Kaggle Challenge(1)入门:Titanic 泰坦尼克
文章目录
- 介绍
- Kaggle
- Titanic
- 上传格式
- 初始化
- Python Notebook
- 载入library
- helper functions
- 载入数据
- 数据描述
- load数据
- train test val
- 数据特征
- 基本特征
- describe()
- head()
- correlation heatmap
- area map
- 数据清理
- 将categorical variable改成numeric
- 性别(binary)
- Embarked(登陆地点)
- 消失数据的填补
- Feature Engineering创建Feature
- 从Name中获取官衔
- 仓位编号
- 票编码同理
- 家庭成员数量
- 选择有意义的column
- 组合
- pd.concat
- X和y
- 分成训练组和测试组
- 各个feature的重要程度
- 分类模型的选择
- training 训练
- training score&validation score
- rfecv选择最佳feature数量
- 选择前10个feature
- 预测结果,并且提交我们的预测
介绍
英文资料:链接
Kaggle
Kaggle 是一个数据科学竞赛的平台,很多公司会发布一些接近真实业务的问题,吸引爱好数据科学的人来一起解决。
https://www.kaggle.com/
Titanic
Titanic界面/数据地址
Titanic是Kaggle入门级的数据,我们的目标是“预测这个人是否生还”
泰坦尼克惨剧死了非常多的人,但是因为某些原因,生还的很大部分乘客是妇女儿童以及上流人士。
在本篇博文中,我将用Kaggle给我们的数据,利用Python中的sklearn library制作一个机器学习算法,预测乘客是否能生存。
上传格式
Submission File Format:
You should submit a csv file with exactly 418 entries plus a header row. Your submission will show an error if you have extra columns (beyond PassengerId and Survived) or rows.
The file should have exactly 2 columns:
- PassengerId (sorted in any order)
- Survived (contains your binary predictions: 1 for survived, 0 for deceased)
最后我们需要上传一个csv 文件,其中一列包括PassengerId,另一列是我们对这个人生死的预测。
注意,上传时需要使用VPN,不然会一直现实checking server。
初始化
Python Notebook
首先我们要下载并安装Jupyternotebook,如果你没有,可以直接使用Kaggle自带的notebook
载入library
这里我们需要的library:np,pandas,sklearn(机器学习模型),以及画图工具matplotlib。
如果import失败,可以通过pip install sklearn。但是通常情况下这些包都是最基础的,所以不需要install。
# 忽略警告
import warnings
warnings.filterwarnings('ignore')
# 最基本的两个library
import numpy as np
import pandas as pd
# sklearn大家族,各种模型算法
from sklearn.tree import DecisionTreeClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVC, LinearSVC
from sklearn.ensemble import RandomForestClassifier , GradientBoostingClassifier
# 建模帮手
# Modelling Helpers
from sklearn.preprocessing import Imputer , Normalizer , scale
from sklearn.model_selection import train_test_split,StratifiedKFold
#值得注意的是,sklearn改版后train test split
# 不再是cross_validation下面的
# 而是model_selection里的
from sklearn.feature_selection import RFECV
# 画图工具matplot
import matplotlib as mpl
import matplotlib.pyplot as plt
import matplotlib.pylab as pylab
import seaborn as sns
# 指定画图的尺寸和颜色
%matplotlib inline
mpl.style.use( 'ggplot' )
sns.set_style( 'white' )
pylab.rcParams[ 'figure.figsize' ] = 8 , 6
helper functions
不需要知道含义,只是一些画图工具
def plot_histograms( df , variables , n_rows , n_cols ):
fig = plt.figure( figsize = ( 16 , 12 ) )
for i, var_name in enumerate( variables ):
ax=fig.add_subplot( n_rows , n_cols , i+1 )
df[ var_name ].hist( bins=10 , ax=ax )
ax.set_title( 'Skew: ' + str( round( float( df[ var_name ].skew() ) , ) ) ) # + ' ' + var_name ) #var_name+" Distribution")
ax.set_xticklabels( [] , visible=False )
ax.set_yticklabels( [] , visible=False )
fig.tight_layout() # Improves appearance a bit.
plt.show()
def plot_distribution( df , var , target , **kwargs ):
row = kwargs.get( 'row' , None )
col = kwargs.get( 'col' , None )
facet = sns.FacetGrid( df , hue=target , aspect=4 , row = row , col = col )
facet.map( sns.kdeplot , var , shade= True )
facet.set( xlim=( 0 , df[ var ].max() ) )
facet.add_legend()
def plot_categories( df , cat , target , **kwargs ):
row = kwargs.get( 'row' , None )
col = kwargs.get( 'col' , None )
facet = sns.FacetGrid( df , row = row , col = col )
facet.map( sns.barplot , cat , target )
facet.add_legend()
def plot_correlation_map( df ):
corr = titanic.corr()
_ , ax = plt.subplots( figsize =( 12 , 10 ) )
cmap = sns.diverging_palette( 220 , 10 , as_cmap = True )
_ = sns.heatmap(
corr,
cmap = cmap,
square=True,
cbar_kws={ 'shrink' : .9 },
ax=ax,
annot = True,
annot_kws = { 'fontsize' : 12 }
)
def describe_more( df ):
var = [] ; l = [] ; t = []
for x in df:
var.append( x )
l.append( len( pd.value_counts( df[ x ] ) ) )
t.append( df[ x ].dtypes )
levels = pd.DataFrame( { 'Variable' : var , 'Levels' : l , 'Datatype' : t } )
levels.sort_values( by = 'Levels' , inplace = True )
return levels
def plot_variable_importance( X , y ):
tree = DecisionTreeClassifier( random_state = 99 )
tree.fit( X , y )
plot_model_var_imp( tree , X , y )
def plot_model_var_imp( model , X , y ):
imp = pd.DataFrame(
model.feature_importances_ ,
columns = [ 'Importance' ] ,
index = X.columns
)
imp = imp.sort_values( [ 'Importance' ] , ascending = False )
imp[ : 10 ].plot( kind = 'barh' )
print (model.score( X , y ))
载入数据
数据描述
我们一共有3个csv文件,分别是
- gender_submission
- train
- test
train和test.csv中的header一致。column分别是
4. Survived: 生存(1),死亡(0),也是我们想预测的
5. Pclass: 船舱等级,1最贵,3最便宜。
6. Name: 姓名
7. Sex: female为女,male为男
8. Age: 年龄
9. SibSp: 该乘客兄弟姐妹/夫妻(spouses)在船上的数量
10. Parch: 父母/儿女在船上的数量
11. Ticket: 票号
12. Fare: 船票价格
13. Cabin: 所在的舱号码
14. Embarked: 登船地点,有S,C,Q三中,上船的地方。这列可能有影响。
gender_submission 不知道是干什么的,暂且不管
load数据
我们将csv文件放在一个叫titanic的文件夹里,和我们的notebook平行。
train=pd.read_csv("titanic/train.csv")
test=pd.read_csv("titanic/test.csv")
full=train.append( test , ignore_index = True )
titanic=full[ :891 ]
del train , test
print ('Datasets:' , 'full:' , full.shape , 'titanic:' , titanic.shape)
在上面的操作中,我们将train+test放在是full这个dataframe中
我们的training data数据集叫titanic
train test val
我们为什么要把data分为train,test 甚至val 三个数据集?
train是训练集,val是训练过程中的测试集,是为了让你在边训练边看到训练的结果,及时判断学习状态。test就是训练模型结束后,用于评价模型结果的测试集。只有train就可以训练,val不是必须的,比例也可以设置很小。test对于model训练也不是必须的,但是一般都要预留一些用来检测,通常推荐比例是8:1:1
数据特征
基本特征
describe()
