Python学习:Python分析中国人口(一)爬取数据
爬取数据
关于我国人口的数据来源,可以从“国家数据”网站中获取。这是一个由国家统计局提供的网站,里面有很多国家公开的数据信息。

1、请求单页数据
在国家数据网站中,有从新中国成立到2018年的人口数据。
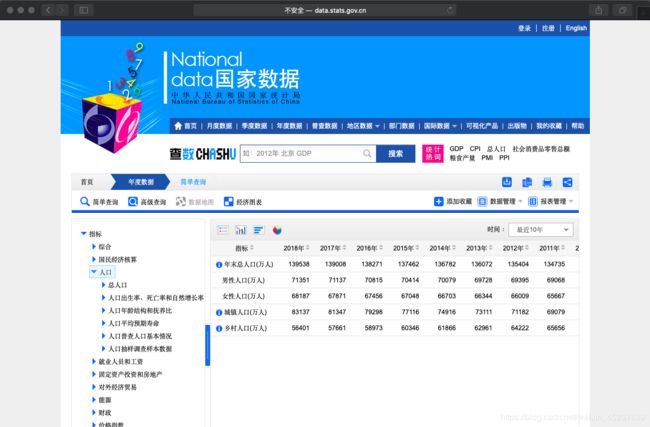
在人口数据中,有三项是我们需要的数据:总人口、增长率、人口结构。
我们按F12查看一下请求的链接,然后复制链接使用requests请求数据。
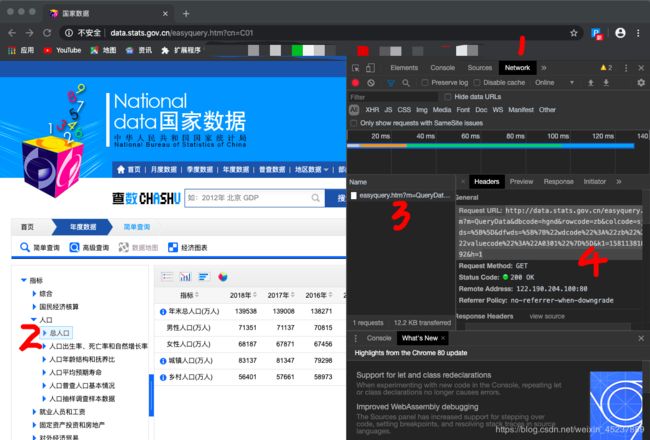
只使用一个简单的get请求,就把数据获取了。而且返回的是json数据!
import requests
def spider_population():
url = 'http://data.stats.gov.cn/easyquery.htm?m=QueryData&dbcode=hgnd&rowcode=zb&colcode=sj&wds=%5B%5D&dfwds=%5B%7B%22wdcode%22%3A%22zb%22%2C%22valuecode%22%3A%22A0301%22%7D%5D&k1=1581138105792&h=1'
response = requests.get(url)
print(response.json())
if __name__ == '__main__':
spider_population()
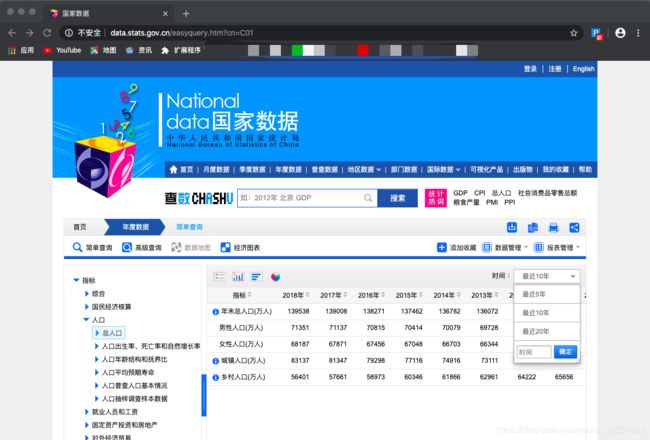
2、分页数据
我们此次的目的是抓取从新中国至今的所有人口数据,而页面中最多可以获取近20年的数据,所以我们需要分析网页请求中关于分页的参数。
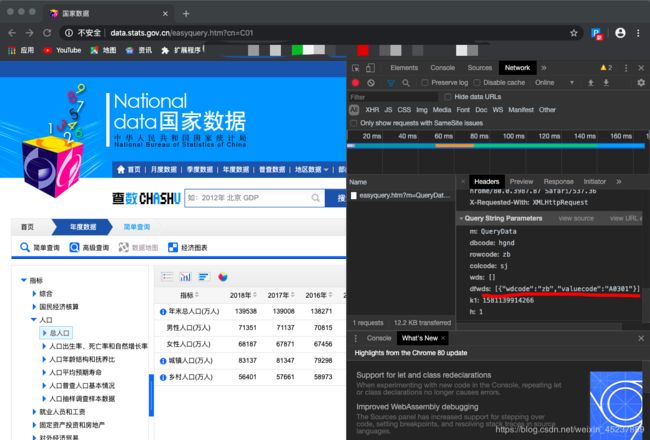
分析请求参数时发现主要有两个参数:zb、sj,分别表示指标和时间。
(一)
zb:指标
A0301:后面的数字表示第几项(可以推出A0302则表示“人口出生率、死亡率和自然增长率”
(二)
sj:时间
LAST:表示近10年,后面的数字表示年数
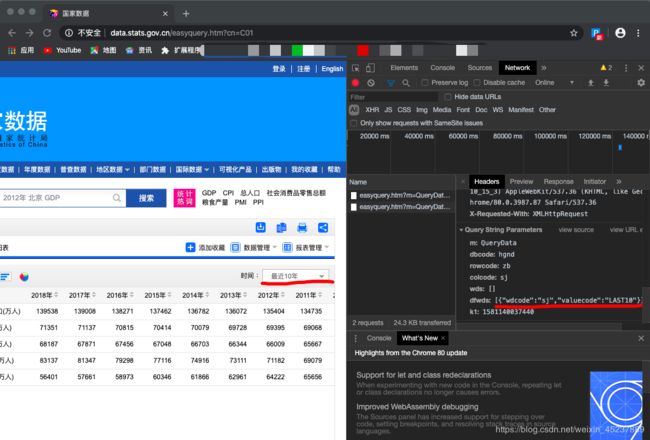
猜想:LAST70是不是就可以获取70年的数据呢?
import requests
def spider_last70_population():
"""
爬取近70年人口数据
"""
# 请求参数 sj(时间),zb(指标)
# LAST70 表示 近70年
# A0301 表示总人口
dfwds = '[{"wdcode": "sj", "valuecode": "LAST70"}, {"wdcode":"zb","valuecode":"A0301"}]'
url = 'http://data.stats.gov.cn/easyquery.htm?m=QueryData&dbcode=hgnd&rowcode=sj&colcode=zb&wds=[]&dfwds={}'
response = requests.get(url.format(dfwds))
print(response.json())
if __name__ == '__main__':
spider_last70_population()
输出结果:

然后我们再将zb参数更换,获取到所有的数据!
def spider_all_population():
"""
爬取人口数据
"""
