MP笔记
使用MP的前期工作:
- 建库建表
- 在IDE中新建Maven Project
- 在POM文件中引入依赖


4.右键Maven项目,选择Maven,Update Project
5.在src/main/resorces文件夹下,新建application.yml配置文件
6.在application.yml中配置信息

7.在src/main/java文件夹下,新建Spring boot 启动类。

8.新建实体类,和表结构相同。加上@Data就免去了GetSetter方法。(需要lowbok依赖)
9.新建mapper接口,继承BaseMapper,泛型是要操作的实体类,而且还要在Spring boot启动类上加上@MapperScan(“所在的包”)
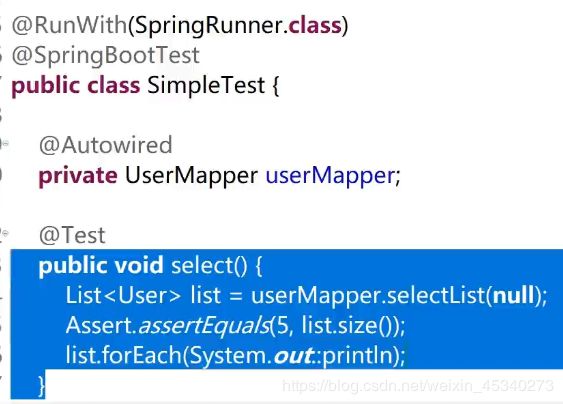
10.在src/test/java新建测试类。加上注解:@Springboottest 表示这是一个测试类。@RunWith(SpringRuner.class)表示可以在springboot环境下运行Junit测试。
常用注解
1.数据库表名和实体类类名不一致时,在实体类上加上注解@TableName(“新的数据库表名”),就可以重新映射。
2.MP默认主键的标识符为id,如果不是id,可以用@TableId映射。
3.数据库字段名和实体类属性名不一致时,可以在实体类属性上加上注解@TableFieId(“数据库表名”),应用于非主键。
4.当实体类属性在数据库表上没有对应的字段时,这时进行CRUD操作就会报错,只需要为这个属性加上关键字Transient,****不参与序列化,就可以解决这个问题。但是属性必须参与系列化的时候,就用static这个关键字。如果static仍然不满足需求,可以删除static,加上注解@TableFieId(exist = false)
查询
单个id查询:
批量id查询:
map查询:

columnMap.put()是设置条件。需要注意的是“name”和“age”是数据库字段名,不是实体类属性名。
条件构造器查询

方法里面的第一行代码和注释是一样的作用。
例子2:

.and().between()这样调用默认为and
例子3:

注意:例子2中名字包含雨字和例子3王姓(名字开头为王字)的写法。
例子4:
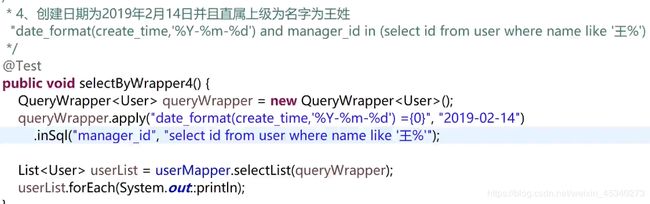
在条件构造器中使用子查询。
例子5:

用到了lambda表达式。
例子6:

注意:这里的写法和例子2不同,
区别:例子2是大于等于20小于等于40.【20,40】是闭区间。
例子6:是大于20小于40 (20,40)是开区间。 包含等于的用between
例子7:

括号的优先级比and高。
例子8: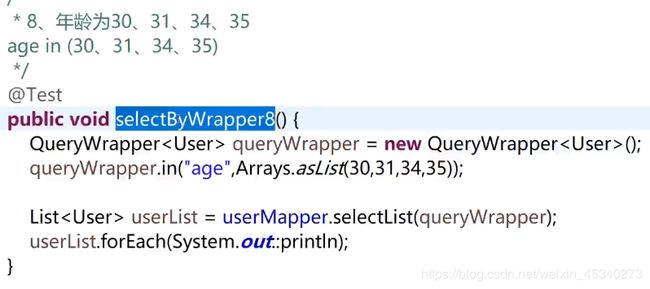
年龄在固定某个值,而不是范围的写法。
例子9:

限制返回结果。有风险。
只查询想要的字段

只需要名字和年龄,.select(“age”,“name”)就行了。
例子2:
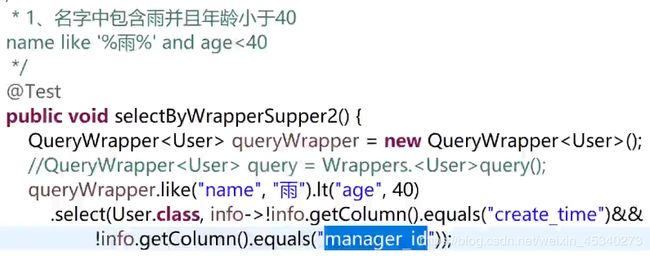
除了“create_time”和“manager_id”这两个字段不要,其他字段全部查询出来。
这个例子的应用场景是:想要查询的字段非常多,一个个加进去select非常麻烦,用上面的写法就可以排除掉不想要的字段,实现反选操作。
condition用法:

like第一个参数就是condition,如果name不等于null且不等于"",则为true,查询条件即为name;
email同理,如果两者都是true,则按照and查询。
实体类作为条件构造器的参数

这种写法默认为and
如果条件不是“刘红雨”这个固定值,而是跟“刘红雨”相似的姓名,还可以这么做:
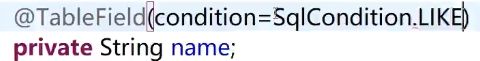
年龄也可以这么操作:

参数值用法进源码看。
ALLeq用法

如果值是null的话,传的值也是null
执行的sql :where age is null
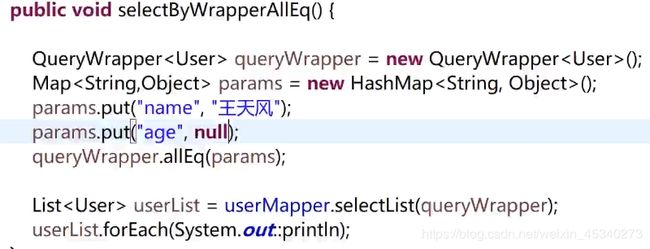
如果你不希望值为null的字段作为条件的话:

allEq的第二个参数设为false,就会忽略掉值为null的字段。
其他方法

不需要的字段不会返回,这种写法比较整齐美观,

返回符合条件的数据的数量:

返回符合条件的实体类对象:
注意只能返回一个对象,多了会报错。

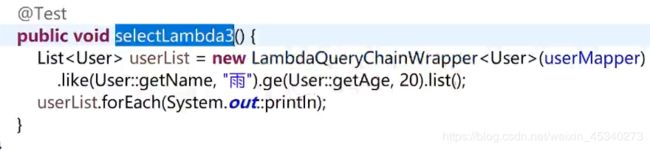
lambda条件构造器

方法前三行都是创建lambda,效果一样。
这样做的好处**:如果将getName改为getMame,在实体类中找不到对应的属性,就会报错。防止了拼写错误。**
![]()
更复杂的例子:

简洁的写法:
自定义sql
注解sql:
在mapper接口上,写一个抽象方法,并在上方用注解的方式写sql:

然后调用自定义sql:

xmlsql:
在application.yml上配置xmlmapper的路径:

在对应路径新建包和xml文件:
namespace:mapper的全路径,包名+类名,id是方法名,resultType:返回类型

分页查询
建配置类:

写方法:

new Page(1,2)表示当前第一页,每页最多两条记录;
用map装载返回结果:

更新
根据id更新:

根据姓名和年龄更改信息:
先找到这个人再改信息;

简洁写法:应用于更改的字段少的情况

lambda写法:

lambda链式写法:

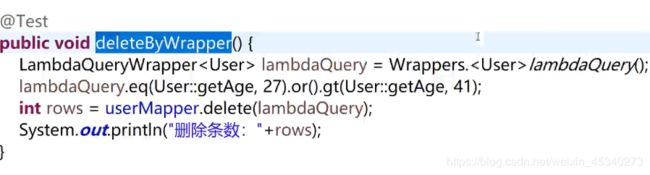
删除
根据id删除:

map删除:

批量id删除:

lambda删除:
AR模式
AR模式:通过实体类对象,直接对表进行crud操作。
1.实体类继承Model<实体类名>,报警告加上第二行注解。

还需要新增属性:
![]()
2.mapper必须继承basemapper

例子:

例子2:
如果id存在,则更新,不存在插入。

删除用法类似,但需要注意的是,删除不存在的用户会显示成功。
主键策略
主键自增:插入数据时,不填写主键,主键在数据库中自动递增1;需要在数据库中把主键设置为自增。

默认策略:

UUID策略:要求主键类型是String,对应数据库varchar;
