Pytorch中的backward
原文:https://sherlockliao.github.io/2017/07/10/backward/
接触了PyTorch这么长的时间,也玩了很多PyTorch的骚操作,都特别简单直观地实现了,但是有一个网络训练过程中的操作之前一直没有仔细去考虑过,那就是loss.backward(),看到这个大家一定都很熟悉,loss是网络的损失函数,是一个标量,你可能会说这不就是反向传播吗,有什么好讲的。
但是不知道大家思考过没有,如果loss不是一个标量,而是一个向量,那么loss.backward()是什么结果呢?
大家可以去试试,写一个简单的小程序
import torch as t
from torch.autograd import Variable as v
x = v(t.ones(2, 2), requires_grad=True)
y = x + 1
y.backward()运行一下程序,恭喜你报错了,错误显示如下
![]()
我们来读一读这个错误是什么意思。backward只能被应用在一个标量上,也就是一个一维tensor,或者传入跟变量相关的梯度。
嗯,前面一句话很简单,backward应用在一个标量,平时我们也是这么使用的,但是后面一句话,with gradient w.r.t variable是什么鬼,传入一个变量相关的梯度。不理解啊不理解,看不懂没关系我们还可以做实验来解决这个问题,俗话说自己动手丰衣足食(我也想做个伸手党去看看别人写的,然后不幸地是并没有什么人写过这方面的东西)。
首先我们开始做一个简单的实验,就是复习一下标量的形式
# simple gradient
a = v(t.FloatTensor([2, 3]), requires_grad=True)
b = a + 3
c = b * b * 3
out = c.mean()
out.backward()
print('*'*10)
print('=====simple gradient======')
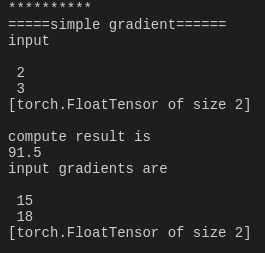
print('input')
print(a.data)
print('compute result is')
print(out.data[0])
print('input gradients are')
print(a.grad.data)很简单,我们把数学表达式写出来,传入的参数x1=2,x2=3,特别注意Variable里面默认的参数requires_grad=False,所以这里我们要重新传入requires_grad=True让它成为一个叶子节点。
a=(x1,x2)b=(x1+3,x2+3)c=(3∗(x1+3)2,3∗(x2+3)2)
out=3∗((x1+3)2+(x2+3)2)2
那么我们对其求偏导也很简单
∂out∂x1=3(x1+3)|x1=2=15∂out∂x2=3(x2+3)|x2=3=18
这样依靠简单的微积分知识我们就能够算出他们的结果,运行一下程序,确保结果一致,ok。
下面我们研究一下如何能够对非标量的情况下使用backward,下面开始做实验(瞎试)。
m = v(t.FloatTensor([[2, 3]]), requires_grad=True)
n = v(t.zeros(1, 2))
n[0, 0] = m[0, 0] ** 2
n[0, 1] = m[0, 1] ** 3首先我们定义好输入 m=(x1,x2)=(2,3) ,然后我们做的操作就是 n=(x21,x32) ,这样我们就定义好了一个向量输出,结果第一项只和x1有关,结果第二项只和x2有关,那么求解这个梯度,我们知道 ∂n1∂x1=2x1=4,∂n2∂x2=3x22=27 ,下面我们开始探究如何能够让他调用backward。
第一想法就是里面这个参数是要求梯度的对象,我们这样调用n.backward(m.data),有有报错诶,是不是成功了,我真的是个天才,这么难的东西都能想到,等等,我好想看到了一个很神奇的结果。
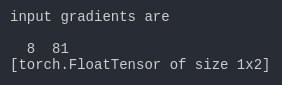
这是什么鬼,这跟说好的结果不一样啊,我们想要的结果是4和27,现在给我们的结果是8和81,为什么会出现这样神奇的结果呢,想不通啊。我们看看我们传入的参数是m.data,这是一个(2, 3)的向量,我们希望得到的梯度是(4, 27),好像(4x2=8, 27x3=81),我的内心毫无波动,甚至有点想笑,似乎backward将我传入的参数m.data乘上了得到的梯度,既然要乘上我传入的参数,那么我就给你传入1,这样总能得到我想要的结果了吧,n.backward(t.FloatTensor([[1, 1]])),看看结果呢
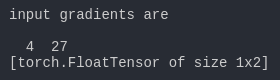
哇,跟我们想要的结果一样诶,撒花,我们解决了一个大问题,就是这么简单,扔进去一个1就可以了,这个问题也没有那么难嘛,哈哈哈。
似乎又有一点不对,如果这么简单那么写PyTorch的人为什么不把这一步直接集成进去,那我们不就不会遇到这个问题了嘛。
我们来试试另外一种情况
m = v(t.FloatTensor([[2, 3]]), requires_grad=True)
j = t.zeros(2 ,2)
k = v(t.zeros(1, 2))
m.grad.data.zero_()
k[0, 0] = m[0, 0] ** 2 + 3 * m[0 ,1]
k[0, 1] = m[0, 1] ** 2 + 2 * m[0, 0]上面的代码写成数学表达式就是 m=(x1=2,x2=3),k=(x21+3x2,x22+2x1)) ,么我们直接对k反向传播k.backward(t.FloatTensor([[1, 1]]),结果是什么呢?
