tensorflow学习笔记
tensorflow-计算图
tensorflow-张量
tensorflow-会话session()
变量初始化
tf提供了一种初始化所有变量的方法:`
init_op=tf.global_variables_initializer()
sess.run(init_op)
tensorflow 样例
placeholder机制
用于提供输入数据
import tensorflow as tf
w1=tf.Variable(tf.random_normal((2,3),stddev=1,seed=1))
w2=tf.Variable(tf.random_normal((3,1),stddev=1,seed=1))
x=tf.placeholder(tf.float32,shape=(1,2),name="input")
a=tf.matmul(x,w1)
y=tf.matmul(a,w2)
sess=tf.Session()
init_op=tf.global_variables_initializer()
sess.run(init_op)
print(sess.run(y,feed_dict={x:[[0.7,0.9]]}))
sess.close()
feed_dict是一个字典,用于指定x的取值
一个小小的样例,先熟悉一下tensorflow的流程
import tensorflow as tf
from numpy.random import RandomState
batch_size=8
w1=tf.Variable(tf.random_normal((2,3),stddev=1,seed=1))
w2=tf.Variable(tf.random_normal((3,1),stddev=1,seed=1))
x=tf.placeholder(tf.float32,shape=(None,2),name="input")
y_=tf.placeholder(tf.float32,shape=(None,1),name="input")
#定义前向传播过程
a=tf.matmul(x,w1)
y=tf.matmul(a,w2)
#定义损失函数和反向传播的算法
y=tf.sigmoid(y)
cross_entropy=-tf.reduce_mean(
y_*tf.log(tf.clip_by_value(y,1e-10,1.0))+(1-y_)*tf.log(tf.clip_by_value(1-y,1e-10,1.0)))
train_step=tf.train.AdamOptimizer(0.001).minimize(cross_entropy)
#通过随机数生成模拟数据集
rdm=RandomState(1)
dataset_size=128
X=rdm.rand(dataset_size,2)
Y=[[int(x1+x2)<1] for (x1,x2) in X]
#创建会话
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op)
#设定训练的轮次
STEPS=10000
for i in range(STEPS):
#每次选取batch_size个数据进行训练
start=(i*batch_size)%dataset_size
end=min(start+batch_size,dataset_size)
#训练
sess.run(train_step,feed_dict={x:X[start:end],y_:Y[start:end]})
if i%100==0:
total_cross_entropy=sess.run(cross_entropy,feed_dict={x:X,y_:Y})
print("After %d training step(s),cross entropy on all data is %g" %(i,total_cross_entropy))
输出结果:

损失函数
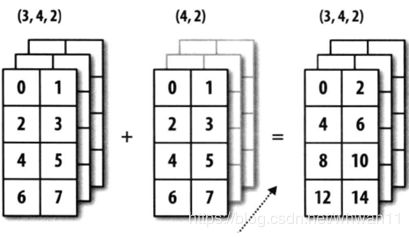
tf.greater():比较输入向量中每一个元素的大小并返回比较结果,当输入两个向量的维度不匹配时,会执行类似于Numpy的广播操作;
广播操作(Broadcasting):如果两个数组的后缘维度(trailing dimension,即从末尾开始算起的维度)的轴长度相符,或其中的一方的长度为1,则认为它们是广播兼容的。广播会在缺失和(或)长度为1的维度上进行。
通俗理解广播机制: