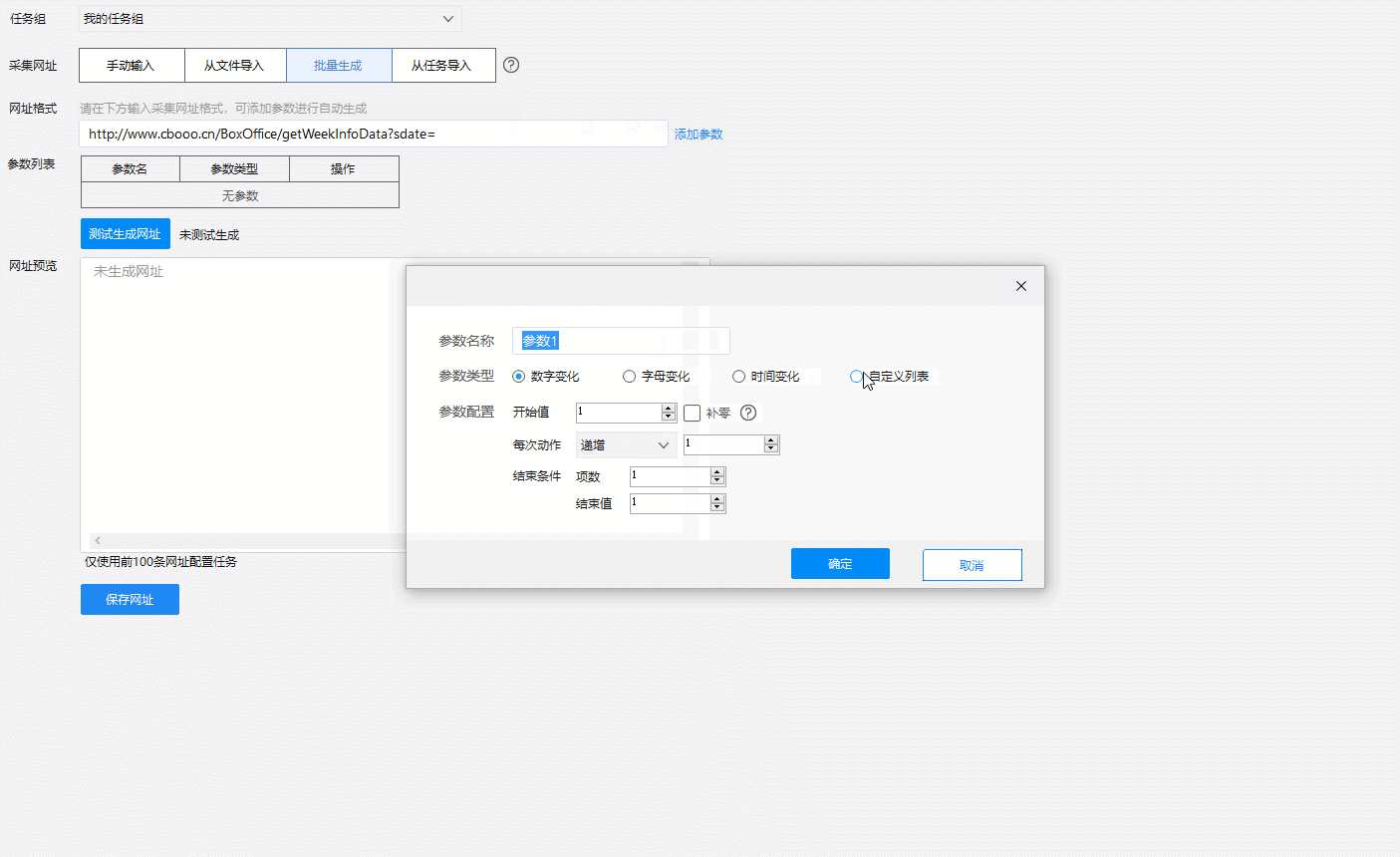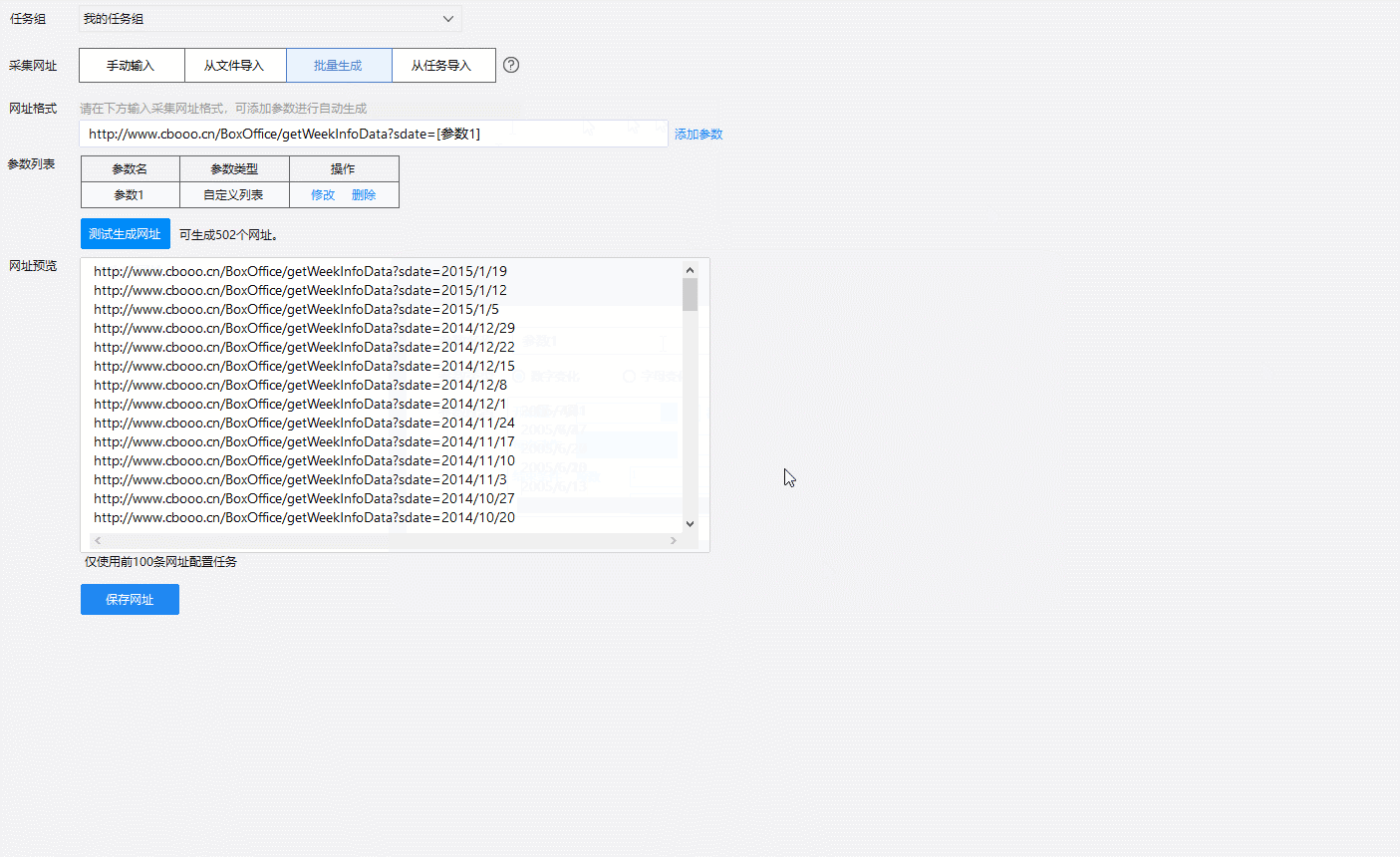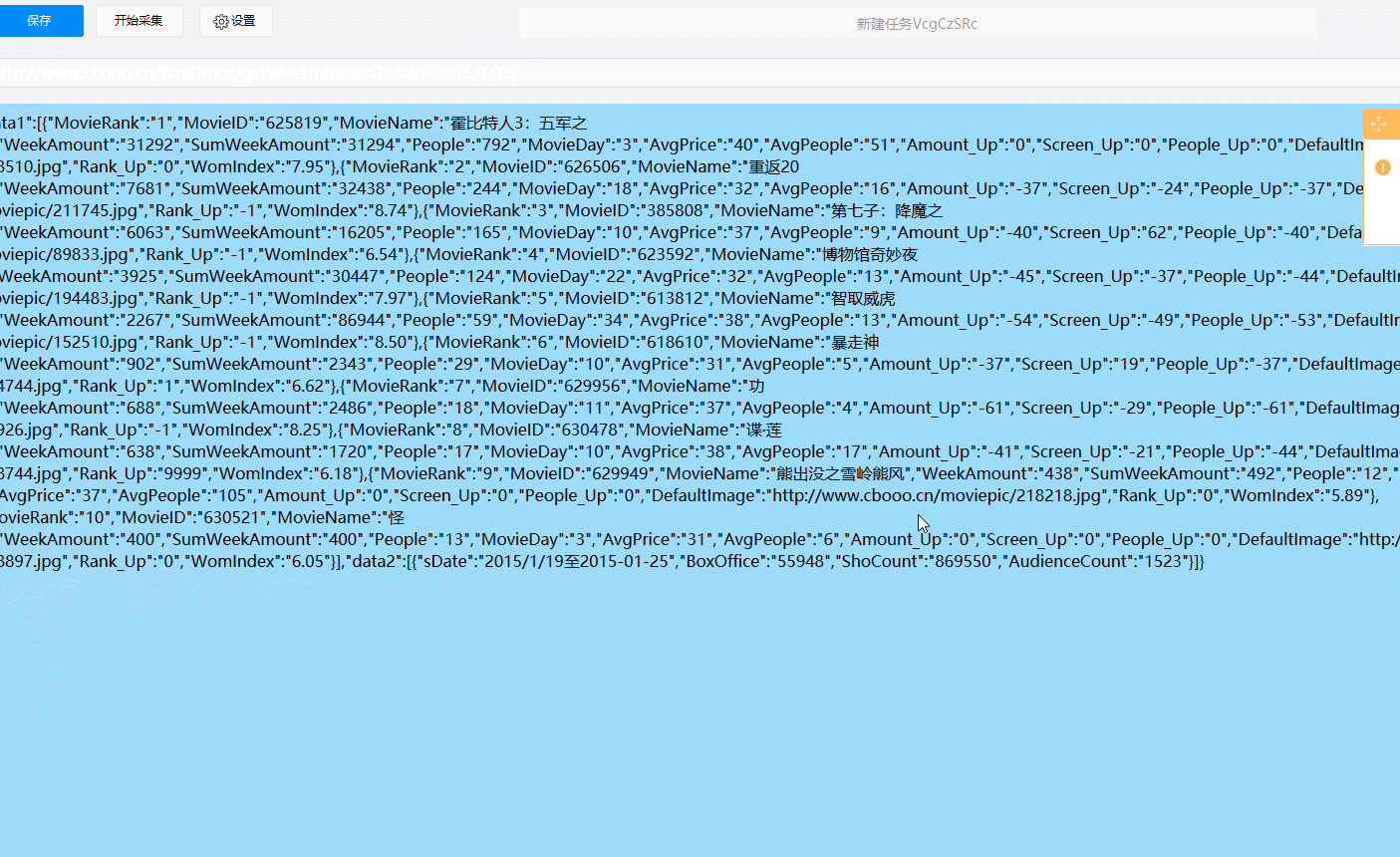
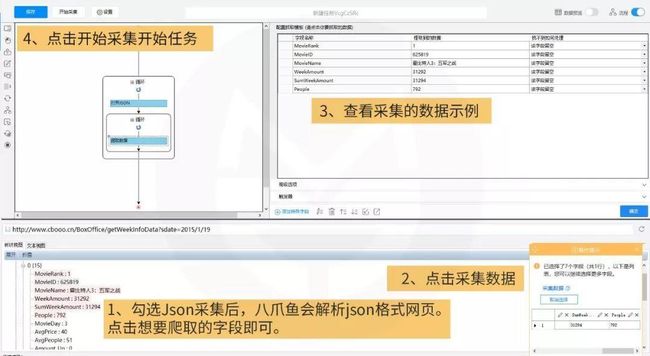
点两下,轻松开始爬数据。这份数据共有5800+条,包含20个字段,时间囊括了从2008年1月开始至2019年2月十一年期间的单周票房、累计票房、观影人次、场均人次、场均票价、场次环比变化等信息。
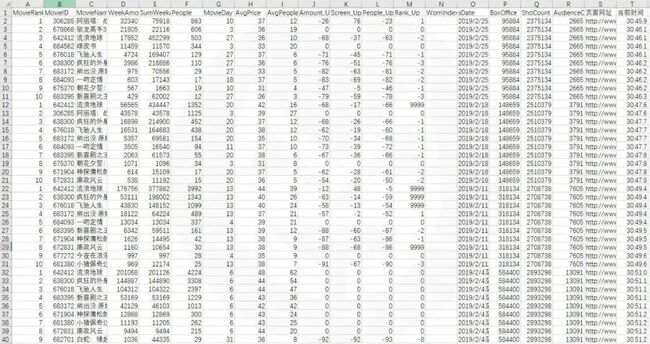
那么接下来就用python分析下这份数据,看看中国电影观众的观影喜好变化吧。
#数据分析:电影观众的口味
###1.票房表现:爱它就为它付钱。
首先筛选每一部电影总票房和周票房的最大值,并做排序,取前20:
#周票房TOP20分析
dataTop1_week = data[data['排名']==1][['电影名','周票房']]
dataTop1_week = dataTop1_week.groupby('电影名').max()['周票房'].reset_index()
dataTop1_week = dataTop1_week.sort_values(by='周票房',ascending=False)
#dataTop1_week.to_excel('周票房TOP1排名.xlsx',index=0)
#总票房TOP20分析
dataTop1_sum = data[data['排名']==1][['电影名','总票房']]
dataTop1_sum = dataTop1_sum.groupby('电影名').max()['总票房'].reset_index()
dataTop1_sum = dataTop1_sum.sort_values(by='总票房',ascending=False)
#dataTop20_sum.to_excel('总票房TOP1排名.xlsx',index=0)
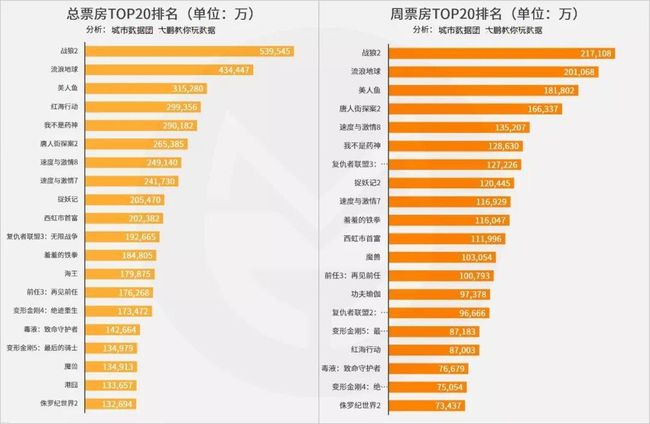
从数据上来看,观众们用电影票堆起了两座高山,吴京主演的两部电影《流浪地球》和《战狼》无论是总票房还是周票房表现,都是后面的电影望尘莫及的。排名靠前的绝大多数并不是好莱坞大片或者超级英雄电影,而是一些国产电影,特别是国产大制作电影。
总票房上,第1名和第20名票房差距超过4倍,单周票房上,第1名和第20名票房差距接近3倍。
###2.谁最坚挺:持久也是电影的硬本事
本数据记录的是每周票房前十的电影,计算一部电影出现在本数据里出现的次数,就能看到谁是票房榜上最持久的电影。
