数据分析真题日刷 | 京东2019春招京东数据分析类试卷
开启一个新的系列 —— 「数据分析真题日刷」。七月临近,备战秋招,加油鸭!
- 今日真题
京东2019春招京东数据分析类试卷(来源:牛客网) - 题型
客观题:单选27道,不定项选择3道 - 完成时间
120分钟
❤️ 「更多数据分析真题」
《数据分析真题日刷 | 目录索引》
1. 在软件开发过程中,我们可以采用不同的过程模型,下列有关增量模型描述正确的()
A. 已使用一种线性开发模型,具有不可回溯性
B, 把待开发的软件系统模块化,将每个模块作为一个增量组件,从而分批次地分析、设计、编码和测试这些增量组件
C. 适用于已有产品或产品原型(样品),只需客户化的工程项目
D. 软件开发过程每迭代一次,软件开发又前进一个层次
正确答案: B
?增量模型
增量模型也称为渐增模型,是把待开发的软件系统「模块化」,将每个模块作为一个增量组件,从而分批次地分析、设计、编码和测试这些增量组件。
- 优点:
(1)将待开发的软件系统模块化,可以「分批次地提交软件产品」,使用户可以及时了解软件项目的进展。
(2)以组件为单位进行开发「降低了软件开发的风险」。一个开发周期内的错误不会影响到整个软件系统。
(3)「开发顺序灵活」。开发人员可以对组件的实现顺序进行优先级排序,先完成需求稳定的核心组件。当组件的优先级发生变化时,还能及时地对实现顺序进行调整。- 缺点
(1)要求待开发的软件系统可以被模块化。如果待开发的软件系统很难被模块化,那么将会给增量开发带来很多麻烦。
(来源:百度百科)
-
其他参考
(1)https://www.jianshu.com/p/34a25377a4e2
(2)https://blog.csdn.net/iteye_16868/article/details/81426760
(3)https://blog.csdn.net/elementf/article/details/76909994 -
本题知识点
软件开发的各种生命周期模型。拓展延伸其他模型(待补充)。
2. 一颗二叉树的前序遍历是ABCDFGHE,后序遍历是BGHFDECA,中序遍历是?
A. GHBADFCE
B. DGBAFHEC
C. BADGFHCE
D. BAGDFHEC
正确答案:C
?二叉树的前序、中序、后序三种遍历
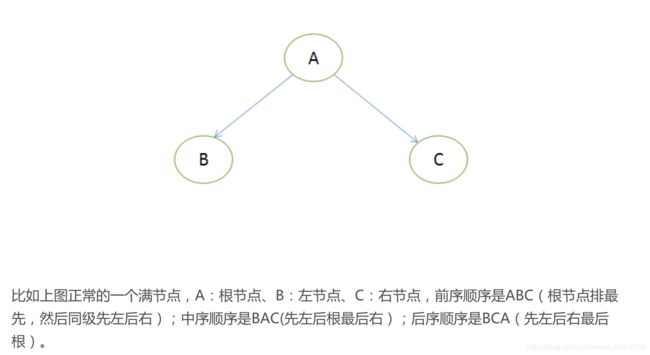
(来源:https://blog.csdn.net/qq_33243189/article/details/80222629)
- 强烈参考:
(1)《关于二叉树的前序、中序、后序三种遍历》
(2)《二叉树的前序中序后序遍历相互求法》
我个人的二叉树结构如下图,仅供参考。

3.关于TCP协议的描述,以下错误的是?
