PaddleX助力无人驾驶:基于YOLOv3的车辆检测和车道线分割实战

【飞桨开发者说】梁瑛平,北京理工大学徐特立学院本科二年级,人工智能开发爱好者。

项目简介
无人驾驶汽车利用传感器技术、信号处理技术、通讯技术和计算机技术等,通过集成视觉、激光雷达、超声传感器、微波雷达、GPS、里程计、磁罗盘等多种车载传感器来辨识汽车所处的环境和状态,并根据所获得的道路信息、交通信号的信息、车辆位置和障碍物信息做出分析和判断,向主控计算机发出期望控制,控制车辆转向和速度,从而实现无人驾驶车辆依据自身意图和环境的拟人驾驶。
该项目使用PaddleX提供的YOLOv3模型,在 UA-DETRAC 车辆检测数据集进行训练;
训练结果能够检测到car,van,bus等不同类型车辆,mAP为0.73;
并使用开源车道检测算法,实现了无人驾驶部分的视觉感知——车辆检测和车道线分割;
最终效果

PaddleX工具简介
PaddleX是飞桨全流程开发工具,集飞桨核心框架、模型库、工具及组件等深度学习开发所需全部能力于一身,打通深度学习开发全流程,并提供简明易懂的Python API,方便用户根据实际生产需求进行直接调用或二次开发,为开发者提供飞桨全流程开发的最佳实践。目前,该工具代码已开源于GitHub,同时可访问PaddleX在线使用文档,快速查阅使用教程和API文档说明。
PaddleX代码GitHub链接:
https://github.com/PaddlePaddle/PaddleX
PaddleX文档链接:
https://paddlex.readthedocs.io/zh_CN/latest/index.html
PaddleX官网链接:
https://www.paddlepaddle.org.cn/paddle/paddlex
项目过程回放
一、准备PaddleX环境
1. 安装PaddleX库
pip install paddlex -i https://mirror.baidu.com/pypi/simple
2. 设置工作路径,并使用0号GPU卡
import matplotlib
matplotlib.use('Agg') import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
import paddlex as pdx
os.chdir('/home/aistudio/work/')
二、准备数据
1. 数据集简介
数据集使用 UA-DETRAC 数据集,是一个具有挑战性的真实多目标检测和多目标跟踪基准。该数据集由10小时的视频组成,这些视频由中国北京和天津的24个不同地点使用Cannon EOS 550D摄像机拍摄。视频以每秒 25 帧 (fps) 的速度录制,分辨率为 960×540 像素。UA-DETRAC 数据集中有超过 140 000 个帧,手动标注了 8250 辆车,总共有 121 万个标记了边界框的目标。

2. 准备所需文件
PaddleX同时支持VOC和COCO两种格式的数据,需要的文件有:
labels.txt:保存目标类别的文件,不包括背景类;

