MRSN:Multi-scale Residual Network for Image Super-Resolution 论文理解
Multi-scale Residual Network for Image Super-Resolution
用于图像高分辨率的多尺度残差网络
原文:Multi-scale Residual Network for Image Super-Resolution, ECCV2018
github(pytorch): https://github.com/MIVRC/MSRN-PyTorch
MRSN:Multi-scale Residual Network for Image Super-Resolution 论文翻译
摘要:近年来的研究表明,深度神经网络可以显著提高单幅图像的超分辨率。目前的研究倾向于使用更深层次的卷积神经网络来提高性能。然而,盲目地增加网络的深度并不能有效地改善网络。更糟糕的是,随着网络深度的增加,训练过程中出现的问题越来越多,需要更多的训练技巧。在本文中,我们提出了一种新的多尺度残差网络(multiscale residual network,MSRN) 来充分利用图像的特征,其性能优于大多数现有的方法。在残差块的基础上,引入不同大小的卷积核,自适应地检测不同尺度的图像特征。同时,我们让这些特征相互作用,得到最有效的图像信息,我们称之为结构多尺度残差块(Multi-scale Residual Block,MSRB)。此外,将每个MSRB的输出作为不同层次的特征进行全局特征融合。最后,将所有这些特征送到重构模块,获得高分辨率图像。
发现问题
作者从重构实验开始,如重建了一些经典的SR模型,如SRCNN [1], EDSR[9]和SRResNet[8],发现现有的SR模型存在以下问题:
(a)很难复现:大多数高级模型对网络的细微变化敏感,需要很高的训练技巧;而其性能的提高很大程度是依赖与训练的技巧,而不是模型架构的改变
(b)特征利用不足:大多数方法为了提高网络的性能而盲目地增加网络的深度,而忽略了充分利用LR图像的特征。随着网络深度的增加,特征在传输过程中逐渐消失。如何充分利用这些特征,是网络重构高质量图像的关键。
(c)可扩展性不足:对LR图像进行预处理再输入,增加了计算复杂性而且会产生可见的伪影;最近的方法直接在LR图像放大重建,但其SR模型很难适应任意的缩放因子。
问题解决
提出了一种新的多尺度残差网络(MSRN)来充分利用图像的特征:
(1)使用MSRB来获取不同尺度的图像特征(局部多尺度特征)。
(2)将每个MSRB的输出组合起来进行全局特征融合(HFFS,一个以1×1卷积核为瓶颈层)。
将局部多尺度特征与全局特征相结合,最大限度地利用LR图像特征,彻底解决特征在传输过程中消失的问题。
还设计了一个简单而高效重建结构可以很容易地实现多尺度的放大。
特别地,
对于问题(a),作者的模型不需要特殊的权重初始化方法或其他训练技巧;
对于问题(b),提出多尺度残差块MSRB(以检测不同尺度下的特征,3.1节)和分级特征融合结构HFFS(充分利用输入图像的特征并有益于重构,3.2节);
对于问题(c),作者设计了一种良好的图像重构结构,它可以很容易地扩展到任何向上扩展的因子,只需进行少量调整(3.2节和3.3节)。
网络结构
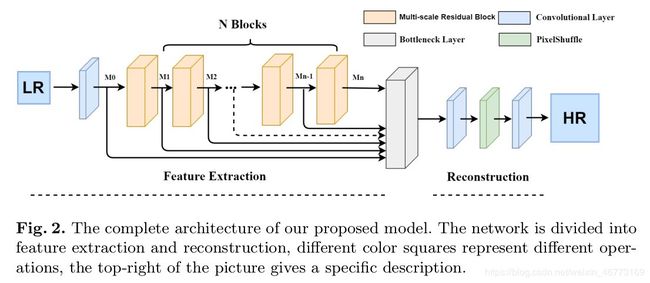
整个网络分为2个部分
- 特征提取部分
- 多尺度残差块(MSRB)
- 层次特征融合结构(HFFS)
- 重构部分
网络的详细描述:
使用LR图像直接作为输入。
a. 第一层卷积 M 0 M_0 M0 是用做初步的特征提取
b. 之后的 M 1 M_1 M1 到 M n M_n Mn 的内部结构是一模一样的,使用3×3和5×5卷积核进行多尺度特征 提取,然后每个 M i − 1 M_{i-1} Mi−1 到 M i M_i Mi使用残差连接,构成MSRB块,其包括多尺度特征融合和局部残差学习。(这是文章最重要的部分,就是多尺度的概念,这里的多尺度指 的是卷积核大小)
c. 然后,将每个 M i M_i Mi 的输出进行融合,使用1x1卷积将融合到的特征通道压缩成我们想 要的通道数量(与想要重建图像的大小有关),即层次特征融合结构(HFFS)
d. 最后,使用Pixel Shuffle(像素重组)ESPCN里的技术将图像扩大尺寸,在经过一个卷 积层,得到最后的重建图像。
网络细节介绍
多尺度残差块 (MSRB,3.1节)
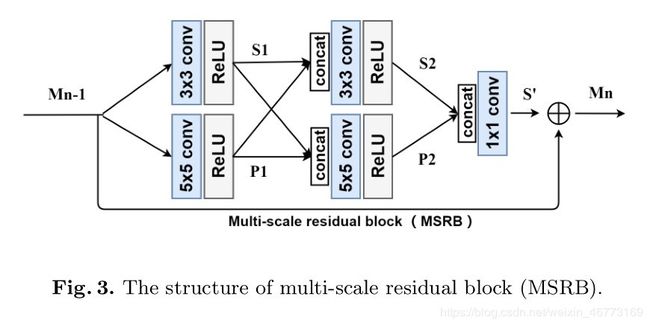
-
目的:检测不同尺度下的图像特征
-
组成:多尺度特征融合和局部残差学习
设M表示送到MSRB的特征图的数量(即通道数),因此:
(i) 第一个卷积层的输入和输出有M个通道,经过concat融合后(将3x3和5x5的卷积层的输出通道串联起来),
(ii) 则第二个卷积层输入或输出有 2M 个通道;
(iii) 然后再经过concat融合后,得到 4M 个通道 ,送到一个1×1 卷积层将这些特征映射的数量(通道的数量)减少到 M。
(iv) 最后,将MSRB块的输入残差连接到其输出(即残差连接,使得计算复杂度大大降低,有利于提高网络的效率)。
其中,(i)、(ii)、(iii) 为多尺度特征融合;(iv) 为局部残差学习。
最终,MSRB的输入和输出具有相同数量的特征映射(即相同的通道数量)
分级特征融合结构(HFFS,3.2节)
即网络结构详细介绍部分的 c 步骤
c. 然后,将每个 M i M_i Mi 的输出进行融合,使用1x1卷积将融合到的特征通道压缩成我们想要的通道数量
依据原理:
对于SISR问题,输入和输出图像是高度相关的;
随着网络深度的增加,图像的特征在传输过程中逐渐消失,可使用跳跃连接这一最简单、最有效的方法来解决这样问题;
随着深度的增加,网络的空间表达能力逐渐下降,而语义表达能力逐渐增强;
每个MSRB的输出都包含不同的特性。
因此,作者提出了一个简单的分级特征融合结构(HFFS),将MSRB的所有输出发送到网络的末端进行重构。但带来两个问题:
- MSRB的输出特征图包含了大量的冗余信息
- 直接将它们用于重构会大大增加计算复杂度
所以, 连接( concatenation)操作之后,再使用具有1×1内核的卷积层,以自适应地从这些层次化特征中提取有用的信息。
分级特征融合结构(HFFS)的输出可以表示为:
![]()
其中, M 0 M_0 M0 为第一卷积层的输出, M i ( i ≠ 0 ) M_i(i \neq 0) Mi(i=0) 为第 i i i 个MSRB的输出, [ M 0 , M 1 , M 2 , ⋯ , M N ] [M_0,M_1,M_2, \cdots , M_N] [M0,M1,M2,⋯,MN] 表示连接( concatenation)操作。
图像重建(3.3节)