A. 面向连接
B. 可提供多播服务
C. 可靠交付
D. 报文头部长,传输开销大
正确答案:B
?TCP协议
TCP(Transmission Control Protocol
传输控制协议)是一种面向连接的、可靠的、基于字节流的传输层通信协议,由IETF的RFC 793定义。
(来源:百度百科)
- 强烈参考:
《TCP协议》
对B选项, TCP不提供广播或多播服务
对D选项,由于TCP要提供可靠的面向连接的传输服务,因此增加了许多开销,确认、流量控制、计时器及连接管理等
4.以下命令用于设置环境变量的是:
A. export
B. cat
C. echo
D. env
正确答案:A
?关于环境变量的命令
export: 设置环境变量
echo:查看是否成功
env:显示所有的环境变量
set:显示所有本地定义的Shell变量
unset:清除环境变量
- 强烈参考:
(1)《set、env、export——Linux中的环境变量命令》
(2)《环境变量设置export 命令详解》
5.数据库事务的特性不包含:
A. 原子性
B. 并发性
C. 一致性
D. 持久性
正确答案:B
?数据库事务的四大特性:原子性、一致性、隔离性、持久性
(1)原子性(Atomicity)
原子性是指事务包含的所有操作要么全部成功,要么全部失败回滚,因此事务的 操作如果成功就必须要完全应用到数据库,如果操作失败则不能对数据库有任何影 响。(2) 一致性(Consistency)
一致性是指事务必须使数据库从一个一致性状态变换到另一个一致性状态,也就是说一个事务执行之前和执行之后都必须处于一致性状态。
(3)隔离性(Isolation)
隔离性是当多个用户并发访问数据库时,比如操作同一张表时,数据库为每一个用户开启的事务,不能被其他事务的操作所干扰,多个并发事务之间要相互隔离。
(4)持久性(Durability)
持久性是指一个事务一旦被提交了,那么对数据库中的数据的改变就是永久性的,即便是在数据库系统遇到故障的情况下也不会丢失提交事务的操作。
(来源:百度知道《数据库事务四大特性是什么?》)
6.索引是对数据库表中一个或多个列的值进行排序的数据结构,以协助快速查询、更新数据库表中数据。以下对索引的特点描述错误的是:
A. 加快数据的检索速度
B. 加速表和表之间的连接
C. 在使用分组和排序子句进行数据检索时,并不会减少查询中分组和排序的时间
D. 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性
正确答案:C
?索引的特点
- 创建索引的好处
(1)通过创建索引,可以在查询的过程中,提高系统的性能
(2)通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性
(3)在使用分组和排序子句进行数据检索时,可以减少查询中分组和排序的时间- 创建索引的坏处
(1)创建索引和维护索引要耗费时间,而且时间随着数据量的增加而增大
(2)索引需要占用物理空间,如果要建立聚簇索引,所需要的空间会更大
(3)在对表中的数据进行增加删除和修改时需要耗费较多的时间,因为索引也要动态地维护
(来源:《数据库索引》https://blog.csdn.net/qq_36071795/article/details/83956068 )
7. 如果ORDER BY子句后未指定ASC或DESC,默认使用以下哪个?
A. DESC
B. ASC
C. 不存在默认值
D. 其它选项都不对
正确答案:B
8.关于Python中的复数,下列说法错误的是()
A. 表是复数的语法是real + image j
B. 实部和虚部都是浮点数
C. 虚部必须后缀j,且必须小写
D. 方法conjugate返回复数的共轭复数
正确答案:C
?Python中的复数
(1)表是复数的语法是real + image j
(2)实部和虚部都是浮点数
(3)虚部后缀可以是 j 或 J
(4)方法conjugate返回复数的共轭复数
9.执行以下shell语句,可以生成/test文件的是(假定执行前没有/test文件):
A. touch /test
B. a=touch /test
C. >/test
D. echo ‘touch /test’
正确答案:A B C
(待解析,欢迎评论指导~)
10. if [ $2 -a $2 = “test” ]中 -a是什么意思
A. 大于
B. 减
C. 全部
D. 并且
正确答案:D
? Linux_shell的逻辑判断
| -a | 与 |
|---|---|
| -o | 或 |
| ! | 非 |
- 强烈参考
《Linux_shell条件判断if中的-a到-z的意思》
11.文件目录data当前权限为rwx — ---,只需要增加用户组可读权限,但不允许写操作,具体方法为:
A. chmod+050data
B. chmod+040data
C. chmod+005data
D. chmod+004data
正确答案:A
参考解析:
使用chomd命令改变文件权限。Linux文件基本权限有9个,owner,group,others三种身份对应各自read,write,execute三种权限。文件权限字符:“-rwxrwxrwx”三个一组。数字化r:4