train_list.txt和val_list.txt:保存训练/测试所需的图片和标注文件的相对路径;
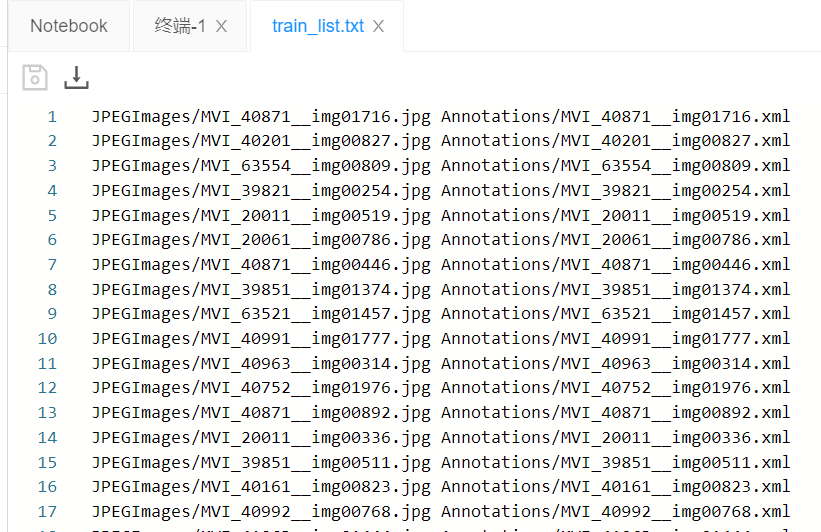
!unzip /home/aistudio/data/data34332/VOC2012.zip -d ./
imgs = os.listdir('./VOC2012/JPEGImages')
print('total:', len(imgs))
with open('./VOC2012/train_list.txt', 'w') as f:
for im in imgs[:-200]:
info = 'JPEGImages/'+im+' '
info += 'Annotations/'+im[:-4]+'.xml\n'
f.write(info)
with open('./VOC2012/val_list.txt', 'w') as f:
for im in imgs[-200:]:
info = 'JPEGImages/'+im+' '
info += 'Annotations/'+im[:-4]+'.xml\n'
f.write(info)
三、数据预处理
1. 设置图像数据预处理和数据增强模块
具体参数见:
https://paddlex.readthedocs.io/zh_CN/latest/apis/transforms/det_transforms.html
from paddlex.det import transforms
train_transforms = transforms.Compose([
transforms.MixupImage(mixup_epoch=250),
transforms.RandomDistort(),
transforms.RandomExpand(),
transforms.RandomCrop(),
transforms.Resize(target_size=608, interp='RANDOM'),
transforms.RandomHorizontalFlip(),
transforms.Normalize(),
])
eval_transforms = transforms.Compose([
transforms.Resize(target_size=608, interp='CUBIC'),
transforms.Normalize(),
])
2. 定义数据迭代器
训练集总共有6000张图片,我们选取5800训练,剩余200张进行测试。
base = './VOC2012/'
train_dataset = pdx.datasets.VOCDetection(
data_dir=base,
file_list=base+'train_list.txt',
label_list=base+'labels.txt',
transforms=train_transforms,
shuffle=True)
eval_dataset = pdx.datasets.VOCDetection(
data_dir=base,
file_list=base+'val_list.txt',
label_list=base+'labels.txt',
transforms=eval_transforms)
2020-05-11 07:57:15 [INFO] Starting to read file list from dataset...2020-05-11 07:57:16 [INFO] 5800 samples in file ./VOC2012/train_list.txt
creating index...index created!2020-05-11 07:57:17 [INFO] Starting to read file list from dataset...2020-05-11 07:57:17 [INFO] 200 samples in file ./VOC2012/val_list.txt
creating index...index created!
参数说明:
data_dir (str): 数据集所在的目录路径。
file_list (str): 描述数据集图片文件和对应标注文件的文件路径(文本内每行路径为相对data_dir的相对路径)。
label_list (str): 描述数据集包含的类别信息文件路径。
transforms (paddlex.det.transforms): 数据集中每个样本的预处理/增强算子,详见paddlex.det.transforms。
num_workers (int|str):数据集中样本在预处理过程中的线程或进程数。默认为’auto’。当设为’auto’时,根据系统的实际CPU核数设置num_workers: 如果CPU核数的一半大于8,则num_workers为8,否则为CPU核数的一半。
