深度学习相关优化器以及在tensorflow的使用
参考链接:https://arxiv.org/pdf/1609.04747.pdf 优化器对比论文
https://www.leiphone.com/news/201706/e0PuNeEzaXWsMPZX.html 论文翻译版
http://blog.csdn.net/u014381600/article/details/72867109 Adam和SGD优化器比较
梯度下降框架
给定优化的模型参数 θ∈Rd θ ∈ R d 和目标函数 J(θ) J ( θ ) 后,算法沿着梯度 ∇θJ(θ) ∇ θ J ( θ ) 的相反方向更新 θ θ 最小化 J(θ) J ( θ ) 。学习率 η η 决定了每一时刻的更新步长。对某一步,可以用下述步骤描述梯度下降流程:
1.计算目标函数的梯度
gt g t 表示参数 θ θ 在第t步的梯度。
2.根据历史梯度计算一阶和二阶动量
3.更新模型参数
其中, ϵ ϵ 为平滑项,防止分母为0,通常取 1e−8 1 e − 8
1.Vanilla SGD
朴素梯度下降最为简单,没有动量的概念,即: mt=ηgt m t = η g t
所以更新步骤为: θt+1=θt−ηgt θ t + 1 = θ t − η g t
首先为梯度下降最常见的三种变形BGD,SGD,MBGD,这三种优化器的区别为用多少数据计算目标函数的梯度
Batch gradient descent
更新规则:采用整个训练集的数据来计算loss函数对参数的梯度:
算法:
for i in range ( nb_epochs ):
params_grad = evaluate_gradient ( loss_function , data , params )
params = params - learning_rate * params_grad
优点:对于凸函数可以收敛到全局极小值,对于非凸函数可以收敛到局部极小值
缺点:在一次更新中,对整个数据集计算梯度,计算速度很慢;如果数据集过大,则内存无法容纳;在模型训练过程中,无法使用新的数据更新模型。
2.Stochastic gradient descent
更新规则:SGD每次更新时对每个样本进行梯度下降。
for i in range ( nb_epochs ):
np. random . shuffle ( data )
for example in data :
params_grad = evaluate_gradient ( loss_function , example , params )
params = params - learning_rate * params_grad
优点:对于很大的数据集来说,可能有很相似的样本,导致BGD在计算梯度时会出现冗余,而SGD一次只进行单样本更新,所以针对一次更新来说没有冗余,而且速度快
缺点:更新频繁,造成loss函数严重震荡。

BGD可以收敛到局部最小值,SGD的震荡也可能跳到更优的局部最小值。稍微减少learning rate,SGD和BGD收敛性一致,对凸函数和非凸函数能分别收敛到全局最优和局部最优。
3.Mini-batch Stochastic gradient descent
梯度更新规则:每一次更新使用一小批样本进行更新
超参数: η η 一般取值为50~256,取决于不同的应用
优点:降低参数更新时的方差,收敛更稳定;可利用深度学习库中高度优化的矩阵操作来更有效的梯度计算
**缺点:****MBSGD不能保证很好的收敛性,提供了一系列的挑战需要去解决:
1.选择合适的learning rate十分困难。如果选择的太小,收敛速度太慢;如果太大,loss函数会在极小值出震荡甚至发散。
2.学习率在训练过程中退火调整,学习率的减少根据提前确定好的计划或者当目标在两个轮次之间的变化低于一个阈值,计划和阈值必须要提前确定,因此不能适应数据集的特征。
3.对所有参数更新时应用同样的learning rate,如果数据是稀疏的,更希望对出现频率低的特征进行大一点的更新。
4.对于非凸的误差函数,要避免陷入局部极小值以及鞍点处。鞍点周围的梯度都一样并且趋近于0,SGD不容易突破。
4.SGD with momentum
SGD在山谷的情况下不容易导向,会多走一些弯路,山谷的曲面在某一个参数维度会比另外一个参数维度更陡峭,这种情况在局部最优解附近很常见。在这种场景下,SGD穿过山谷的斜坡时会震荡。
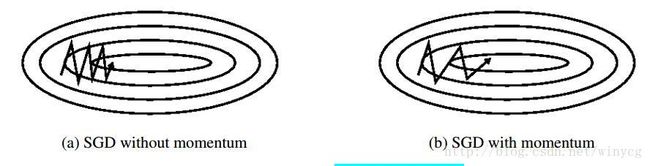
momentum能帮助加速SGD在确定方向的下降并且抑制震荡。
超参数 γ γ 一般设为0.9左右,意味着参数更新方向不仅由当前梯度决定,也与此前累计的下降方向有关,这使得momentum会增加更新某个维度下降方向不变的梯度,减少更新某个维度下降方向改变的梯度。因此获得了更快的收敛性和减少了震荡。
5.SGD with Nesterov accelerated gradient
小球在从山坡上下落时盲目地加速,如果能具备先知,在下一个上坡前减少,将会适应性更好。即算法能够在loss函数有增高趋势之前,减速更新速率。
NAG通过使用momentum关系实现这种先知。计算 θ−γvt−1 θ − γ v t − 1 为参数下一个大约的位置,计算梯度时,计算的是未来的值不是现在值。
在SGD-M的基础上有如下公式:

蓝线是SGD-momentum过程,先计算当前梯度(小蓝线),在更新的累计梯度方向上有一个大的跳跃(大蓝线)。
NAG首先在之前累计梯度方向上有大的跳跃到达下一时刻参数的近似位置(棕线),根据未来位置计算梯度(红向量),衡量梯度并做修正(绿线)。这种预期的更新可以避免走得过快,提前调整速率。NAG在RNN的多任务上有更好表现。
现在可以根据loss函数斜率适应更新并且加速SGD训练。我们还希望根据不同参数的重要性进行不同程度的更新。
自适应优化算法
1.AdaGrad
针对SGD及Momentum存在的问题,2011年John Duchi等发布了AdaGrad(Adaptive Gradient,自适应梯度)优化算法,能够对每个不同参数调整不同的学习率,对频繁变化的参数以更小的步长进行更新,而稀疏的参数以更大的步长更新。对稀疏的数据表现很好,提高了SGD的鲁棒性。(典型例子:更新word embedding中的低频词,单次步长更大,多学习一些知识;多频词,步长较小,使得学习到的参数更稳定,不至于单个样本影响太多)
在AdaGrad中,参数会根据之前的梯度修改学习率,引入二阶动量:
vt∈Rd×d v t ∈ R d × d 是对角矩阵,其对角元素 (i,i) ( i , i ) 为参数 θi θ i 从初始步到第 t t 步的梯度平方和,即 vt,ii=∑tj=1g2j,i v t , i i = ∑ j = 1 t g j , i 2 。与SGD相比,此时学习率等效为 η/vt+ϵ−−−−−√ η / v t + ϵ ,多加了梯度平方累计和的平方根,使得频繁更新的梯度,则累计的分母项逐渐变大,则更新的步长变小;稀疏的梯度,更新的步长会变大。