# 请求参数 sj(时间),zb(指标)
# 总人口
dfwds1 = '[{"wdcode": "sj", "valuecode": "LAST70"}, {"wdcode":"zb","valuecode":"A0301"}]'
dfwds2 = '[{"wdcode": "sj", "valuecode": "LAST70"}, {"wdcode":"zb","valuecode":"A0302"}]'
dfwds3 = '[{"wdcode": "sj", "valuecode": "LAST70"}, {"wdcode":"zb","valuecode":"A0303"}]'
url = 'http://data.stats.gov.cn/easyquery.htm?m=QueryData&dbcode=hgnd&rowcode=sj&colcode=zb&wds=[]&dfwds={}'
response1 = requests.get(url.format(dfwds1))
response1 = requests.get(url.format(dfwds1))
response1 = requests.get(url.format(dfwds1))
3、2019年数据
目前数据唯一不完整的就是没有2019年的数据。通过2020年1月17日,国家统计局发布了2019年国民经济报告中关于人口的数据得出了2019年的相关数据。
# 将所有数据放这里,年份为key,值为各个指标值组成的list
# 因为2019年数据还没有列入到年度数据表里,所以根据统计局2019年经济报告中给出的人口数据计算得出
# 数据顺序为历年顺序
population_dict = {
'2019': [2019, 140005, 71527, 68478, 84843, 55162, 10.48, 7.14, 3.34, 140005, 25061, 97341, 17603, 43.82942439,
25.74557483, 18.08384956]}
4、保存Excel
获取到数据之后,我们先将数据清洗,提取出我们需要的数据,然后整理保存到Excel中,数据处理方面我们仍然使用pandas。
附上完整代码:
import requests
import pandas as pd
# 人口数量excel文件保存路径
POPULATION_EXCEL_PATH = 'population.xlsx'
def spider_all_population():
"""
爬取人口数据
"""
# 请求参数 sj(时间),zb(指标)
# 总人口
dfwds1 = '[{"wdcode": "sj", "valuecode": "LAST70"}, {"wdcode":"zb","valuecode":"A0301"}]'
# 增长率
dfwds2 = '[{"wdcode": "sj", "valuecode": "LAST70"}, {"wdcode":"zb","valuecode":"A0302"}]'
# 人口结构
dfwds3 = '[{"wdcode": "sj", "valuecode": "LAST70"}, {"wdcode":"zb","valuecode":"A0303"}]'
url = 'http://data.stats.gov.cn/easyquery.htm?m=QueryData&dbcode=hgnd&rowcode=sj&colcode=zb&wds=[]&dfwds={}'
# 将所有数据放这里,年份为key,值为各个指标值组成的list
# 因为2019年数据还没有列入到年度数据表里,所以根据统计局2019年经济报告中给出的人口数据计算得出
# 数据顺序为历年顺序
population_dict = {