之前的工作将LR图像进行先预处理再输入,如使用bicubic(双线性插值)上采样到与HR相同的维度,然后输入到网络中。然而,这种方法引入了冗余信息,增加了计算复杂度。
最近的工作倾向于使用未放大的LR作为输入图像,以训练一个可以直接上采样到HR维度的网络。但,这些网络中的大多数往往是一个固定的放大因子(如 x4),很难只需对网络进行少量调整就能够迁移到任何向上放大的因子。
灵感来源:
PixelShuffle [2] 和反卷积层在SISR任务中得到了广泛的应用。
如下图所示,有几种常见的重构模块。以放大因子4为例,各模块均采用PixelShuffle或反卷积操作,以放大因 子2为基础逐步重构SR图像。然而,随着规模因子的增加(如x8),网络变得更加深入,训练问题也变得更加不确 定。
此外,这些方法对奇数向上缩放因子不起作用,而人们可能希望放大因子是缓慢增长的(2–>3–>4–>5),而不 是指数增长。

因此,作者利用pixelshuffle(像素重组)方法,提出了新的重构模块,该模块结构简单、高效、灵活,只需进行少量调整(只需改变M的值),模块就可以迁移到任何放大因子。
实验
数据集
-
训练集:DIV2K
使用800张图像用于训练 (DIV2K 1-800)
下载地址:https://data.vision.ee.ethz.ch/cvl/DIV2K/
或SNU_CVLab
-
测试集:五个数据集
Set5 , Set14, BSDS100, Urban100 and Manga109
下载地址: original test datasets (HR images) ,OriginalTestData.zip
test datasets (Preprocessed HR images), Test datasets.zip
作者所有的训练和测试都是基于YCbCr色彩空间中的亮度通道进行的,并使用了放大因子:×2、×3、×4、×8进行训练和测试。
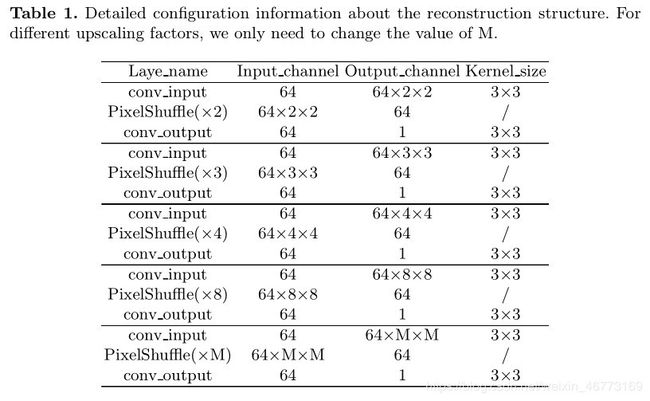
对不同的放大因子,只需改变M的值。
训练设置
数据增强:(1)缩放(2)旋转(3)翻转
训练优化器:ADAM optimizer
初始学习率:lr = 0.0001
损失函数: L 1 L_1 L1
评价指标:PSNR/SSIM
MSRB个数:8
另外,每个训练批次batch中,随机抽取16个LR patch,大小为64×64。
结果展示:

作者最后测试发现模型在不同的上升率因子和测试数据集上表现得非常好,但是结过略低于EDSR(注意:EDSR使用RGB通道用于训练,同时,数据增强方法也不同),表3为它们之间的区别:
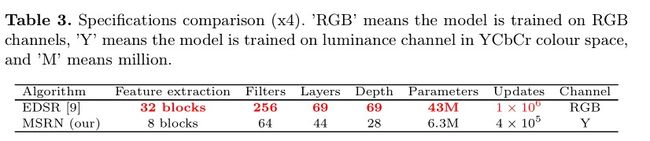
作者的模型规格比EDSR小得多,这使得它更容易复制和推广。
补充:
作者在github说为了更方便比较,到已经在RGB三个通道进行了训练,结果如下:
| Model | Scale | Set5 | Set14 | B100 | Urban100 | Manga109 |
|---|---|---|---|---|---|---|
| old (paper) | x2 | 38.08/0.9605 | 33.74/0.9170 | 32.23/0.9013 | 32.22/0.9326 | 38.82/0.9868 |
| MSRN | x2 | 38.07/0.9608 | 33.68/0.9184 | 32.22/0.9002 | 32.32/0.9304 | 38.64/0.9771 |