buffer_size (int): 数据集中样本在预处理过程中队列的缓存长度,以样本数为单位。默认为100。
parallel_method (str): 数据集中样本在预处理过程中并行处理的方式,支持’thread’线程和’process’进程两种方式。默认为’thread’(Windows和Mac下会强制使用thread,该参数无效)。
shuffle (bool): 是否需要对数据集中样本打乱顺序。默认为False。
四、定义YOLOv3模型并开始训练
1. YOLOv3简介:
论文地址:
https://arxiv.org/abs/1804.02767
‘Sometimes you just kinda phone it in for a year, you know?’
作者说他一年大部分时间去刷 Twitter 了,然后玩了(play around)一阵子 GAN,正好剩下一点时间,就改进了一下 YOLO 算法,提出了 YOLO v3。YOLOv3添加了ResNet中提出的残差结果和FPN中提出的通过上采样得到的特征金字塔结果。它最显着特征是它可以三种不同的比例进行检测,最终输出是通过在特征图上应用1 x 1内核生成的。在YOLO v3中,通过在网络中三个不同位置的三个不同大小的特征图上使用1 x 1大小的卷积来完成检测。
num_classes = len(train_dataset.labels)
print('class num:', num_classes)
model = pdx.det.YOLOv3(num_classes=num_classes, backbone='DarkNet53')
model.train(
num_epochs=4,
train_dataset=train_dataset,
train_batch_size=4,
eval_dataset=eval_dataset,
learning_rate=0.000125,
lr_decay_epochs=[400, 800],
save_interval_epochs=2,
log_interval_steps=200,
save_dir='./yolov3_darknet53',
use_vdl=True)
class num: 4
2020-05-11 08:15:15 [INFO] Load pretrain weights from ./yolov3_darknet53/pretrain/DarkNet53.2020-05-11 08:15:16 [INFO] There are 260 varaibles in ./yolov3_darknet53/pretrain/DarkNet53 are loaded.
参数说明:
num_classes (int): 类别数。默认为80。
backbone (str): YOLOv3的backbone网络,取值范围为[‘DarkNet53’, ‘ResNet34’, ‘MobileNetV1’, ‘MobileNetV3_large’]。默认为’MobileNetV1’。
anchors (list|tuple): anchor框的宽度和高度,为None时表示使用默认值 [[10, 13], [16, 30], [33, 23], [30, 61], [62, 45], [59, 119], [116, 90], [156, 198], [373, 326]]。
anchor_masks (list|tuple): 在计算YOLOv3损失时,使用anchor的mask索引,为None时表示使用默认值 [[6, 7, 8], [3, 4, 5], [0, 1, 2]]。
ignore_threshold (float): 在计算YOLOv3损失时,IoU大于ignore_threshold的预测框的置信度被忽略。默认为0.7。
nms_score_threshold (float): 检测框的置信度得分阈值,置信度得分低于阈值的框应该被忽略。默认为0.01。
nms_topk (int): 进行NMS时,根据置信度保留的最大检测框数。默认为1000。
nms_keep_topk (int): 进行NMS后,每个图像要保留的总检测框数。默认为100。
nms_iou_threshold (float): 进行NMS时,用于剔除检测框IOU的阈值。默认为0.45。
label_smooth (bool): 是否使用label smooth。默认值为False。
train_random_shapes (list|tuple): 训练时从列表中随机选择图像大小。默认值为[320, 352, 384, 416, 448, 480, 512, 544, 576, 608]。
五、评估模型
使用 evaluate 方法进行模型评估,最终mAP为0.73左右。