#上榜次数TOP10
data_count = data.groupby('电影名').count()['排名'].reset_index()
data_count.columns = ['电影名','频数']
data_count = data_count.sort_values(by='频数',ascending=False)
#data_count.to_excel('上榜次数TOP10.xlsx',index=0)
Top10结果如下:
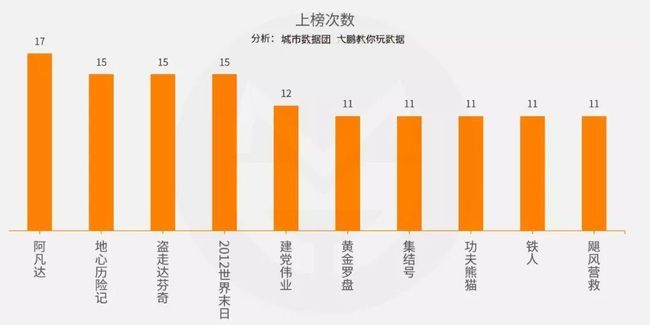
这批电影都有较长的上映天数安排,《阿凡达》《地心历险记》《2012》等耳熟能详的经典电影虽然不是票房冠军,但它们通过长期霸榜说明了自己的实力。而同样说明了自己的实力的电影还有《建党伟业》《集结号》《铁人》这样的主旋律,咱老百姓都爱看!
