【论文阅读笔记】YOLO v1——You Only Look Once: Unified, Real-Time Object Detection
You Only Look Once: Unified, Real-Time Object Detection
- (一)论文地址:
- (二)核心思想:
- (三)网络结构:
- (四)Unified Detection:
- (五)实验细节:
- 5.1 激活函数:
- 5.2 坐标归一化:
- 5.3 Loss 函数:
- 5.4 训练细节:
- (六)实验结果:
(一)论文地址:
https://arxiv.org/pdf/1506.02640.pdf
(二)核心思想:
YOLO v1 的提出基本是 one-stage 方法的里程碑,作者使用了全局全连接的方法,将目标检测问题重新定义成了一个回归问题,并使得每个预测框都具有全局信息,实现了真正端到端的训练;
并且实验结果也非常出色,不仅比 R-CNN 和 DPM 更快(45 FPS),而且准确率也有了很大的提升;而且一个更小的网络 Fast YOLO,在准确率不受很大影响的情况下,速度达到了 155 FPS;

(三)网络结构:

YOLO 的 backbone 依然采用了分类网络,但最后两层使用了全卷积层,最终输出一个 7×7×30 的特征层,其中每个点由于是全连接输出,都考虑了全局的特征信息;
(注意由于使用了全卷积,图像必须是统一448×448大小)
(四)Unified Detection:

这里是 YOLO 的点睛之笔;
YOLO 为了实现端到端(end-to-end)的训练,不再采用预选框(anchor 或者 default box),而是直接将图像划分成 S × S S×S S×S 个网格区域(文中 S = 7 S=7 S=7);
每个区域预测的值为:
- 该区域覆盖的相应物体的 B B B 个坐标框的 4 4 4 个值(文中 B = 2 ) B=2) B=2),分别为 { x , y , w , h } \lbrace x,y,w,h \rbrace {x,y,w,h},同时输出这 B B B 个预测框的置信度 p b p_b pb,选取置信度最高的那个预测框作为最终的结果;
- 该区域覆盖物体的分类置信度 C C C,其中在 VOC 数据集中 C C C 是长度为 20 20 20 的分类向量;
只有物体的真值框中心落入相应的区域,该区域才被标注为正样本,其置信度定义为:
![]()
即相应物体预测框与真值框的交并比(IOU);
因此每个区域生成 B × ( 4 + 1 ) + C = 30 B×(4+1)+C=30 B×(4+1)+C=30 个预测值,最后全连接层的输出大小为 S × S × 30 S×S×30 S×S×30;
这里使用 B B B 个预测 box 并生成置信度,是为了提高预测结果的容错率;增大 B B B 可以提高模型的鲁棒性,但相应的全连接层的计算复杂度也会大大提高;
(五)实验细节:
5.1 激活函数:
激活函数使用了 Leaky ReLU:
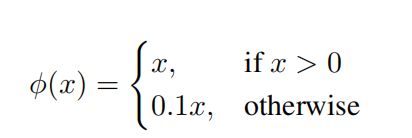
5.2 坐标归一化:
将预测的坐标值 { x p , y p , w p , h p } \lbrace x_p,y_p,w_p,h_p \rbrace {xp,yp,wp,hp} 归一化为:
x p = ( x − x b ) / L , y p = ( y − y b ) / L x_p=(x-x_b)/L,y_p=(y-y_b)/L xp=(x−xb)/L,yp=(y−yb)/L
w p = w / W , h p = h / W w_p=w/W,h_p=h/W wp=w/W,hp=h/W
其中:
- x , y , w , h x,y,w,h x,y,w,h 是真值框的坐标;
- x b , y b x_b,y_b xb,yb 为对应区域的中心坐标;
- W W W 是图像边长,文中 W = 448 W=448 W=448;
- L L L 为步长,即 L = W / S L=W/S L=W/S;
5.3 Loss 函数:
Loss 函数使用了均方差损失函数;
同时为了调节正负样本不均衡问题,引入了两个权重参数:
- λ c o o r d = 5 \lambda_{coord}=5 λcoord=5,表示正样本的坐标回归权重;
- λ n o o b j = 0.5 \lambda_{noobj}=0.5 λnoobj=0.5,表示负样本的置信度权重;
负样本的预测坐标和类别向量不参与训练;
最终 Loss 定义如下:

5.4 训练细节:
b a t c h s i z e = 64 batch_size=64 batchsize=64
m o m e n t u m = 0.9 momentum=0.9 momentum=0.9
w e i g h t weight weight d e c a y = 0.0005 decay=0.0005 decay=0.0005
l e a r n i n g learning learning r a t e rate rate 从 1 0 − 3 10^{-3} 10−3 先升到 1 0 − 2 10^{-2} 10−2 再降到 1 0 − 4 10^{-4} 10−4;
d r o p drop drop r a t e = 0.5 rate=0.5 rate=0.5
(六)实验结果:


(作者挑的图好奇怪,,,)