六、加载模型用于测试
image_name = './test6.jpg'
result = model.predict(image_name)
pdx.det.visualize(image_name, result, threshold=0.5, save_dir='./output/')
检测结果:

七、定义车道线检测模型
这里使用了开源的项目:
https://github.com/Sharpiless/advanced_lane_detection
该车道检测算法流程为:
(1)给定一组棋盘图像(在camera_cal文件夹内),计算相机校准矩阵和失真系数。

(2)根据校准矩阵和失真系数对原始图像应用失真校正。

(3)使用颜色变换,渐变等创建阈值二进制图像。

(4)应用透视变换以校正二进制图像(“鸟瞰”)。

(5)检测图像中车道像素并拟合,以找到车道边界。

(6)将检测到的车道边界矫正到原始图像。

具体实现如下:
import numpy as np
import cv2, pickle, glob, os
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
import tools
from moviepy.editor import VideoFileClip
from IPython.display import HTML
# code adopted from: https://github.com/t-lanigan/vehicle-detection-and-tracking/blob/master/road_sensor.py
class GlobalObjects:
def __init__(self):
self.__set_folders()
self.__set_hyper_parameters()
self.__set_perspective()
self.__set_kernels()
self.__set_mask_regions()
def __set_folders(self):
# Use one slash for paths.
self.camera_cal_folder = 'camera_cal/'
self.test_images = glob.glob('test_images/*.jpg')
self.output_image_path = 'output_images/test_'
self.output_movie_path = 'output_movies/done_'
def __set_hyper_parameters(self):
self.img_size = (1280, 720) # (x,y) values for img size (cv2 uses this)
self.img_shape = (self.img_size[1], self.img_size[0]) # (y,x) As numpy spits out
return
def __set_kernels(self):
"""Kernels used for image processing"""
self.clahe = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(8,8))
def __set_perspective(self):
"""The src points draw a persepective trapezoid, the dst points draw
them as a square. M transforms x,y from trapezoid to square for
a birds-eye view. M_inv does the inverse.
"""
src = np.float32([[(.42 * self.img_shape[1],.65 * self.img_shape[0] ),
(.58 * self.img_shape[1], .65 * self.img_shape[0]),
(0 * self.img_shape[1],self.img_shape[0]),
(1 * self.img_shape[1], self.img_shape[0])]])
dst = np.float32([[0,0],
[self.img_shape[1],0],
[0,self.img_shape[0]],
[self.img_shape[1],self.img_shape[0]]])
self.M = cv2.getPerspectiveTransform(src, dst)
self.M_inv = cv2.getPerspectiveTransform(dst, src)
def __set_mask_regions(self):
"""These are verticies used for clipping the image.
"""
self.bottom_clip = np.int32(np.int32([[[60,0], [1179,0], [1179,650], [60,650]]]))
self.roi_clip = np.int32(np.int32([[[640, 425], [1179,550], [979,719],
[299,719], [100, 550], [640, 425]]]))
class LaneFinder(object):
"""
The mighty LaneFinder takes in a video from the front camera of a self driving car
and produces a new video with the traffic lanes highlighted and statistics about where
the car is relative to the center of the lane shown.
"""
def __init__(self):
self.g = GlobalObjects()
self.thresholder = tools.ImageThresholder()
self.distCorrector = tools.DistortionCorrector(self.g.camera_cal_folder)
self.histFitter = tools.HistogramLineFitter()
self.laneDrawer = tools.LaneDrawer()
self.leftLane = tools.Line()
self.rightLane = tools.Line()
return
def __image_pipeline(self, img):
"""The pipeline for processing images. Globals g are added to functions that need
access to global variables.
"""
resized = self.__resize_image(img)
undistorted = self.__correct_distortion(resized)
warped = self.__warp_image_to_biv(undistorted)
thresholded = self.__threshold_image(warped)
lines = self.__get_lane_lines(thresholded)
result = self.__draw_lane_lines(undistorted, thresholded, include_stats=False)
return result
def __draw_lane_lines(self, undistorted, thresholded, include_stats):
lines = {'left_line': self.leftLane,
'right_line': self.rightLane }
return self.laneDrawer.draw_lanes(undistorted,
thresholded,
lines,
self.g.M_inv,
include_stats)
def __get_lane_lines(self, img):
self.leftLane = self.histFitter.get_line(img, self.leftLane, 'left')
self.rightLane = self.histFitter.get_line(img, self.rightLane, 'right')
return True
def __mask_region(self, img, vertices):
"""
Masks a region specified by clockwise vertices.
"""
mask = np.zeros_like(img)
if len(img.shape) > 2:
channel_count = img.shape[2] # i.e. 3 or 4 depending on your image
ignore_mask_color = (255,) * channel_count
else:
ignore_mask_color = 255
cv2.fillConvexPoly(mask, vertices, ignore_mask_color)
masked_image = cv2.bitwise_and(img, mask)
return masked_image
def __resize_image(self, img):
"""
Image is resized to the selected size for the project.
"""
return cv2.resize(img, self.g.img_size,
interpolation = cv2.INTER_CUBIC)
def __correct_distortion(self, img):
return self.distCorrector.undistort(img)
def __threshold_image(self, img):
return self.thresholder.get_thresholded_image(img)
def __warp_image_to_biv(self, img):
return cv2.warpPerspective(img, self.g.M, self.g.img_size)
def test_one_image(self, pt):
image = (mpimg.imread(pt))
return self.__image_pipeline(image)
八、最终效果
%matplotlib inline
obj = LaneFinder()
result = obj.test_one_image('./output/visualize_test6.jpg')print(type(result), result.shape)
plt.figure(figsize=(15,12))
plt.imshow(result)
plt.savefig('result.png')
plt.show()
小结
本项目使用PaddleX提供的高层接口,快速、高效地完成了无人驾驶任务中车辆检测部分的模型训练和部署。最大的感受就是Paddle为开发者提供了很好的开发环境。通过Python API方式完成全流程使用或集成,该模型提供全面、灵活、开放的深度学习功能,有更高的定制化空间以及更低门槛的方式快速完成产业模型部署,并提供了应用层的软件和可视化服务。
数据集选择和模型选择。训练集最终选择了UA-DETRAC 数据集,并且我也将该训练集转换到了VOC格式并在AI Studio上公开。模型最终选择了PaddleX提供的YOLOv3,该算法不仅在COCO、VOC等公开数据集上表现出色,并且实践证明在别的任务中,YOLOv3也具有比其他算法更好的泛化能力。
开发过程:开发最初效果并不理想,在UA-DETRAC数据集上的mAP仅有0.64左右。这里尝试了调整学习率、批次大小等超参数,并使用了不同的数据增强方法,但是提升效果微乎其微。最终查阅原论文发现,YOLOv3使用了K-means的方法获取预选框大小。修改并训练后,检测精度得到了很好的提升(mAP为0.79左右)。

人工设置anchor大小的弊端:
修改前anchor使用默认值。这些anchor虽然能够提供不同尺寸和长宽比的ROI,但是针对特定任务,有一些大小的anchor并不能很好地表征目标,甚至会额外增加不必要的计算量。比如针对小目标检测,较大的anchor几乎不会被选取为正样本。而且如果anchor的尺寸和目标的尺寸差异较大,则会影响模型的检测效果。
YOLO的作者Joseph Redmon等建议使用K-means聚类来代替人工设计,通过对训练集的真值框进行聚类,自动生成一组更加适合数据集的anchor大小,可以使网络的检测效果更好。
K-means算法获取anchor大小:
Joseph Redmon希望anchor能够满足与目标框尽可能相似并且距离尽可能相近,所以他提出了选取anchor大小的度量d:
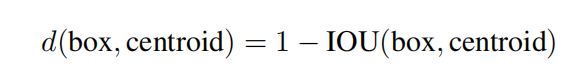
其中IOU表示真值框和预选框的交并比。
因此,最终算法步骤为:
随机选取K个box作为初始anchor;
使用IOU度量,将每个box分配给与其距离最近的anchor;
计算每个簇中所有box宽和高的均值,更新anchor;
重复2、3步,直到anchor不再变化,或者达到了最大迭代次数。
在UA-DETRAC数据集上得到的anchor大小为:
(13,11),(17,15),(23,17),(29,23),
(41,29),(68,33),(51,46),(93,57),(135,95)
相关代码参考:
https://github.com/ybcc2015/DeepLearning-Utils/tree/master/Anchor-Kmeans
def iou(boxes, anchors):
# 计算IOU
w_min = np.minimum(boxes[:, 0, np.newaxis], anchors[np.newaxis, :, 0])
h_min = np.minimum(boxes[:, 1, np.newaxis], anchors[np.newaxis, :, 1])
inter = w_min * h_min
box_area = boxes[:, 0] * boxes[:, 1]
anchor_area = anchors[:, 0] * anchors[:, 1]
union = box_area[:, np.newaxis] + anchor_area[np.newaxis]
return inter / (union - inter)
def fit(self, boxes):
if self.n_iter > 0:
self.n_iter = 0
np.random.seed(self.random_seed)
n = boxes.shape[0]
# 初始化随机anchor大小
self.anchors_ = boxes[np.random.choice(n, self.k, replace=True)]
self.labels_ = np.zeros((n,))
while True:
self.n_iter += 1
if self.n_iter > self.max_iter:
break
self.ious_ = self.iou(boxes, self.anchors_)
distances = 1 - self.ious_
cur_labels = np.argmin(distances, axis=1)
# 如果anchor大小不再变化,则表示已收敛,终止迭代
if (cur_labels == self.labels_).all():
break
# 更新anchor大小
for i in range(self.k):
self.anchors_[i] = np.mean(boxes[cur_labels == i], axis=0)
self.labels_ = cur_labels
此案例应用的目标检测场景,还可以通过飞桨目标检测套件PaddleDetection来实现,这里提供了更专业的端到端开发套件和工具,欢迎感兴趣的小伙伴动手实践一把。
PaddleDetection GitHub项目地址:
https://github.com/PaddlePaddle/PaddleDetection
更多资源
如在使用过程中有问题,可加入飞桨官方QQ群进行交流:703252161。
飞桨PaddleX技术交流QQ群:1045148026
如果您想详细了解更多飞桨的相关内容,请参阅以下文档。
官网地址:
https://www.paddlepaddle.org.cn
更多PaddleX的应用方法,欢迎访问项目地址:
GitHub:
https://github.com/PaddlePaddle/PaddleX
Gitee:
https://gitee.com/paddlepaddle/PaddleX
飞桨开源框架项目地址:
GitHub:
https://github.com/PaddlePaddle/Paddle
Gitee:
https://gitee.com/paddlepaddle/Paddle
END
