TF2.0深度学习实战(七):手撕深度残差网络ResNet
写在前面:大家好!我是【AI 菌】,一枚爱弹吉他的程序员。我
热爱AI、热爱分享、热爱开源! 这博客是我对学习的一点总结与记录。如果您也对深度学习、机器视觉、算法、Python、C++感兴趣,可以关注我的动态,我们一起学习,一起进步~
我的博客地址为:【AI 菌】的博客
我的Github项目地址是:【AI 菌】的Github
本教程会持续更新,如果对您有帮助的话,欢迎star收藏~
前言:
本专栏将分享我从零开始搭建神经网络的学习过程,注重理论与实战相结合,力争打造最易上手的小白教程。在这过程中,我将使用谷歌TensorFlow2.0框架逐一复现经典的卷积神经网络:LeNet、AlexNet、VGG系列、GooLeNet、ResNet 系列、DenseNet 系列,以及现在比较流行的:RCNN系列、SSD、YOLO系列等。
这一次我将复现非常经典的深度残差网络ResNet。首先在理论部分,我会依据论文对ResNet进行一个简要的讲解。然后在实战部分,我会手把手带你搭建第一个深度残差网络ResNet-18,对CIFAR10数据集进行训练与分类预测。
系列教程:
实战教程:《TF2.0深度学习实战:图像分类/目标检测》
理论教程:《深度学习笔记》
资源传送门:
论文地址:《Deep Residual Learning for Image Recognition》
论文详解:ResNet论文详解:《Deep Residual Learning for Image Recognition》
github项目地址:【AI 菌】的Github
文章目录
- 一、ResNet详解
- 1.1 ResNet简介
- 1.2 提出背景
- 1.3 ResNet创新之处
- 1.4 ResNet网络结构
- (1) 捷径连接
- (2) 更深的瓶颈结构
- (3) 残差模块中虚实线的区别
- (4) 整体结构
- 1.5 ResNet的性能
- 二、TensorFlow2.0搭建ResNet实战
- 2.1 数据集准备
- (1) 数据集介绍
- (2) 数据集加载与准备
- 2.2 搭建ResNet网络模型
- (1) 搭建残差模块
- (2) 搭建整体网络结构
- 2.3 模型装配与训练
- 2.4 训练过程与结果
一、ResNet详解
1.1 ResNet简介
ResNet来源于《Deep Residual Learning for Image Recognition》这篇论文,在2015年,由微软亚洲研究院的何凯明等人共同发表。其研究成果在ILSVRC 2015挑战赛ImageNet数据集上获得分类任务和检测任务双冠军。ResNet论文至今已经获得超 25000 的引用量,可见 ResNet 在人工智能领域的影响力。
我们常说的ResNet是一种基于跳跃连接的深度残差网络算法。根据该算法提出了18 层、34层、50 层、101 层、152 层的 ResNet-18,ResNet-34,ResNet-50,ResNet-101 和 ResNet-152 等模型,甚至成功训练出层数达到1202层的超深的神经网络。
1.2 提出背景
前面我们学过AlexNet,VGG,GoogLeNet 等网络模型,它们的出现将神经网络的发展带入了二十几层的阶段。研究人员发现网络的层数越深,理想情况下,网络模型的学习效果越好。但是实际中,单纯地增加网络的深度,网络会变得越来越难训练,而且精度会达到饱和。这主要是由于两种问题造成的:(1)梯度弥散/爆炸现象、(2)退化问题。
如下图所示,左图为20层和56层的普通网路在CIFAR-10数据集上的训练误差率;右图是测试误差率。

