Python与自然语言处理——词性标注与命名实体识别(一)
Python与自然语言处理——词性标注与命名实体识别
- 词性标注与命名实体识别(一)
- 词性标注
- 词性标注简介
- 词性标注规范
- Jieba的词性标注
- 命名实体识别(NER)
- 命名实体识别简介
- 基于随机条件场的命名实体识别
- 日期识别
- 完整代码
- 参考文献
词性标注与命名实体识别(一)
词性标注
词性标注简介
- 词性标注是在给定句子中判定每个词的语法范畴,确定其词性并标注的过程。
- 中文特点:
- 一个词的词性是不固定的
- 但从整体上看,一个词常用的只有1、2种词性(特别是实词)
词性标注规范
词性标注一般需要一定的标注规范,如将词分为名词、形容词、动词等。中文领域尚无统一标准,常用的包括:
- 北大的词性标注集
- 宾州词性标注集
这里我们使用北大词性标注集:
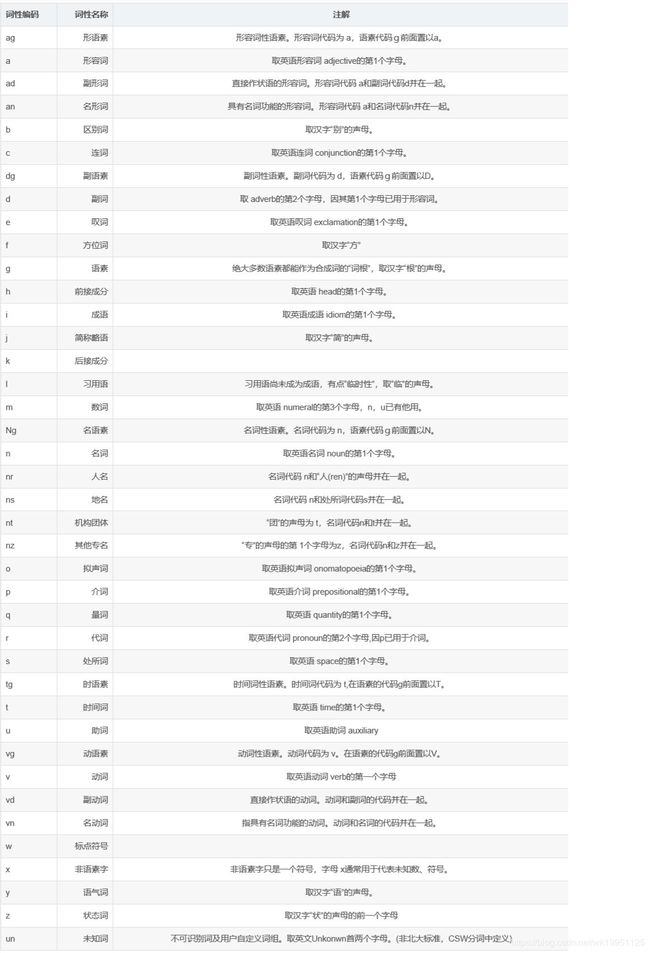
Jieba的词性标注
- 标注流程如下
- 首先通过正则表达式判断是否为汉字,若符合表达式则判定为汉字
re_han_internal=re.compile("[\u4E00-\u9FD5a-zA-Z0-9+#&\._]+)")- 然后基于前缀词典构建有向无环图,进一步计算最大概率路径,同时在前缀词典中找出它所分出的词性,若未找到则设置为“未知”
- 若是汉字则根据正则表达式继续匹配,赋予“未知”、“数字”和“英语”。
- 代码示例
######词性标注######
import jieba.posseg as psg
sent="中文分词是文本处理不可或缺的一步!"