优点:能够为不同参数应不同的学习率,大多数学习率使用0.01为默认值可实现较好的效果。
缺点:分母项对梯度平方进行不断的累加,分母项越来越大,最终学习率收缩到无穷小使得无法进行有效更新。
2.Adadelta/RMSProp
为了解决AdaGrad单调递减的学习率急速下降的问题,考虑一个改变二阶动量计算方法的策略:不累积全部梯度,而只关注过去一段时间窗口的下降梯度,这就是delta中的来历。
采用计算梯度的指数移动平均数(Exponential Moving Average)
这样可以避免二阶动量持续累积,导致训练过程提前结束的问题, γ γ 通常取0.9,学习率为0.001
3.Adam
可以认为是RMSprop和Momentum的结合。对一阶动量和二阶动量都采用指数移动平均计算。
β1 β 1 默认为0.9, β2 β 2 默认为0,999。初始值为 m0=0,v0=0 m 0 = 0 , v 0 = 0
在迭代初始阶段, mt m t 和 vt v t 有一个向初值的偏移(过多偏向0),因此需要对一阶和二阶动量进行偏置校正(bias correction)
迭代式为:
实践证明,Adam比其他适应性学习方法要好
4.NAdam
在Adam上融入了NAG思想。NAG核心在于计算梯度时使用了未来位置 θt−γmt−1 θ t − γ m t − 1 。NAdam提出一种公式变形思路:在计算梯度时,可以仍然使用原始公式 gt=∇θJ(θt) g t = ∇ θ J ( θ t ) ,但在前一次迭代计算 θt θ t 时,就使用了未来时刻动量,即 θt=θt−1−mt θ t = θ t − 1 − m t ,理论上达到的效果类似。
此时公式为:
理论上, mt+1=γmt+ηgt+1 m t + 1 = γ m t + η g t + 1 ,在假定梯度连续变化不大的情况下,即 gt+1≈gt g t + 1 ≈ g t , mt+1≈γmt+ηgt=mt¯ m t + 1 ≈ γ m t + η g t = m t ¯ ,此时,即可用 mt¯ m t ¯ 近似表示未来动量。
在Adam中,将 mt^ m t ^ 展开有
在NAdam中,
优化器的选择
优化器在等高线和鞍点的表现:

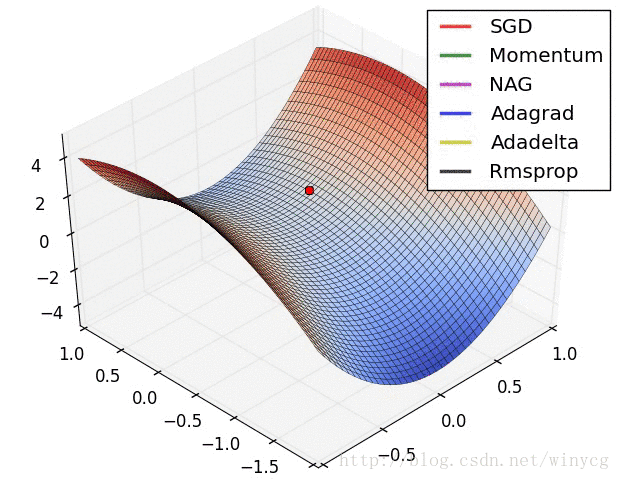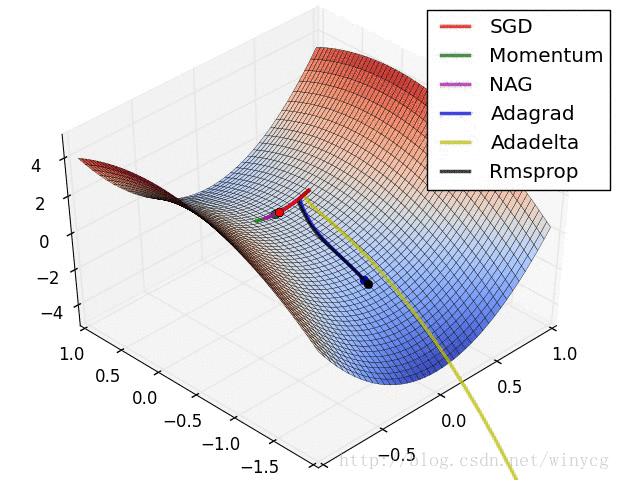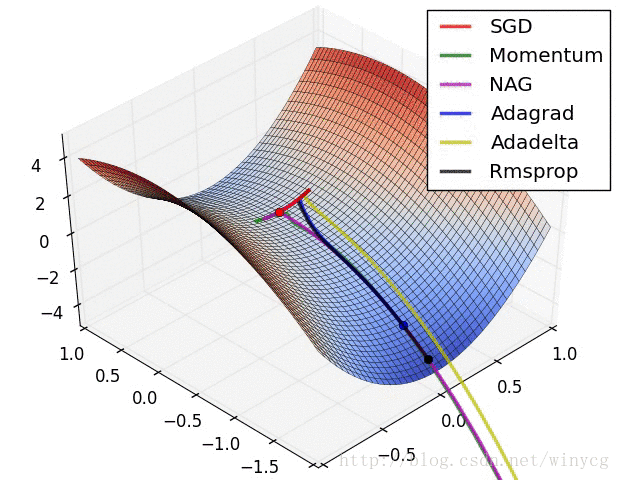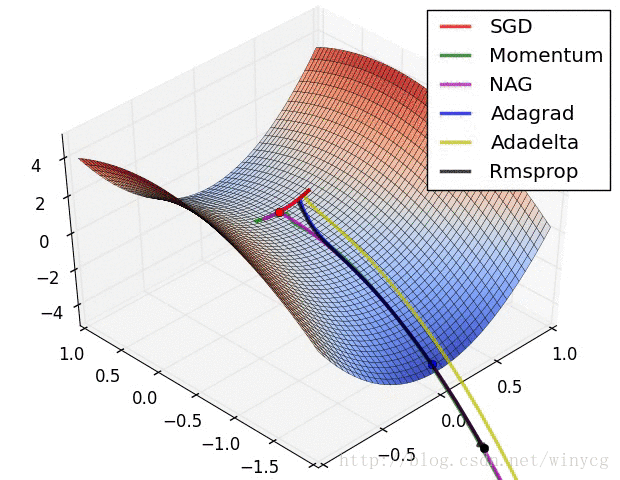
(1)如果数据是稀疏的,使用自适应学习方法。
(2)RMSprop,Adadelta,Adam是非常相似的优化算法,Adam的bias-correction帮助其在最后优化期间梯度变稀疏的情况下略微战胜了RMSprop。整体来讲,Adam是最好的选择。
(3)很多论文中使用vanilla SGD without momentum。SGD通常能找到最小值,但是依赖健壮的初始化,并且容易陷入鞍点。因此,如果要获得更快的收敛速度和训练更深更复杂的神经网络,需要选择自适应学习方法。