从图中很容易看出,50层网络最终的训练误差率和测试误差率均比20层的高。可见,随着网络深度的增加,精度到达饱和,甚至会导致更高的训练和测试误差率,这就是论文中提到的退化问题。而这种退化问题又不是由过拟合引起的,因为不仅验证集上的误差在增大,就连训练集上的误差也在增大。(过拟合一般会在训练集上表现良好,但由于泛化能力差,所以在验证和测试上表现差)
论文中提到,梯度弥散/爆炸现象可由在网络中添加BN(Batch Normalization)层或者通过数据的预处理来解决,使得训练速度加快。但是针对退化问题,还没有一个完美的解决方案。于是,何凯明等人就提出了本文的深度残差网络算法ResNet,来解决因为网络深度剧增而产生的退化问题。
1.3 ResNet创新之处
- 提出了超深的网络结构。最高成功训练了1202层的超深残差网络。
- 提出了两种残差模块(Residual)。也就是我们下文将要提到的两种结构:捷径连接、更深的瓶颈结构。
- 使用BN层解决了梯度弥散/爆炸,加速了网络的训练。由于添加了BN层,所以在卷积运算过程中,不用再加入偏置bias了。
- 由于没有明显产生过拟合,所以残差网络中没有再使用dropout了。
如果对BN层、过拟合、dropout等概念还不太了解,可以先加个餐:深度学习理论系列
1.4 ResNet网络结构
为了大家更清楚地了解ResNet网络结构,我分以下四个部分依次讲解:
- 捷径连接(Shortcut Connections)
- 更深的瓶颈结构(Deeper Bottleneck Architectures)
- 残差模块中虚实线的区别
- 整体结构
(1) 捷径连接
捷径连接(Shortcut Connections)是构建ResNet的一个主要方法,用来恒等映射和跳层连接。示下图所示,是构建ResNet的一个残差模块(Residual):

其中,x表示的是输入的特征矩阵;网络主路的输出 F ( x ) F(x) F(x)是残差函数;网络的支路就是我们所说的捷径连接(Shortcut Connection),其中x identity表示的是恒等映射,也就是:直接将输入的特征矩阵x本身跳层传递到输出。
那么,直接将主路和支路输出相加得: H ( x ) = F ( x ) + x H(x)=F(x)+x H(x)=F(x)+x
最后,再经过ReLU函数经行激活,得到残差模块的输出: y = R e L U ( F ( W i , x ) + x ) y=ReLU(F(W_i, x)+x) y=ReLU(F(Wi,x)+x),其中 W i W_i Wi表示的是主路卷积层的参数。
由于,恒等映射x identity并不增加额外的参数;所以在反向传播传播过程中,主要更新学习的是主路 F ( x ) F(x) F(x)中的参数,即要学习的是: F ( x ) = H ( x ) − x F(x)=H(x)-x F(x)=H(x)−x。其中, F ( x ) F(x) F(x)是 H ( x ) H(x) H(x)与x的残差,残差网络ResNet的名字由此而来。
(2) 更深的瓶颈结构
在ResNet系列网络中,提出了两种主要的残差模块(Residual)。一种是如下图(左)所示的,应对较低深度的ResNet18、ResNet34,这就是上节讲到的捷径连接;还有一种是下图(右)所示的,应对层数很深的ResNet50、ResNet101、ResNet152等,这就是这节要讲的更深的瓶颈结构。

- 那么,这两个残差模块有什么不同呢?
从结构上很明显看的出来。更深的瓶颈结构,在3×3的卷积核层前后分别加入了一个1×1的卷积核层,进行降维和升维。使得网络的深度增加,而参数量反而大大减少,有助于网络的训练。关于1×1卷积核的降维细节,我在上一篇博客中详细讲到了,想了解的请戳:TF2.0深度学习实战(六):搭建GoogLeNet卷积神经网络 - 那么,为什么称右边的这种残差模块为瓶颈结构(BottleNeck)?
这里我们假设输入的特征矩阵x的shape为(56,56,256),其中56×56为特征图的size,256表示通道数(维度)。那么x经过第一层[1×1,64]的卷积层降维后,shape变为(56,56,64);再经过中间层[3×3,64]的卷积层卷积后,shape变为(56,56,64);最后再经过第三层的[1×1,256]的卷积层升为后,shape变为(56,56,256)。由此可见,在这过程中,特征矩阵的size:56×56并不改变,改变的只是特征矩阵的通道数(维度)。并且维度的变化过程是:256—>64—>64—>256,呈一个上下维度高,中间低的形状,像瓶子的颈部一样,因此将此命名为瓶颈结构。其实我们也可以将它简单理解为:带有降维和升维功能的残差模块。
(3) 残差模块中虚实线的区别
在原论文中的完整ResNet结构中,我们可以看见带实现和虚线的两种不同的残差模块。如下图所示:

