Knn算法实现(鸢尾花数据集)
一、题目
原生Python实现Knn分类算法,使用鸢尾花数据集进行测试
二、算法分析
目的:对一个新的数据点的标签做出预测
算法思想:算法会在训练集中寻找与这个数据点距离最近的数据点,然后将找到的数据点的标签赋值给这个新的数据点
本次算法采用欧氏距离计算法对不同数据点之间的距离进行计算
三、程序流程图
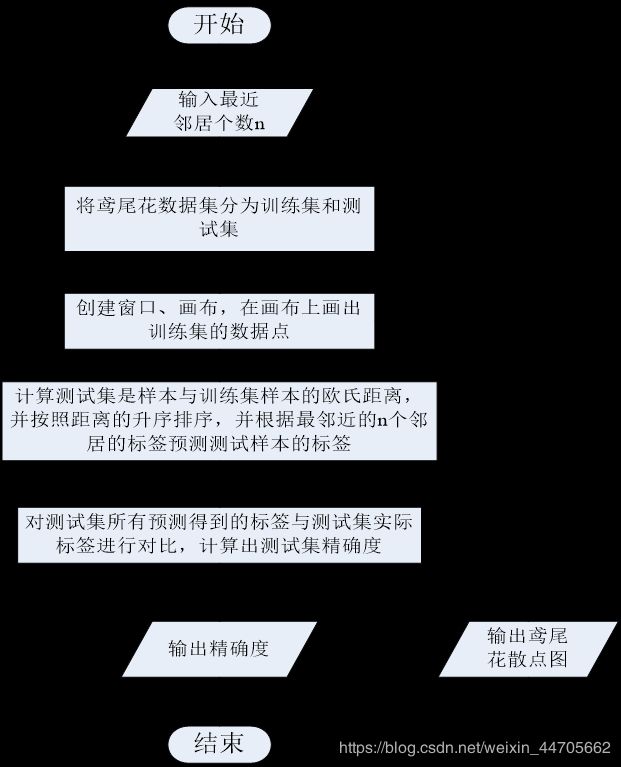
四、测试与调试
欧氏距离进行调试
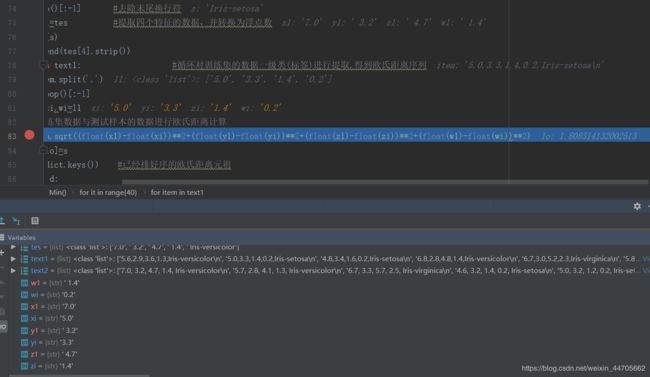
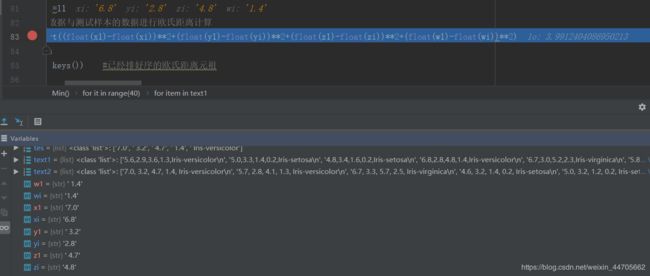
五、运行截图
每次运行都会讲鸢尾花数据集重新分配为训练集和测试集,因此每次运行的精确度都会有不同
最近邻居个数不同,精确度也不同
精确度为85%
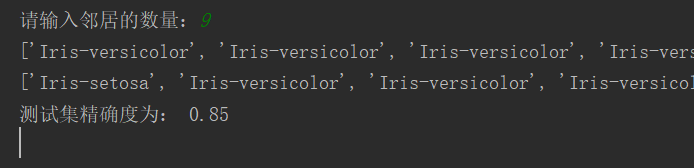
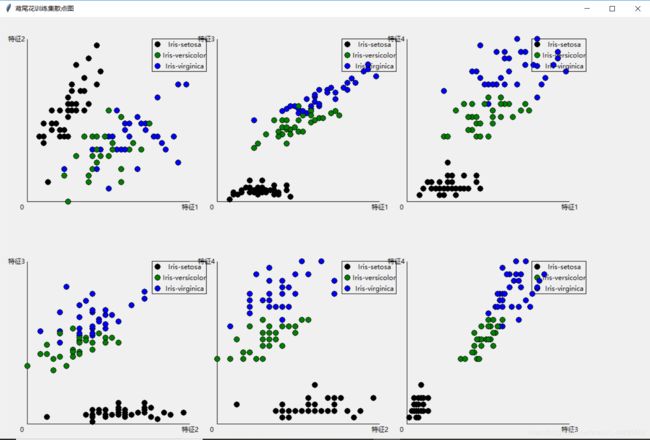
精确度为80%

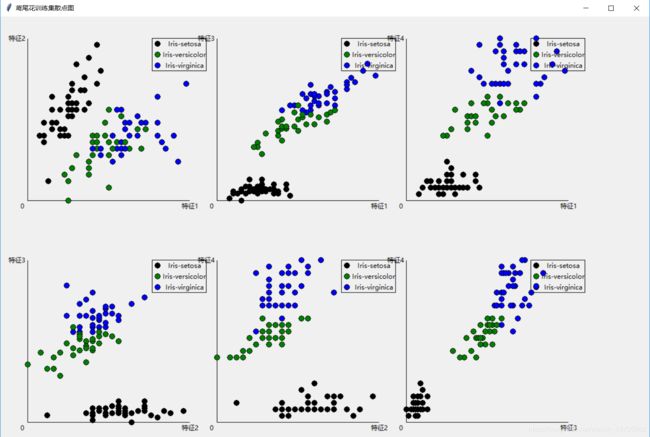
六、源代码
import random
import math
import tkinter as tk
def Data():
file = open('iris.txt', 'r')
ftrain = open('train.txt', 'w+')
ftest = open('test.txt', 'w+')
text=file.readlines()
random.shuffle(text) #随机打乱鸢尾花数据集
i=0 #用i标记训练集和测试集数据的比例,训练集110个样本,测试集39个样本
for item in text: #训练集110个样本
if i<110:
ftrain.write(item)
else:
tlist=item.split(',')
s=tlist.pop()[:-1]
tlist.append(s)
s=', '.join(tlist)
ftest.write(s+'\n')
i+=1
file.close()
ftrain.close()
ftest.close()
def PaintTrain():
ftrain = open('train.txt', 'r') #x轴长300,y轴长300,
text = ftrain.readlines()
dx={1:50,2:400,3:750,4:50,5:400,6:750} #四个坐标轴的远点的x坐标
dy={1:340,2:340,3:340,4:750,5:750,6:750} #四个坐标轴的远点的y坐标
d1={1:1,2:1,3:1,4:2,5:2,6:3} #X轴代表的特征序号
d2={1:2,2:3,3:4,4:3,5:4,6:4} #X轴代表的特征序号
for i in range(6):
canvas.create_line(dx[i+1],dy[i+1],dx[i+1]+width,dy[i+1])
canvas.create_line(dx[i+1],dy[i+1],dx[i+1],dy[i+1]-heigth)
