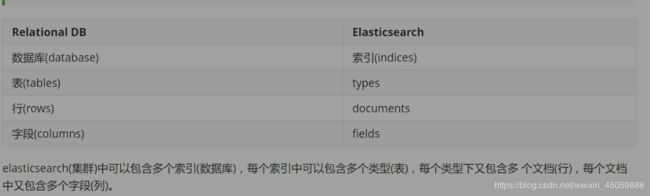
es的一些基本操作
一些es的基本操作
es搜索的时候会有几种规则,会决定把关键词是否进行拆解开来当成多个关键词。
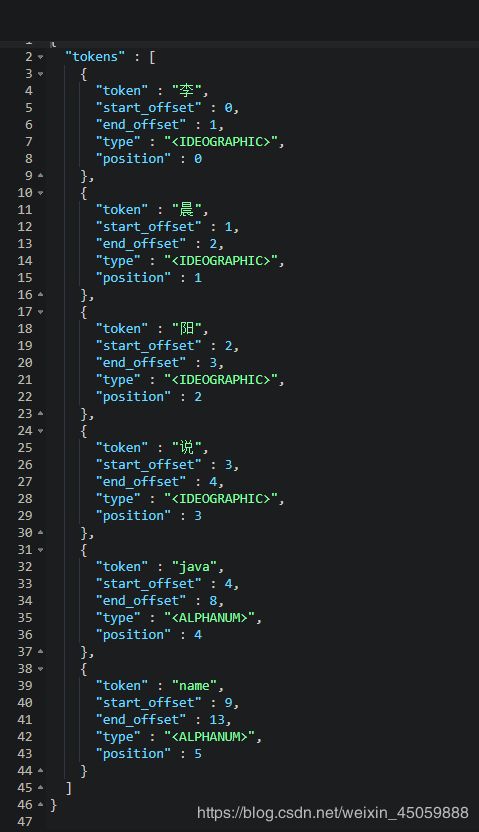
#分词器的使用(标准)
GET _analyze
{
"analyzer": "standard",
"text": "李晨阳说java name"
}
结果就是如下
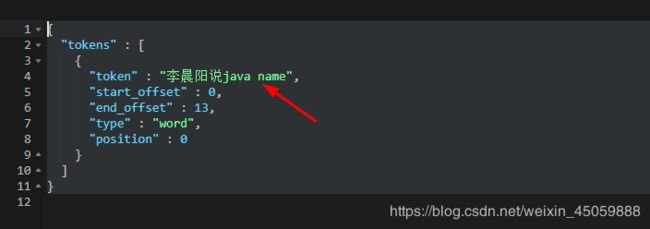
#分词器的使用(keyword当成关键词没有被分析)
GET _analyze
{
"analyzer": "keyword",
"text": "李晨阳说java name"
}
结果就是如下
单纯创建一个索引(相当于数据库的一个库),属性为name,age,birth
#创建一个文档,索引是test2,设置了一下类型
PUT /test2
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"age":{
"type": "long"
},
"birth":{
"type": "date"
}
}
}
}
创建一个索引并写入一条数据(user相当于表名,主键为2的一条数据)
#创建一个文档名字为2,索引是lcy,类型是user,索引差不多相当于数据库的一个库,文档相当于一条数据,类型相当于是一张表(不过8.0以后就会过时不用,可以用_doc替代)
PUT /lcy/user/2
{
"name": "张三",
"age": 66,
"desc": "信息",
"tags": ["挣钱","挣钱","养家"]
}
获取一条数据
#获取test3这个文档的信息
GET test1/type1/1
修改一条文档(数据)
#_update意思是更新一个文档,要用到post命令(也可以使用put更新,但是当put命令相当于自动覆盖,一旦少写了属性,则少写的属性将丢失,推荐使用post+_update)
POST test1/_doc/1/_update
{
"doc":{
"name": "李晨阳真帅"
}
}
删除一条文档(数据)
DELETE /lcy/user/3_update
搜索
#匹配式搜索,右边如果查出来数据,则hits就是索引和文档的信息,total就是总共条数,score是权重比例,下面的"_source"可以加也可以不加,加了就代表查询指定的字段信息,权重越高越能查出来,"sort"代表排序功能,"from"和"size"代表分页,相当于mysql数据库中的limit,这里表示从0查,查1个,根据"order"指定降序还是升序,在javaApi中可以便利hits获取数据
GET lcy/user/_search
{
"query": {
"match": {
"name": "张"
}
},
"_source": ["age","name"],
"sort": [
{
"age": {
"order": "desc"
}
}
],
"from": 0,
"size": 2
}
第二种搜索(bool)
# bool类型(条件查询,比如or,and)查询,must相当于mysql的and连接语句,需要匹配条件全部能匹配的上才显示出数据
GET lcy/user/_search
{
"query": {
"bool": {
"must": [
{"match": {
"name": "张"
}},
{"match": {
"age": 66
}}
]
}
}
}
第2种搜索(bool)
# bool类型查询,should相当于mysql的or连接语句,两个match有一个符合就返回数据,此次结果和上图一样
GET lcy/user/_search
{
"query": {
"bool": {
"should": [
{"match": {
"age": 454
}},
{"match": {
"name": "张"
}}
]
}
}
}
第2种搜索(bool)
# bool类型查询,must_not意思是查找不符合当前match值的数据
# filter意思是过滤,range意思是区间,gt是>,gte是>=,lt是<,lte是<=
GET lcy/user/_search
{
"query": {
"bool": {
"must_not": [
{"match": {
"name": "22"
}}
],
"filter": {
"range": {
"age": {
"lte": 22
}
}
}
}
}
}
第3种搜索(term)
#term(精确查询)中只有value完全匹配的数据,才会显示出来,差错一个数据都无法显示
GET /testdb/_search
{
"query": {
"bool": {
"should": [
{"term": {
"name": {
"value": "李晨阳说java name"
}
}},
{ "term": {
"desc": {
"value": "描述java"
}
}}
]
}
}
}
高亮显示
#关键词高亮,pre_tags和post_tags代表格式的前后缀,highlight的fields的name属性是要高亮的属性
GET /testdb/_search
{
"query": {
"match": {
"name": "李晨阳"
}
},
"highlight": {
"pre_tags": ""
,
"post_tags": "",
"fields": {
"name": {}
}
}
}