首先我们手动算一算结果是什么。 ∂(x21+3x2)∂x1=2x1=4, ∂(x21+3x2)∂x2=3, ∂(x22+2x1)∂x1=2, ∂(x22+2x1)∂x2=2x2=6 ,我们是希望能够得到上面四个结果,这个时候你可能已经开始怀疑了,能够得到这4个结果吗?我们可以输出结果来看看

非常遗憾,我们只得到了两个结果,并且数值并不对,这个时候你就会疑惑了,到底是哪里出了问题呢,为什么会得到这样的结果呢?
经过不断地尝试,我终于发现了其中的奥秘,k.backward(parameters)接受的参数parameters必须要和k的大小一模一样,然后作为k的系数传回去,什么意思呢,我们通过上面的例子来解释这个问题你就知道了。
我们已经知道我们得到的 k=(k1,k2) ,以及传入的参数是1和1,那么是如何得到这6和9这两个结果的呢?
其实第一个结果是通过 1×dk1dx1+1×dk2dx1=2x1+2=6 这样得到的,是不是有点理解这个操作是怎么完成的了,我们再来看看第二个结果, 1×dk1dx2+1×dk2dx2=3+2x2=9 ,这样我们就得到了这两个结果,原来我们传入的参数是每次求导的一个系数。
我们知道了这个操作具体是怎么完成的,我们就可以求求我们需要的这个jacobian矩阵了,非常简单。
# jacobian
j = t.zeros(2 ,2)
k = v(t.zeros(1, 2))
m.grad.data.zero_()
k[0, 0] = m[0, 0] ** 2 + 3 * m[0 ,1]
k[0, 1] = m[0, 1] ** 2 + 2 * m[0, 0]
k.backward(t.FloatTensor([[1, 0]]), retain_variables=True)
j[:, 0] = m.grad.data
m.grad.data.zero_()
k.backward(t.FloatTensor([[0, 1]]))
j[:, 1] = m.grad.data
print('jacobian matrix is')
print(j)我们可以得到如下结果
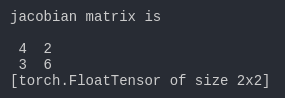
这里我们要注意backward()里面另外的一个参数retain_variables=True,这个参数默认是False,也就是反向传播之后这个计算图的内存会被释放,这样就没办法进行第二次反向传播了,所以我们需要设置为True,因为这里我们需要进行两次反向传播求得jacobian矩阵。
最后我们再举一个矩阵乘法的例子试验一下我们的结果
x = t.FloatTensor([2, 1]).view(1, 2)
x = v(x, requires_grad=True)
y = v(t.FloatTensor([[1, 2], [3, 4]]))
z = t.mm(x, y)
jacobian = t.zeros((2, 2))
z.backward(t.FloatTensor([[1, 0]]), retain_variables=True) # dz1/dx1, dz2/dx1
jacobian[:, 0] = x.grad.data
x.grad.data.zero_()
z.backward(t.FloatTensor([[0, 1]])) # dz1/dx2, dz2/dx2
jacobian[:, 1] = x.grad.data
print('=========jacobian========')
print('x')
print(x.data)
print('y')
print(y.data)
print('compute result')
print(z.data)
print('jacobian matrix is')
print(jacobian)上面是代码,仔细阅读,作为一个小练习回顾一下本篇文章讲的内容,妈妈再也不用担心我不会用backward了。