w:2 x:1 增加用户组可读,但不可写,第一组和第三组默认为0,只在第二组中添加r-x即可 chomd +050
(来源:牛客网,https://www.nowcoder.com/questionTerminal/2276e48a891f4ddfaee6bbacec1d5860?orderByHotValue=1&page=1&onlyReference=false)
(欢迎在评论区解析指导~)
12.以下哪个模型是生成式模型:
A. 贝叶斯模型
B. 逻辑回归
C. SVM
D. 条件随机场
正确答案:A
?生成式模型 ? 判别式模型
(1)区别与联系
生成式模型对联合分布P(x,y)建模,而判别式模型对P(y|x)建模。
生成式模型可以通过贝叶斯公式得到判别式模型,而判别式模型不能得到生成式模型。
(2)常见生成式模型
朴素贝叶斯,隐马尔科夫模型,高斯混合模型,贝叶斯网络
(3)常见判别式模型
KNN,SVM,决策树,线性回归,boosting,条件随机场,感知机,传统神经网络,逻辑斯蒂回归,CART
- 强烈参考
《谈谈判别式模型与生成式模型》(https://blog.csdn.net/huangfei711/article/details/79834780)
《判别式模型与生成式模型》(https://www.cnblogs.com/yejintianming00/p/9378810.html)
13. 下列关于计算机存储容量单位的说法中,错误的是()
A. 1KB<1MB<1GB
B. 基本单位是字节(Byte)
C. 一个汉字需要一个字节的存储空间
D. 一个字节能够容纳一个英文字符
正确答案:C
一个汉字需要两个字节,一个英文字符需要一个字节的储存空间。
14.以下机器学习中,在数据预处理时,不需要考虑归一化处理的是:
A. logistic回归
B. SVM
C. 树形模型
D. 神经网络
正确答案:C
?归一化处理
Tree-based models doesn’t depend on scaling
Non-tree-based models hugely depend on scaling
对数模型,数值缩放不影响分裂点位置,因此特征值排序的顺序不变,那么所属的分支以及分裂点就不会有不同。
- 强烈推荐:
《机器学习中数据预处理——标准化/归一化方法(scaler)》(https://blog.csdn.net/qq_33472765/article/details/85944256)
《今日面试题分享:树形结构为什么不需要归一化?》
(https://baijiahao.baidu.com/s?id=1625978541816519992&wfr=spider&for=pc)
15. 从使用的主要技术上看,可以把分类方法归结为哪几种类型
A. 规则归纳方法
B. 贝叶斯分类方法
C. 决策树分类方法
D. 基于距离的分类方法
正确答案:A B C D
?分类方法四种类型
(1)基于距离的分类方法(最临近方法);
(2)决策树分类方法(ID3和C4.5算法);
(3)贝叶斯分类方法(朴素贝叶斯算法和EM算法);
(4)规则归纳(AQ算法、CN2算法和FOIL算法)等。
(待补充规则归纳的知识~)
- 参考资料:
《机器学习-分类简单介绍)(https://www.cnblogs.com/gccbuaa/p/6756828.html)
16.数据挖掘的挖掘方法包括:( )
A. 聚类分析
B. 回归分析
C. 神经网络
D. 决策树算法
正确答案:A B C D
17.检测一元正态分布中的离群点,属于异常检测中的基于( )的离群点检测
A. 统计方法
B. 邻近度
C. 密度
D. 聚类技术
正确答案:A
18. 熵是为消除不确定性所需要获得的信息量,投掷均匀正六面体骰子的熵是:
A. 1比特
B. 2.6比特
C. 3.2比特
D. 3.8比特
正确答案:B
?熵

H = - 6 * (1/6) * log 2(1/6) = 2.58
19. 以下相关关系取值,哪个蕴含了无关系?
A. Cor(X, Y) = 1
B. Cor(X, Y) = 0
C. Cor(X, Y) = 2
D. 其他都是
正确答案:B
20. 下列关于大数据的分析理念的说法中,错误的是()
A. 在数据基础上倾向于全体数据而不是抽样数据
B. 在分析方法上更注重相关分析我不是因果分析
C. 在分析效果上更追究效率而不是绝对精确
D. 在数据规模上强调相对数据而不是绝对数据
正确答案:D
21. 置信概率可以用来评估区间估计的什么性能
A. 精确性
B. 显著性
C. 规范性
D. 可靠性
正确答案:D
?置信度
置信度(置信水平)是也称为可靠度,或置信系数,即在抽样对总体参数作出估计时,由于样本的随机性,其结论总是不确定的。是指正确的概率。(1-α 为置信度或置信水平其表明了区间估计的可靠性)
(来源:https://blog.csdn.net/u014689510/article/details/50358258)
- 强烈参考
《置信度,置信区间,区间估计》(https://blog.csdn.net/u014689510/article/details/50358258)
22. 为数据的总体分布建模;把多维空间划分成组等问题属于数据挖掘的哪一类任务?