titanic.describe()

head()
titanic.head()

correlation heatmap
通过correlation heatmap,我们可以知道哪些feature和survived有较高的关联。correlation绝对值越高,关联性就越高
plot_correlation_map(titanic)
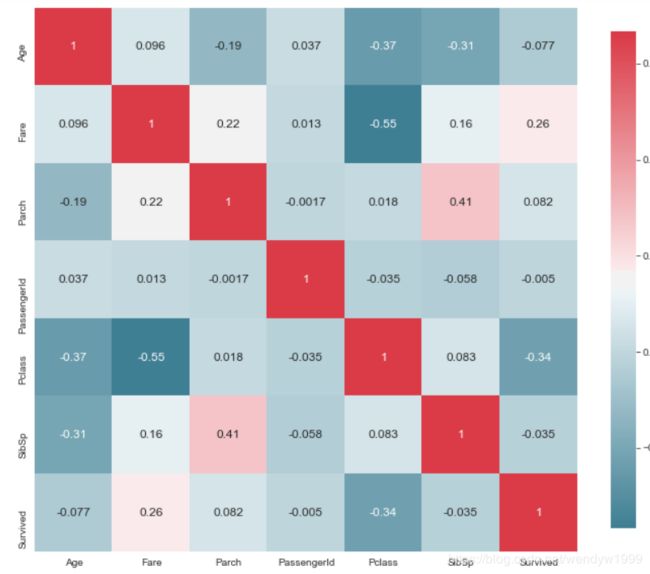
我们主要关注最后一行,其中Survived和Fare的correlation factor有.26,和Pclass有-.34,这两个是最高的。绝对值最低的是Passenger ID。我们在之后的数据清理中可以运用这些观察。
area map
plot_distribution( titanic , var = 'Age' , target = 'Survived' , row = 'Sex' )
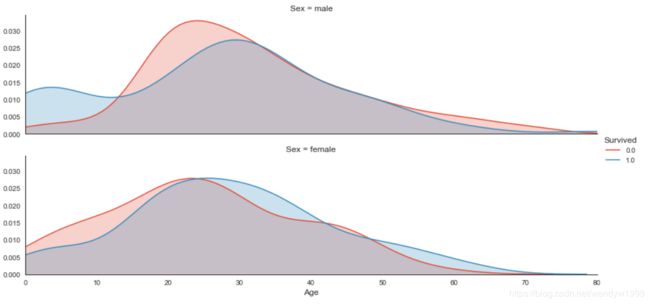
通过这个area map我们可以看,男人中,年龄较低的小男孩,生存比例大大高于死亡比例。但是在青壮年接段(15-30),死亡比例较高。壮年-中年,死亡和生存大概持平。老年男子中,死亡比例>生还比例。
女人中(下图),年纪轻的女性死得比活得多;年长的女性,活得比死的多。
我们还可以将代码中的Age替换为其他的variable,比如Fare。查看distribution。
数据清理
将categorical variable改成numeric
之前的heatmap中,我们发现,只有数字column显示在图表中,但是如果我们将那些文本column改成数字column,那么更方便与我们做图标、分析。
性别(binary)
对于binary(只有两种情况)的feature,我们可以直接用0和1表示。
我们可以用pandas的replace功能,1代表男,0代表女
sex = full["Sex"].replace({"male":1,"female":0})
Embarked(登陆地点)
dummy variable/onehot encode
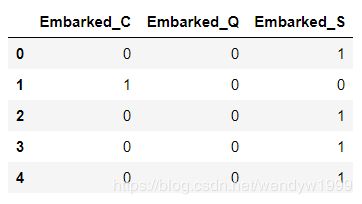
对于>2种可能性的feature,我们可以使用dummy variable。
embarked = pd.get_dummies( full.Embarked , prefix='Embarked' )
embarked
消失数据的填补
我们直接用已有数据的平均值来填补消失数据
imputed = pd.DataFrame()
# Fill missing values of Age with the average of Age (mean)
imputed[ 'Age' ] = full.Age.fillna( full.Age.mean() )
# Fill missing values of Fare with the average of Fare (mean)
imputed[ 'Fare' ] = full.Fare.fillna( full.Fare.mean() )
Feature Engineering创建Feature
从Name中获取官衔
我们会发现 Name中第一行有可能是Mr/Miss/Mrs 甚至是“上校”,“伯爵”之类的官衔/头衔。那么这些称谓或许和生存几率有一定的关系。
我们将这些头衔分为几个种类。
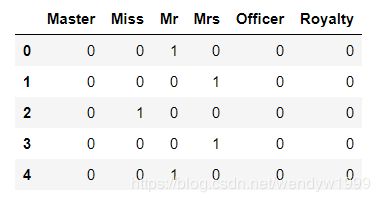
分别是:Officer(政府官员/军人), Royalty(皇室),Mr(男人),Miss(未出嫁的小姐),Mrs(已出嫁的夫人),Master(主人)。
title = pd.DataFrame()
# 首先将头衔split出来
title[ 'Title' ] = full[ 'Name' ].map( lambda name: name.split( ',' )[1].split( '.' )[0].strip() )
# 对应表
Title_Dictionary = {
"Capt": "Officer",
"Col": "Officer",
"Major": "Officer",
"Jonkheer": "Royalty",
"Don": "Royalty",
"Sir" : "Royalty",
"Dr": "Officer",
"Rev": "Officer",
"the Countess":"Royalty",
"Dona": "Royalty",
"Mme": "Mrs",
"Mlle": "Miss",
"Ms": "Mrs",
"Mr" : "Mr",
"Mrs" : "Mrs",
"Miss" : "Miss",
"Master" : "Master",
"Lady" : "Royalty"
}
# 使用dummy variable将头衔变成1和 0
title[ 'Title' ] = title.Title.map( Title_Dictionary )
title = pd.get_dummies( title.Title )
title.head()
仓位编号
仓位类似于一个id,在machine learning里面是没有卵用的。但是呢,我们可以从编号中获取一些有用的信息。一个仓位编号由一个英文字母,和几个数字组成。虽然不知道这些英文字母的含义,但是同一个英文字母的乘客应该有一定的关联。
cabin = pd.DataFrame()
# 将消失的数据用“U”代替,Unknown
cabin[ 'Cabin' ] = full.Cabin.fillna( 'U' )
# 保留第一个英文字母
cabin[ 'Cabin' ] = cabin[ 'Cabin' ].map( lambda c : c[0] )
