python爬虫进阶-突破字体反爬虫
目标:
爬取汽车之家论坛上的整篇文章,如下图所示:
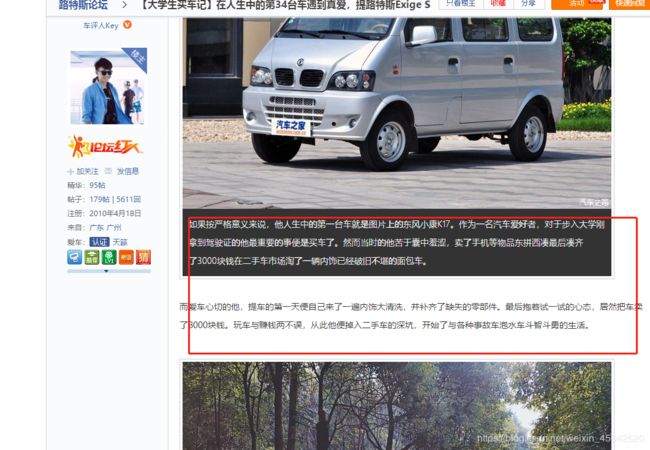
网址:https://club.autohome.com.cn/bbs/thread/1f05b4da4448439b/76044817-1.html#%23%23
问题描述:
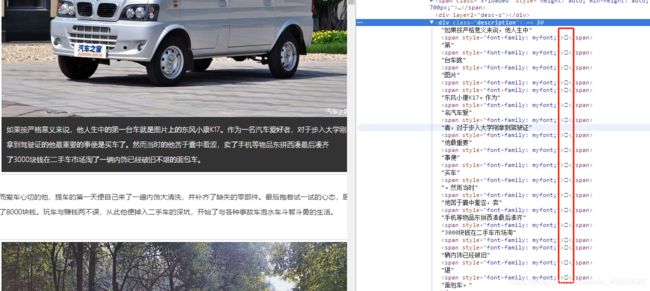
1)如下图所示,审查元素中一句话被拆分成好几段,而且个别文字被神秘符号代替了,比如【人生中的】的“的”,和【第一台】中的“一”,
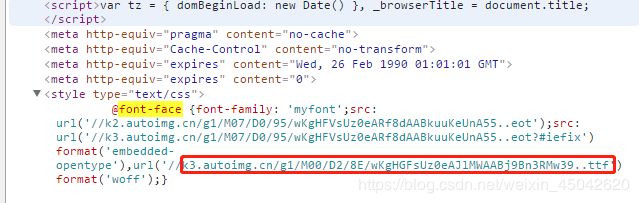
在审查元素中搜索“font-face”,“url”后面的内容,可以看到字体文件存放地址。
2)如下图,上文提到的被替换的字,在requests解析出来的文本中显示为【&#x????】的形式,如,等

准备工作
1)下载字体文件到本地
2)下载应用程序fontcreator
官网下载地址:https://www.high-logic.com/font-editor/fontcreator/download-confirmation
3)在fontcreator中打开字体文件
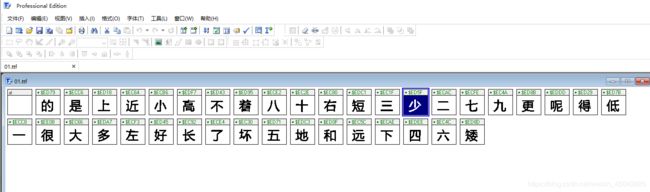
如果汉字的上方没有显示编码,对着任意汉字右击,设置标题为Macintosh映射
4)根据上图,为所有的汉字整理Macintosh映射(取后4位)
如下:

篇幅较大,此处只截取部分展示
爬虫实施
1)导入python包,发送请求
import re
import requests
from lxml import etree
url="https://club.autohome.com.cn/bbs/thread/1f05b4da4448439b/76044817-1.html#%23%23"
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0"}
r=requests.get(url,headers=headers)
2)特殊字符预处理
查看一下内容,可以发现&#x????的后四位是和mapping中的name是一致的
另外,文本中存在"br"标签和 (空白符)