'2019': [2019, 140005, 71527, 68478, 84843, 55162, 10.48, 7.14, 3.34, 140005, 25061, 97341, 17603, 43.82942439,
25.74557483, 18.08384956]}
response1 = requests.get(url.format(dfwds1))
get_population_info(population_dict, response1.json())
response2 = requests.get(url.format(dfwds1))
get_population_info(population_dict, response2.json())
response3 = requests.get(url.format(dfwds1))
get_population_info(population_dict, response3.json())
save_excel(population_dict)
return population_dict
def get_population_info(population_dict, json_obj):
"""
提取人口数量信息
"""
datanodes = json_obj['returndata']['datanodes']
for node in datanodes:
# 获取年份
year = node['code'][-4:]
# 数据数值
data = node['data']['data']
if year in population_dict.keys():
population_dict[year].append(data)
else:
population_dict[year] = [int(year), data]
return population_dict
def save_excel(population_dict):
"""
人口数据生成excel文件
:param population_dict: 人口数据
:return:
"""
# .T 是行列转换
df = pd.DataFrame(population_dict).T[::-1]
df.columns = ['年份', '年末总人口(万人)', '男性人口(万人)', '女性人口(万人)', '城镇人口(万人)', '乡村人口(万人)', '人口出生率(‰)', '人口死亡率(‰)',
'人口自然增长率(‰)', '年末总人口(万人)', '0-14岁人口(万人)', '15-64岁人口(万人)', '65岁及以上人口(万人)', '总抚养比(%)',
'少儿抚养比(%)', '老年抚养比(%)']
writer = pd.ExcelWriter(POPULATION_EXCEL_PATH)
# columns参数用于指定生成的excel中列的顺序
df.to_excel(excel_writer=writer, index=False,
encoding='utf-8', sheet_name='中国70年人口数据')
writer.save()
writer.close()
if __name__ == '__main__':
result_dict = spider_all_population()
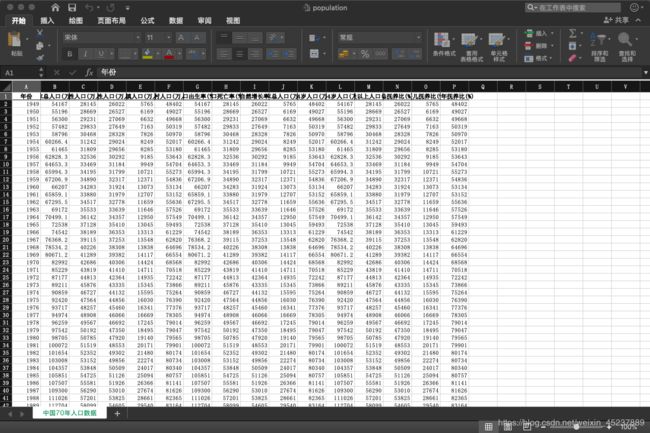
查看excel保存的数据:
学习参考公众号:裸睡的猪