图中(左)采用的是实线连接的形式,表示的是不进行下采样,即输入和输出特征矩阵size一致的情况。图中(右)采用的是虚线连接的形式,表示要进行2倍的下采样。在主路网络中使用了步长为2的卷积层进行下采样,因此在支路Shortcut Connection中也要采取一种方式进行匹配尺寸,才能使得支路的输出特征矩阵和主路的直接相加。论文中对此提出了三种方法进行匹配尺寸,通过比较最后选择如图所示的方案B:在支路捷径连接中添加卷积核size为1×1、步长为2的卷积层进行下采样。
因此,这个时候残差模块的输出表达式为: y = R e L U ( F ( W i , x ) + W s x ) y=ReLU(F(W_i, x)+W_sx) y=ReLU(F(Wi,x)+Wsx),其中 W i W_i Wi表示的是主路卷积核中的参数, W s W_s Ws表示支路Shortcut Connection中的卷积层的参数。由于支路采用的是全是1×1的卷积核,因此参数量极少,相比于主路几乎可以忽略不计。
对于第二种残差模块(瓶颈结构)中的虚实线表示,和以上原理一样,这里就不再赘述了。
(4) 整体结构
我们都知道,网络训练过程中有两条主线:前向计算、反向传播更新参数。其实,在前向计算过程中,ResNet只是在普通的深度卷积网络上增加了几个捷径连接(Shortcut Connections)。并且捷径连接没有引入额外的参数量,也没有增加计算的复杂度。重要的是,捷径连接在反向传播过程中发挥了巨大的作用!
前面提到,在前向计算过程中,输入特征矩阵x会经过主路 F ( x ) F(x) F(x)和支路恒等映射x。那么在反向传播过程中,也会经过这两条路进行反向传播。如果当网络很深时,梯度弥散,使得深层的网络难以训练下去,这时通过捷径连接可以跳过中间的某几层,对更深的网络层进行训练。理想情况下,ResNet会跳过训练好的层,对原本很难训练到的很深的层进行训练。
如下表所示,给出了不通过层数的残差网络ResNet的体系结构:

其中,conv2_x,conv3_x,conv4_x,conv5_x表示的是残差块,每一个残差块包含几个相同残差模块(Residual)。由上表可知,比如ResNet34的conv2_x里面就有3个相同的残差模块。
下图表示的是ResNet34的整体网络结构,其中用不同颜色的方框将残差块分别标注了出来,如下图所示:

ResNet34整体结构分析:
- 网络输入:224×224×3的彩色图像
- 第一层:卷积核size为7×7,个数为64,步长为2的卷积层;然后再经过卷积核size3×3,步长为2的最大池化层。
- 中间层:由多个残差块:conv2_x,conv3_x,conv4_x,conv5_x 依次连接而成。
- 最终层:先经过全局平均池化层转为特征向量,再经过节点数为1000的全连接层,最后通过Softmax函数转化为概率输出,实现1000分类。
由于整体结构图太长,为了方便看,我是横着放的。如果想要查看原图,请戳这里:
ResNet论文详解:《Deep Residual Learning for Image Recognition》
1.5 ResNet的性能
对于ResNet的性能究竟如何,我们先看下面这张图,直观感受一下:

上图左边表示的是,普通的18层和34层网络在ImageNet数据集上的表现。右边是加入了残差模块后的ResNet18和ResNet34的表现。粗曲线表示的是验证误差率,细曲线是训练误差率。
对于普通网络,34层网络的误差率比18层的还高,可见深度增加,产生了退化问题。
而右边引入了残差模块的网络,ResNet34比ResNet18的误差率明显降低了不少。可见残差模块具有实际的作用,消除了网络太深造成的退化问题,从而降低了误差率。
从数据上看,ResNet的性能优点主要表现为:
- 在ImageNet测试集上实现了3.57%的Top-5误差率,从而获得了2015年ILSVRC挑战赛分类任务的冠军。

- ResNet比普通的卷积神经网络计算复杂度更低。
对于19层的VGG-19,需要运算196亿个FLOP。而对于34层的ResNet-34,只需运算36亿个FLOP。可见,更深的ResNet-34的计算复杂度仅占VGG-19的18%左右,计算复杂度大大降低!
除此之外,ResNet的检测性能也很好,这里就不具体展开了。想要详细了解的同学,可以看我的这篇博文:ResNet论文详解:《Deep Residual Learning for Image Recognition》
二、TensorFlow2.0搭建ResNet实战
2.1 数据集准备
(1) 数据集介绍
本次我们采用的是一个经典的图片分类数据集:CIFAR100。CIFAR10 数据集由加拿大 Canadian Institute For Advanced Research 发布,它包含了飞机、汽车、鸟、猫等共 100 大类物体的彩色图片,共 6万 张图片。其中 5万 作为训练数据集,1万作为测试数据集。种类样片如下图所示:

(2) 数据集加载与准备
在tensorflow2.0官方API中提供了自动加载CIFAR10 数据集的函数,我们直接使用即可。
# 数据集加载与准备
(x,y), (x_test, y_test) = datasets.cifar100.load_data()
y = tf.squeeze(y, axis=1)
y_test = tf.squeeze(y_test, axis=1)
print(x.shape, y.shape, x_test.shape, y_test.shape)
# 训练集
train_db = tf.data.Dataset.from_tensor_slices((x,y))
train_db = train_db.shuffle(50000).map(preprocess).batch(128)
# 测试集
test_db = tf.data.Dataset.from_tensor_slices((x_test,y_test))
test_db = test_db.map(preprocess).batch(128)
2.2 搭建ResNet网络模型
(1) 搭建残差模块
由于这里我们搭建的是ResNet18,所以使用的是第一种残差模块。
class BasicBlock(layers.Layer):
def __init__(self, filter_num, stride=1):
super(BasicBlock, self).__init__()
self.conv1 = layers.Conv2D(filter_num, (3, 3), strides=stride, padding='same')
self.bn1 = layers.BatchNormalization() # BN层
self.relu = layers.Activation('relu') # ReLU激活函数
self.conv2 = layers.Conv2D(filter_num, (3, 3), strides=1, padding='same')
self.bn2 = layers.BatchNormalization() # BN层
if stride != 1:
self.downsample = Sequential() # 下采样
self.downsample.add(layers.Conv2D(filter_num, (1, 1), strides=stride))
else:
self.downsample = lambda x:x # 恒等映射
def call(self, inputs, training=None):
out = self.conv1(inputs)
out = self.bn1(out,training=training)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out,training=training)
identity = self.downsample(inputs) # 恒等映射
output = layers.add([out, identity]) # 主路与支路(恒等映射)相加
output = tf.nn.relu(output) # ReLU激活函数
return output
(2) 搭建整体网络结构
依据上面给出的ResNet的体系结构表,我们可以先搭建出残差块函数(将几个相同的残差模块堆叠在一起)。然后再搭建整体结构,这样代码就会简化很多。
class ResNet(keras.Model):
def __init__(self, layer_dims, num_classes=100):
super(ResNet, self).__init__()
# 第一层
self.stem = Sequential([layers.Conv2D(64, (3, 3), strides=(1, 1)),
layers.BatchNormalization(),
layers.Activation('relu'),
layers.MaxPool2D(pool_size=(2, 2), strides=(1, 1), padding='same')
])
# 中间层的四个残差块:conv2_x,conv3_x,conv4_x,conv5_x
self.layer1 = self.build_resblock(64, layer_dims[0])
self.layer2 = self.build_resblock(128, layer_dims[1], stride=2)
self.layer3 = self.build_resblock(256, layer_dims[2], stride=2)
self.layer4 = self.build_resblock(512, layer_dims[3], stride=2)
# 全局平均池化
self.avgpool = layers.GlobalAveragePooling2D()
# 全连接层
self.fc = layers.Dense(num_classes)
def call(self, inputs, training=None):
x = self.stem(inputs,training=training)
x = self.layer1(x,training=training)
x = self.layer2(x,training=training)
x = self.layer3(x,training=training)
x = self.layer4(x,training=training)
x = self.avgpool(x)
x = self.fc(x)
return x
# 构建残差块(将几个相同的残差模块堆叠在一起)
def build_resblock(self, filter_num, blocks, stride=1):
res_blocks = Sequential()
# 可能会进行下采样
res_blocks.add(BasicBlock(filter_num, stride))
for _ in range(1, blocks):
res_blocks.add(BasicBlock(filter_num, stride=1))
return res_blocks
2.3 模型装配与训练
在模型装配过程中,采用的是Adam优化器,categorical_crossentropy交叉熵损失函数,以及accuracy测试精确度。训练过程中,每20轮打印一次loss损失值,每训练完1个epoch打印一次精确度accuracy,一共训练100个epochs。
部分代码如下:
def main():
for epoch in range(50):
for step, (x,y) in enumerate(train_db):
with tf.GradientTape() as tape:
logits = model(x,training=True) # [b, 32, 32, 3] => [b, 100]
y_onehot = tf.one_hot(y, depth=100) # 热独编码
# 计算损失
loss = tf.losses.categorical_crossentropy(y_onehot, logits, from_logits=True)
loss = tf.reduce_mean(loss)
grads = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
# 每20轮打印一次loss值
if step % 20 == 0:
print('第', epoch+1, '个epoch中,第', step+1, '个step的损失:loss =', float(loss))
2.4 训练过程与结果
我们先打印出模型的每层的参数信息,可见整个网络总的参数量大约有1100万个,如下图所示:

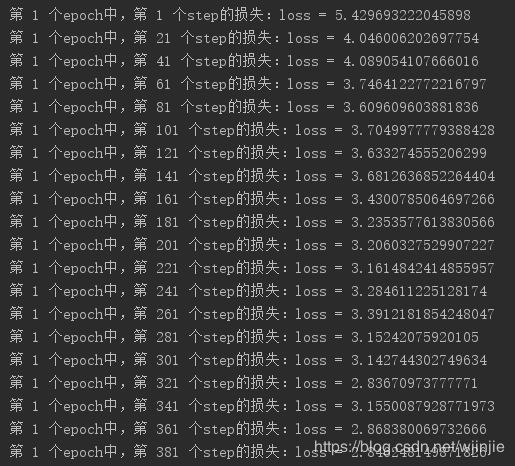
由于时间有限,这里我只训练了381个steps。我们可以看到损失值loss一直在减小,可见此时网路模型的训练是收敛的,继续训练下去,可以达到更小的损失值,同时测试精确度也会更高。大家有时间可以多花点时间训练,达到更好的效果。
本次教程就到这里啦,代码已上传Github。想实战的盆友,可以戳戳我的github项目地址:【AI 菌】的Github
温馨提示:我将用迁移学习的方法,训练深度残差网络ResNet-101,实现图像分类与预测。有兴趣的同学可以关注我的动态哦~
最后就要和大家说再见啦!如果这篇文章对您有帮助的话,请点个赞支持一下呗,谢谢!