labx="特征"+str(d1[i+1])
laby="特征"+str(d2[i+1])
canvas.create_text(dx[i+1]+width,dy[i+1]+10,text=labx)
canvas.create_text(dx[i+1]-20,dy[i+1]-heigth,text=laby)
canvas.create_text(dx[i+1]-10,dy[i+1]+10,text="0")
canvas.create_rectangle(dx[i+1]+230,dy[i+1]-300,dx[i+1]+330,dy[i+1]-240)
canvas.create_oval(dx[i+1]+240-5,dy[i+1]-290-5,dx[i+1]+240+5,dy[i+1]-290+5,fill='black')
canvas.create_oval(dx[i+1]+240-5,dy[i+1]-270-5,dx[i+1]+240+5,dy[i+1]-270+5,fill='green')
canvas.create_oval(dx[i+1]+240-5,dy[i+1]-250-5,dx[i+1]+240+5,dy[i+1]-250+5,fill='blue')
canvas.create_text(dx[i+1]+290,dy[i+1]-290,text="Iris-setosa")
canvas.create_text(dx[i+1]+290,dy[i+1]-270,text="Iris-versicolor")
canvas.create_text(dx[i+1]+290,dy[i+1]-250,text="Iris-virginica")
for item in text: #将训练集数据画在坐标轴上,特征一:4~8;特征二:2~4.5;特征三:1~7;特征:0~0.25
tlist=item.split(',')
s=tlist.pop()[:-1]
xi,yi,zi,wi=tlist
tlist.append(s)
#样本的X、Y轴坐标处理
xi=(float(xi)-4)/4.0*300
yi=(float(yi)-2)/2.5*300
zi=(float(zi)-1)/7.0*300
wi=(float(wi))/2.5*300
d3 = {1: xi, 2: yi, 3: zi, 4: wi}
if s=="Iris-setosa":
canvas.create_oval(d3[d1[i+1]]+dx[i+1]-5, dy[i+1]-d3[d2[i+1]]-5, d3[d1[i+1]]+dx[i+1]+5, dy[i+1]-d3[d2[i+1]]+5, fill='black')
if s =="Iris-versicolor":
canvas.create_oval(d3[d1[i+1]]+dx[i+1]-5, dy[i+1]-d3[d2[i+1]]-5, d3[d1[i+1]]+dx[i+1]+5, dy[i+1]-d3[d2[i+1]]+5, fill='green')
if s =="Iris-virginica":