# dummy encoding ...
cabin = pd.get_dummies( cabin['Cabin'] , prefix = 'Cabin' )
cabin.head()
票编码同理
# 一个获取编码开头字母的方程
def cleanTicket( ticket ):
ticket = ticket.replace( '.' , '' )
ticket = ticket.replace( '/' , '' )
ticket = ticket.split()
ticket = map( lambda t : t.strip() , ticket )
ticket = list(filter( lambda t : not t.isdigit() , ticket ))
if len( ticket ) > 0:
return ticket[0]
else:
return 'XXX'
ticket = pd.DataFrame()
# 创建dummy
ticket[ 'Ticket' ] = full[ 'Ticket' ].map( cleanTicket )
ticket = pd.get_dummies( ticket[ 'Ticket' ] , prefix = 'Ticket' )
ticket.shape
ticket.head()
家庭成员数量
我们可以通过将兄弟姐妹,夫妻,父母,儿女相加,再加上+1(他本人),获得整个家庭的数量。
family = pd.DataFrame()
# 计算家庭成员的数量
family[ 'FamilySize' ] = full[ 'Parch' ] + full[ 'SibSp' ] + 1
# 创建三个类别,单身乘坐,小家庭和大家庭。
family[ 'Family_Single' ] = family[ 'FamilySize' ].map( lambda s : 1 if s == 1 else 0 )
family[ 'Family_Small' ] = family[ 'FamilySize' ].map( lambda s : 1 if 2 <= s <= 4 else 0 )
family[ 'Family_Large' ] = family[ 'FamilySize' ].map( lambda s : 1 if 5 <= s else 0 )
family.head()

选择有意义的column
有意义的Feature包括
- Imputed(Age,Fare)
- Sex
- Cabin
- Family
- title
- Survived
- ticket
组合
pd.concat
df = pd.concat([full[["Pclass","Survived"]],
family,sex,ticket,cabin,title,embarked,imputed],axis=1)
df.head()
注意这里的axis=1!如果axis = 0的话就会出现很多NaNs
X和y
Survived是我们的target feature*(y),其他的feature是我们的X
full_X = df.drop("Survived",axis = 1)
full_y = df["Survived"]
分成训练组和测试组
前891行是我们的训练组,后面的是我们的测试组。
在训练组中,我们再将数据分为train和validation两组
使用train_test_split工具
train_valid_X = full_X[ 0:891 ]
train_valid_y = full_y[0:891]
test_X = full_X[ 891: ]
train_X , valid_X , train_y , valid_y = train_test_split( train_valid_X , train_valid_y , train_size = .7 )
print (full_X.shape , train_X.shape , valid_X.shape , train_y.shape , valid_y.shape , test_X.shape)
(1309, 63) (623, 63) (268, 63) (623,) (268,) (418, 63)
各个feature的重要程度
我们可以通过选择重要程度比较高的feature,减少feature的数量,避免overfitting。
plot_variable_importance(train_X, train_y)

分类模型的选择
我们有以下的选项
- SVC()
- 逻辑回归 LogisticRegression()
- RandomForestClassifier(n_estimators=100)
- KNeighborsClassifier(n_neighbors = 3)
- GradientBoostingClassifier()
- GaussianNB()
training 训练
在这里,我示范一下RandomForestClassifier的用法
这里需要注意,并不是所有模型都有best_features_这个属性,所以我选择了有这个属性的随机树林
model = RandomForestClassifier(n_estimators = 100)
model.fit(train_X,train_y)
n_estimators 设置的数值越大越好,但是会跑的慢。
