十一:Flume常用Source配置-taildir-source
一:Flume概述:
Apache Flume is a distributed, reliable, and available system for efficiently collecting, aggregating and moving large amounts of log data from many different sources to a centralized data store.
Apache Flume是一个分布式的、可靠的、可用的系统,用于有效地收集、聚合和将大量日志数据从许多不同的源转移到一个集中的数据存储区
The use of Apache Flume is not only restricted to log data aggregation. Since data sources are customizable, Flume can be used to transport massive quantities of event data including but not limited to network traffic data, social-media-generated data, email messages and pretty much any data source possible.
Apache Flume的使用不仅限于记录数据聚合。由于数据源是可定制的,所以可以使用Flume传输大量事件数据,包括但不限于网络流量数据、社交媒体生成的数据、电子邮件消息以及几乎任何可能的数据源。
1.1:Flume各组件作用:
Source: 收集数据
Channel: 缓存数据
Sink: 写数据

1.2:一个简单配置:
描述一个整体的Agent各组件名称:
# 1:Name the components on this agent ( 描述这个Agent,给个组件取个名字)
a1.sources = r1
a1.sinks = k1
a1.channels = c1
描述配置这个Source类型:
# Describe/configure the ***source***
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
描述配置这个Sink:
# Describe the sink
a1.sinks.k1.type = logger
描述配置Channel:
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
关联上Sources和channel:
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
二:taildir-source 配置:
Watch the specified files, and tail them in nearly real-time once detected new lines appended to the each files. If the new lines are being written, this source will retry reading them in wait for the completion of the write.
This source is reliable and will not miss data even when the tailing files rotate. It periodically writes the last read position of each files on the given position file in JSON format. If Flume is stopped or down for some reason, it can restart tailing from the position written on the existing position file.
In other use case, this source can also start tailing from the arbitrary position for each files using the given position file. When there is no position file on the specified path, it will start tailing from the first line of each files by default.
Files will be consumed in order of their modification time. File with the oldest modification time will be consumed first.
This source does not rename or delete or do any modifications to the file being tailed. Currently this source does not support tailing binary files. It reads text files line by line.
# Name the components on this agent
taildir-logger-agent.sources = taildir-source
taildir-logger-agent.channels = memory-channel
taildir-logger-agent.sinks = logger-sink
# Describe/configure the source
taildir-logger-agent.sources.taildir-source.type = TAILDIR
taildir-logger-agent.sources.taildir-source.filegroups = ceshi
taildir-logger-agent.sources.taildir-source.filegroups.ceshi = /home/hadoop/data/logger.txt
taildir-logger-agent.sources.taildir-source.positionFile=/home/hadoop/app/apache-flume-1.6.0-cdh5.7.0-bin/taildir_position.json
# Use a channel which buffers events in memory
taildir-logger-agent.channels.memory-channel.type = memory
# Describe the sink
taildir-logger-agent.sinks.logger-sink.type = logger
# Bind the source and sink to the channel
taildir-logger-agent.sources.taildir-source.channels = memory-channel
taildir-logger-agent.sinks.logger-sink.channel = memory-channel
三:实战效果:
./flume-ng agent --conf /home/hadoop/app/apache-flume-1.6.0-cdh5.7.0-bin/conf --conf-file /home/hadoop/app/apache-flume-1.6.0-cdh5.7.0-bin/conf/taildir-logger-agent.conf --name taildir-logger-agent -Dflume.root.logger=INFO,console
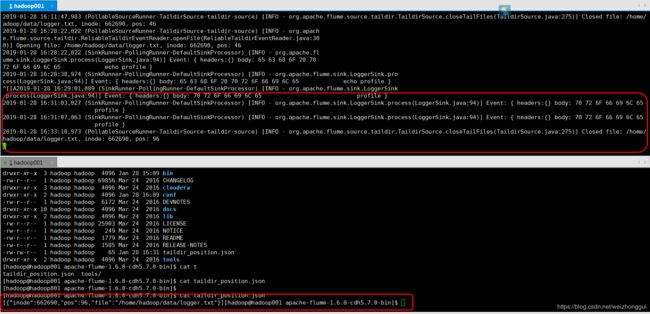
四:优势:
每条数据叫做一个event
1:断点续传;EXEC做不到
2:追加数据可正确收集,SPOOLING做不到
-f 在追踪文件时,如果文档被删除、转移或者重建了, 就停止不会再输出了。
-F 如果文件重建了, 会继续追踪。不会因为文件被删除、转移或者重建而就停止追踪。
Caused by: java.nio.file.AccessDeniedException: /home/hadooop
drwx------ 13 hadoop hadoop 4096 Jan 28 15:28 hadoop