观众越来越重视电影院观影:又好又新的电影更容易突破票房纪录
将单周观影人数和单周总票房放在时间维度上观察,可以看出中国电影市场在过去十一年的增长情况:
#按时间分析票房变化
dataTime = data[['票房日期','单周总票房','单周总人次']]
dataTime['票房日期'] = dataTime['票房日期'].str.split('至').apply(lambda x:x[0])
dataTime['票房日期'] = pd.to_datetime(dataTime['票房日期'],format="%Y/%m/%d")
dataTime = dataTime.sort_values(by='票房日期').drop_duplicates()
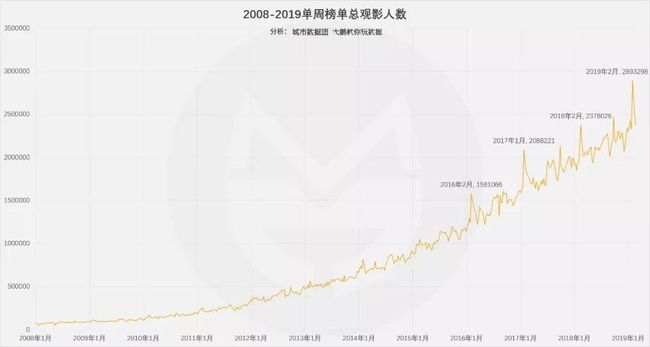
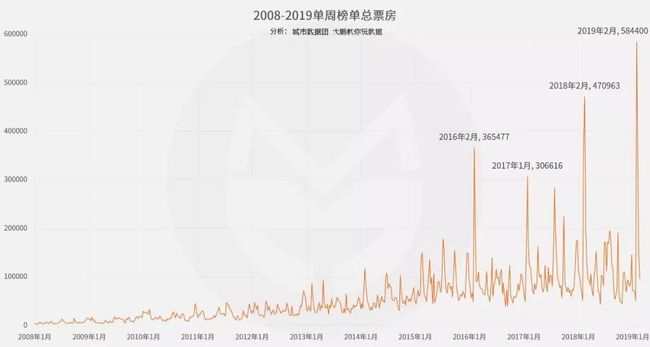
从2008年开始,单周总票房量和放映场次数总体呈浮动增长趋势,尤其是2014年后增长速度明显变快。其中单周总票房量2019年初较2008年初约有20倍的增长。观众相比以前越来越愿意去电影院消费,所以目前在总票房榜上的电影,也大多是近年来的新电影。
此外,观察峰值出现的时段,可以发现2016年开始,每年春节假期都会出现票房爆炸,这一方面反映了贺岁档电影质量不断提升,另一方面也反映了国内观众将看电影作为假日文化娱乐主要选择的倾向。
有口碑还不够:能坚持、能造势、口碑强、排片高才是票房高的保证
回到最开始的问题,口碑好的电影不一定能获得高票房。我们可以使用eXtreme Gradient Boosting模型,分析哪些因素对票房有决定性影响。
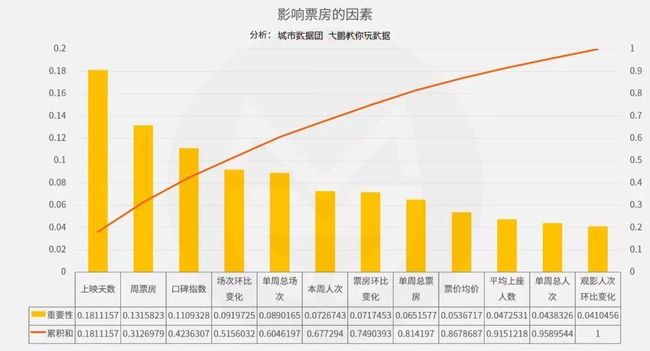
对票房成绩起决定性影响的因素是:上映天数,周票房,口碑指数,场次环比变化,重要性累积达到50%+。
如果一部影片能长久坚持在院线(上映天数);宣发好,上映后每周票房都表现优秀(周票房);并众所周知,口碑不错(口碑指数);能让更多影院为它排片(场次环比变化),那么在总票房上取得成功的概率会显著提升。
#大鹏教你玩票房数据
如果你看到这里,恭喜你获得了一次免费数据技能学习机会,大鹏将手把手教你爬取、分析可视化中国电影票房数据(本教程不需要有python基础)。

大鹏教你玩数据是一个系列教程,用有趣的主题讲好数据故事,主题还包括:
女朋友365天有360天都在水逆?数据告诉你星座的秘密
工作职责描述到底是什么意思?就业数据指南
全职高手人物关系指南
那些铁路覆盖不到的地方究竟是哪里?
主题将不断更新中,快扫海报上的二维码,关注公众号【大鹏教你玩数据】,回复“票房”,获取上课地址吧。