training score&validation score
print("Training Score is:",
model.score( train_X , train_y ) ,
"\n","Validation Score is:",
model.score( valid_X , valid_y ))
Training Score is: 0.9935794542536116
Validation Score is: 0.835820895522388
我们发现validation score比training score小很多,这个模型有一定的overfiting问题。
所以我们可以通过筛选feature的方式,提升val score
rfecv选择最佳feature数量
下面的比较慢,通过cross validation的方式,计算出accuracy最高的情况下的,feature数量。
model =RandomForestClassifier(n_estimators=100)
rfecv = RFECV( estimator = model , step = 1 , cv =5, scoring = 'accuracy' )
rfecv.fit( train_X , train_y )
print (rfecv.score( train_X , train_y ) , rfecv.score( valid_X , valid_y ))
print( "Optimal number of features : %d" % rfecv.n_features_ )
# Plot number of features VS. cross-validation scores
plt.figure()
plt.xlabel( "Number of features selected" )
plt.ylabel( "Cross validation score (nb of correct classifications)" )
plt.plot( range( 1 , len( rfecv.grid_scores_ ) + 1 ) , rfecv.grid_scores_ )
plt.show()
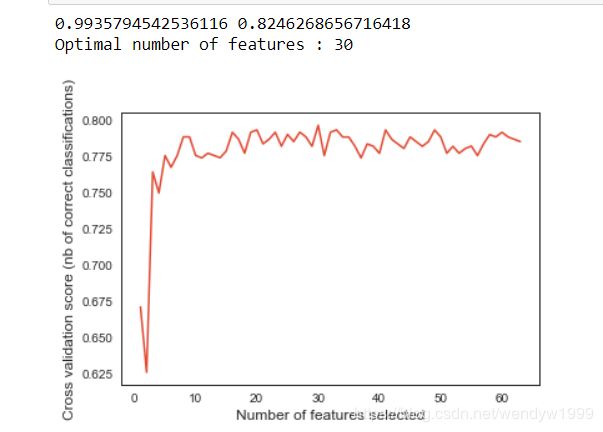
我们会发现,features数量大于10之后,其实accuracy都是差不多的。所以我们可以选择少一点,避免overfitting。
选择前10个feature
model = RandomForestClassifier(n_estimators = 100)
model.fit(train_X,train_y)
imp = pd.DataFrame(
model.feature_importances_ ,
columns = [ 'Importance' ] ,
index = train_X.columns
)
imp = imp.sort_values( [ 'Importance' ] , ascending = False )
features = imp[:8].index.tolist()
features
['Age', 'Fare', 'Sex', 'Mr', 'Pclass', 'FamilySize', 'Cabin_U', 'Miss']
model = RandomForestClassifier(n_estimators = 100)
model.fit(train_X[features],train_y)
print("Training Score is:",model.score( train_X[features] , train_y ) , "\n","Validation Score is:",model.score( valid_X[features] , valid_y ))
预测结果,并且提交我们的预测
Kaggle最后要上交你对test_X的预测结果,也就是test_y.我们将这些数据以及PassengerID一起放在一个叫titanic_pred.csv的文件里。上传到kaggle的submit challenge里
这里要注意:所有的Survived里的1和0必须是int。我上传了一次结果拿了零分,马上意识到一定是data type出了问题。
model = RandomForestClassifier(n_estimators = 100)
model.fit(train_X[features],train_y)
test_Y = model.predict(test_X[features])
passenger_id = full[891:].PassengerId
test = pd.DataFrame( { 'PassengerId': passenger_id , 'Survived': test_Y } )
#这里很重要,必须从float改成int,不然会得零分。
test["Survived"]=test["Survived"].apply(int)
test.shape
test.head()
test.to_csv( 'titanic_pred.csv' , index = False )
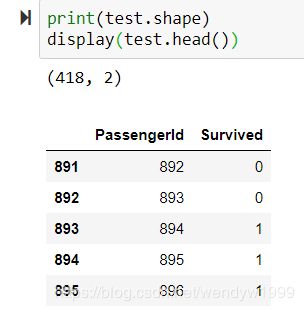
确保数据的data type和行数是正确的~必须要有header。
可以点击csv进去再次检查。
最后我拿了0.72分~