A. 探索性数据分析
B. 建模描述
C. 预测建模
D. 寻找模式和规则
正确答案:B
(待解析~)
23. 下列关于普查的缺点的说法中,正确的是()
A. 工作量较大,容易导致调查内容有限、产生重复和遗漏现象
B. 误差不易被控制
C. 对样本的依赖性比较强
D. 评测结果不够稳定
正确答案:A
? 普查的优缺点
- 优点
(1)由于是调查某一人群的所有成员,所以在确定调查对象上比较简单;
(2)所获得的资料全面,可以知道全部调查对象的相关情况,准确性高;
(3)普查所获得的数据为抽样调查或其他调查提供基本依据。- 缺点
(1)工作量大,花费大,组织工作复杂;
(2)调查内容有限;
(3)易产生重复和遗漏现象;
(4)由于工作量大而可能导致调查的精确度下降,调查质量不易控制。
(来源:百度百科)
24. 数据科学家使用的统计方法有( )
A. 马尔科夫过程
B. 等价划分类
C. 线性累加
D. 不知道
正确答案:A
25.在下列算法中,对于缺失值敏感的模型为:
A. 随机森林
B. Logistic Regression(逻辑回归)
C. C4.5
D. 朴素贝叶斯
正确答案:B
AC基于树模型,对缺失值敏感度低;D朴素贝叶斯对缺失值也比较稳定;B逻辑回归是线性模型,对缺失值敏感。
?缺失值对模型的影响
(1)树模型对于缺失值敏感度低,其本身就可以把缺失值当成一类;
(2)基于距离度量的模型对于缺失值敏感度高,如K近邻算法(KNN)和支持向量机(SVM);
(3)线性模型的代价函数(loss function)往往涉及到距离的计算,计算预测值和真实值之间的差别,这容易导致对缺失值敏感;
(4)神经网络对缺失值不是非常敏感;
(5)贝叶斯对缺失值也比较稳定,数据量小的时候推荐。
总结来看,对于有缺失值的数据在经过缺失值处理后:
- 数据量很小,用朴素贝叶斯
- 数据量适中或者较大,用树模型,优先 xgboost
- 数据量较大,也可以用神经网络
- 避免使用距离度量相关的模型,如KNN和SVM
- 强烈参考
《面对数据缺失,如何选择合适的机器学习模型?》(https://www.jianshu.com/p/db798b5a66db)
26. 京东仓库中对某种商品进行合格性检验,已知这种商品的不合格率为0.001,即1000件商品中会有一件次品。现有现有一种快速检验商品方法,它的准确率是0.99,即在商品确实是次品的情况下,它有99%的可能抽检显示红色。它的误报率是5%,即在商品不是次品情况下,它有5%的可能抽检显示红色。现有有一件商品检验结果为红色,请问这件商品是次品的可能性有多大?
A. 0.01
B. 0.02
C. 0.03
D. 0.04
正确答案:B
?考点:贝叶斯公式
解析题目:
已知 : P(次品)= 0.001, P(红|次品)= 0.99, P(红|正品) = 0.05
则,
P(正品)=1 - 0.001 = 0.999,
P(红色且次品) = P(红|次品) x P(次品)
P(红色且正品) = P(红|正品) x P(正品)
P(红) = P(红色且次品) + P(红色且正品)=0.99x0.001 + 0.05x0.999=0.05094
根据贝叶斯公式,
P(次品|红)= P(红|次品) x P(次品) / P(红)= 0.99 x 0.001 / 0.05094 = 0.02
27.有30个需要渡河,只有一条船,船每次最多载4人(包括划船的人),往返一次需要5分钟。那么,21分钟后,还有几个人在等待过河?( )
A. 10
B. 11
C. 15
D. 16
官方答案:B
民间答案:14
(待解析~)
28. 一批商品,甲乙合作生产需要10天完成,乙丙两人合作生产需要12天。现在油甲丙合作生产4天,剩下的交由乙单独生产,还需要12天才能完成。如果该批商品由乙单独完成,需要多少天?( )
A. 15
B. 18
C. 20
D. 25
正确答案:A
题目解析:
设甲乙丙单独完成分别需要x,y,z天,则
10 *(1/x + 1/y )= 1
12 * (1/y + 1/z ) = 1
4 * (1/x + 1/z ) + 12/y = 1
联立方程组,解得 y = 15
29.下图显示的是2018年某产品在五个区域的经营状况,请问2017年哪个地区的产品产值最高?()
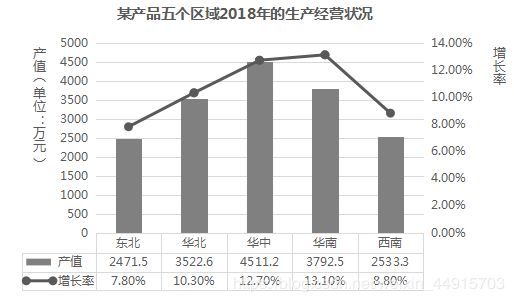
A. 东北
B. 华北
C. 华中
D. 华南
E. 西南
正确答案:C
?考点:增长率
题目解析:
倒推去年的产值,
例如,东北2017 = 2471.5 / 1.0780 = 2292.67,以此类推计算。
30. 下表为我国某产品2018下半年的进口额情况,请问6-12月当中,其中有几个月的增长率是超过了10%的?( )

A. 4
B. 3
C. 2
D. 1
官方答案:B
民间答案:A
?考点:增长率
6-7月份增长率 = 1551/1435 -1 = 0.0808
以此类推计算。
小结
做的第一份套题,几点感受:
(1)数据分析岗位的笔试内容还挺广泛的,远非统计学和机器学习,还有很多是自己不会的;
(2)一些接触过的知识却掌握不扎实;
(3)线上答题总是没选上答案,交卷前要检查。
Anyway,只管努力,大家一起加油吧。