| MSRN+ | x2 | 38.16/0.9611 | 33.82/0.9196 | 32.28/0.9080 | 32.47/0.9316 | 38.87/0.9777 |
| old (paper) | x3 | 34.38/0.9262 | 30.34/0.8395 | 29.08/0.8041 | 28.08/0.8554 | 33.44/0.9427 |
| MSRN | x3 | 34.48/0.9276 | 30.40/0.8436 | 29.13/0.8061 | 28.31/0.8560 | 33.56/0.9451 |
| MSRN+ | x3 | 34.59/0.9285 | 30.51/0.8454 | 29.20/0.8073 | 28.49/0.8588 | 33.91/0.9470 |
| old (paper) | x4 | 32.07/0.8903 | 28.60/0.7751 | 27.52/0.7273 | 26.04/0.7896 | 30.17/0.9034 |
| MSRN | x4 | 32.25/0.8958 | 28.63/0.7833 | 27.61/0.7377 | 26.22/0.7905 | 30.57/0.9103 |
| MSRN+ | x4 | 32.41/0.8975 | 28.76/0.7859 | 27.68/0.7394 | 26.39/0.7946 | 30.92/0.9136 |
| old (paper) | x8 | 26.59/0.7254 | 24.88/0.5961 | 24.70/0.5410 | 22.37/0.5977 | 24.28/0.7517 |
| MSRN | x8 | 26.95/0.7728 | 24.87/0.6380 | 24.77/0.5954 | 22.35/0.6124 | 24.40/0.7729 |
| MSRN+ | x8 | 27.07/0.7784 | 25.03/0.6422 | 24.83/0.5974 | 22.51/0.6182 | 24.62/0.7795 |
其中,把自集成策略用于提升MSRN,称为MSRN+。
可以发现,MSRN在RGB三个通道进行训练时,其参数数量也相应扩大3倍,PSNR/SSIM略有提高,但还是略低于EDSR。
补充:作者对减去均值的原回答
在训练时需要设置the r_mean, g_mean, b_mean,如何获得这些参数呢?
需要计算整个数据集的R、G、B通道的平均值。如果值在0-255之间,还应该除以255使它们在0-1之间。
为什么每张输入图片要减去DIV2K RGB的均值?
从输入中减去平均值得到零输入,这提供了更稳定的训练。更重要的是,如果你使用的是一个预先训练过的网络,它是用零均值输入训练的,那么你提供的输入也应该是零均值,否则结果的像素值将会移位。
总结
- 为了自适应检测不同尺度的图像特征,作者提出了一种高效的多尺度残差块
- 为了充分利用输入图像的多层次特征并有益于重构,提出了分级特征融合结构HFFS
- 为了很容易的向上扩展任意因子,作者利用Pixel Shuffle(像素重组)设计了一种新的重构模块
结合三个模块,作者提出了多尺度残差网络(multi-scale residual network, MSRN),获得准确的SR图像。
该模型比最先进的EDSR方法轻量许多(网络的层数,深度,参数都比EDSR小很多),却达到了与之相称的性能。