canvas.create_oval(d3[d1[i+1]]+dx[i+1]-5, dy[i+1]-d3[d2[i+1]]-5, d3[d1[i+1]]+dx[i+1]+5, dy[i+1]-d3[d2[i+1]]+5, fill='blue')
def Min(n):
ftrain = open('train.txt', 'r')
text1 = ftrain.readlines()
ftest = open('test.txt', 'r')
text2 = ftest.readlines()
for it in range(40):
mdict=dict() #创建字典用来存放训练集样本的 欧氏距离:标签
sorted_dict = dict() #用来存放已经排好序的训练集样本的 欧氏距离:标签
tes=text2[it].split(',')
s = tes.pop()[:-1] #去除末尾换行符
x1,y1,z1,w1=tes #提取四个特征的数据,并转换为浮点数
tes.append(s)
tlable.append(tes[4].strip())
for item in text1: #循环对训练集的数据一级类(标签)进行提取,得到欧氏距离序列
l1= item.split(',')
s= l1.pop()[:-1]
xi,yi,zi,wi=l1
# 对训练集数据与测试样本的数据进行欧氏距离计算
lo=math.sqrt((float(x1)-float(xi))**2+(float(y1)-float(yi))**2+(float(z1)-float(zi))**2+(float(w1)-float(wi))**2)
mdict[lo]=s
d=sorted(mdict.keys()) #已经排好序的欧氏距离元祖
for ite in d:
sorted_dict[ite]=mdict[ite]
t1=t2=t3=g=0
a={"Iris-setosa":t1,"Iris-versicolor":t2,"Iris-virginica":t3}
for item in sorted_dict.items(): # n代表n个邻居
if g>=n:
break
g+=1
if item[1] == "Iris-setosa":
a["Iris-setosa"]=a["Iris-setosa"]+1
if item[1] == "Iris-versicolor":
a["Iris-versicolor"]=a["Iris-versicolor"]+1
if item[1] == "Iris-virginica":
a["Iris-virginica"]=a["Iris-virginica"]+1
mtlable.append("###")
max=a["Iris-setosa"]
mtlable[len(mtlable)-1] = "Iris-versicolor"
if max七、总结
对python的不熟练导致在编写代码时做了许多无用功。
此次算法的测试集精确度较低,普遍在75%左右,最高达到85%,其中涉及的欧氏距离的计算、字典的排序还没有发现问题,结果精确度却过低。
在绘图上,挺好玩。