使用正则表达式将上述特殊字符替换成空白
import re
content=re.sub('&#x','',r.text)
content=re.sub('
','',content)
content=re.sub(' ','',content)
为什么要做这一步,血淋淋的教训总结出来的,后面细说
3)定位到文章中的文字内容,这里使用xpath定位
html=etree.HTML(content)
html1=html.xpath('//div[@class="tz-figure"]//div[@class="description"]')
4)分别取出正常显示的文字和非正常显示的文字
part1,part2=[],[]
for i in html1:
part1.append(i.xpath('text()'))
part2.append(i.xpath('span/text()'))
打出来看看:
m=0
print(len(part1[m]))
print(part1[m])
print(len(part2[m]))
print(part2[m])

可以看到part1的长度比part2的长度大1(改变m的值查看其它情况)
5)将part2转换成汉字
for i in range(len(part2)):
for a in range(len(part2[i])):
for b in base_font.get('font'):
if b.get('name')==part2[i][a][:4]:
part2[i][a]=b.get('value')
break
重新运行一次上一步的代码,看一下数据:

可以看到part1和part2是错位对应的,part1的长度比part2的长度大1(改变m的值查看其它情况)
6)拼接part1和part2
按照a1,b1,a2,b2,…a(n-1),b(n-1),an的顺序拼接
result=[]
for m in range(len(part1)):
all=''
for i in range(len(part1[m])-1):
try:
all+=(part1[m][i]+part2[m][i])
except:
print(m,i)
all+=part1[m][-1]
result.append(all)
7)文本输出
result="".join(result)
with open('E:/data/汽车之家文章/1.txt', 'w') as f:
f.write(result)
结束
附完整代码:
import requests
import re
from lxml import etree
base_font={
"font":[{"name":"ed79","value":"的"},
{"name":"ecb6","value":"小"},
{"name":"ed45","value":"好"},
{"name":"ec66","value":"大"},
{"name":"ece4","value":"了"},
{"name":"ecac","value":"二"},
{"name":"ecc6","value":"是"},
{"name":"ed18","value":"上"},
{"name":"ec64","value":"近"},
{"name":"edf7","value":"高"},
{"name":"ed43","value":"不"},
{"name":"ed95","value":"着"},
{"name":"ece2","value":"八"},
{"name":"ec2e","value":"十"},
{"name":"ec80","value":"右"},
{"name":"edc1","value":"短"},
{"name":"ec1f","value":"三"},
{"name":"ed5f","value":"少"},
{"name":"ecfe","value":"七"},
{"name":"ec4a","value":"九"},
{"name":"ed8b","value":"更"},
{"name":"eddd","value":"呢"},
{"name":"ed29","value":"得"},
{"name":"ed79","value":"低"},
{"name":"ecc8","value":"一"},
{"name":"ee08","value":"很"},
{"name":"ec66","value":"大"},
{"name":"eda7","value":"多"},
{"name":"ecf3","value":"左"},
{"name":"ec92","value":"长"},
{"name":"ece4","value":"了"},
{"name":"ec30","value":"坏"},
{"name":"ed71","value":"五"},
{"name":"edc3","value":"地"},
{"name":"ed0f","value":"和"},
{"name":"ecac","value":"下"},
{"name":"edee","value":"四"},
{"name":"ec4c","value":"六"},
{"name":"ed8d","value":"矮"}]}
url="https://club.autohome.com.cn/bbs/thread/1f05b4da4448439b/76044817-1.html#%23%23"
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0"}
r=requests.get(url,headers=headers)
content=re.sub('&#x','',r.text)
content=re.sub('
','',content)
content=re.sub(' ','',content)
html=etree.HTML(content)
html1=html.xpath('//div[@class="tz-figure"]//div[@class="description"]')
part1,part2=[],[]
for i in html1:
part1.append(i.xpath('text()'))
part2.append(i.xpath('span/text()'))
for i in range(len(part2)):
for a in range(len(part2[i])):
for b in base_font.get('font'):
if b.get('name')==part2[i][a][:4]:
part2[i][a]=b.get('value')
break
result=[]
for m in range(len(part1)):
all=''
for i in range(len(part1[m])-1):
try:
all+=(part1[m][i]+part2[m][i])
except:
print(m,i)
all+=part1[m][-1]
result.append(all)
result="".join(result)
with open('E:/data/汽车之家文章/1.txt', 'w') as f:
f.write(result)