seg_list=psg.cut(sent)
print(' '.join(['{0}/{1}'.format(w,t) for w,t in seg_list]))
- 显示结果
中文/nz 分词/n 是/v 文本处理/n 不可或缺/l 的/uj 一步/m !/x
命名实体识别(NER)
命名实体识别简介
- 目标:识别语料中的人名、地名、组织机构名等命名实体。
- 命名实体
- 三大类:实体类、时间类以及数字类
- 七小类:人名、地名、组织机构名、时间、日期、货币和百分比
- 还存在的问题
- 只在有限的文本类型和实体类型取得了效果
- 实体命名评测语料较小,容易过拟合
- 更侧重高召回率
- 通用的识别多种类型的命名实体系统性差
- 中文命名实体识别的主要难点
- 各类命名实体的数量众多
- 命名实体的构成规律复杂
- 嵌套情况复杂
- 长度不确定
- 主要方法
- 基于规则
- 基于统计
- 混合方法
基于随机条件场的命名实体识别
- 随机条件场的定义
设 X = ( X 1 , X 2 , ⋯ , X n ) X = \left( {{X_1},{X_2}, \cdots ,{X_n}} \right) X=(X1,X2,⋯,Xn)和 Y = ( Y 1 , Y 2 , ⋯ , Y m ) Y = \left( {{Y_1},{Y_2}, \cdots ,{Y_m}} \right) Y=(Y1,Y2,⋯,Ym)是联合随机变量,若随机变量 Y Y Y构成一个无向图 G = ( V , E ) G = \left( {V,E} \right) G=(V,E)表示的马尔可夫模型,则其条件概率分布 P ( Y ∣ X ) P\left( {Y\left| X \right.} \right) P(Y∣X)称为条件随机场(CRF),即
P ( Y v ∣ X , Y w , w ≠ v ) = P ( Y v ∣ X , Y w , w ∼ v ) P\left( {{Y_v}\left| {X,{Y_w},w \ne v} \right.} \right) = P\left( {{Y_v}\left| X \right.,{Y_w},w \sim v} \right) P(Yv∣X,Yw,w̸=v)=P(Yv∣X,Yw,w∼v)
其中 w ∼ v w\sim v w∼v表示图 G = ( V , E ) G = \left( {V,E} \right) G=(V,E)中与结点 v v v有连接的所有点, w ≠ v w\ne v w̸=v表示除了 v v v以外的所有点。 - 线性链条件随机场定义
设 X = ( X 1 , X 2 , ⋯ , X n ) X = \left( {{X_1},{X_2}, \cdots ,{X_n}} \right) X=(X1,X2,⋯,Xn)和 Y = ( Y 1 , Y 2 , ⋯ , Y n ) Y = \left( {{Y_1},{Y_2}, \cdots ,{Y_n}} \right) Y=(Y1,Y2,⋯,Yn)均为线性链表示的随机变量序列,若在给定的随机变量序列 X X X的条件下,随机变量序列 Y Y Y的条件概率分布 P ( Y ∣ X ) P\left( {Y\left| X \right.} \right) P(Y∣X)构成条件随机场,且满足马尔可夫性:
P ( Y i ∣ X , Y 1 , Y 2 , ⋯ , Y n ) = P ( Y i ∣ X , Y i − 1 , Y i + 1 ) P\left( {{Y_i}\left| {X,{Y_1},{Y_2}, \cdots ,{Y_n}} \right.} \right) = P\left( {{Y_i}\left| {X,{Y_{i - 1}},{Y_{i + 1}}} \right.} \right) P(Yi∣X,Y1,Y2,⋯,Yn)=P(Yi∣X,Yi−1,Yi+1)
则称 P ( Y ∣ X ) P\left( {Y\left| X \right.} \right) P(Y∣X)为线性链的条件随机场。 - 线性链CRF的参数化形式
P ( y ∣ x ) = 1 Z ( x ) exp ( ∑ i , k λ k t k ( y i − 1 , y i , i ) + ∑ i , l μ l s l ( y i , X , i ) ) P\left( {y\left| x \right.} \right) = \frac{1}{{Z\left( x \right)}}\exp \left( {\sum\nolimits_{i,k} {{\lambda _k}{t_k}\left( {{y_{i - 1}},{y_i},i} \right) + \sum\nolimits_{i,l} {{\mu _l}{s_l}\left( {{y_i},X,i} \right)} } } \right) P(y∣x)=Z(x)1exp(∑i,kλktk(yi−1,yi,i)+∑i,lμlsl(yi,X,i))
其中 Z ( x ) = ∑ y exp ( ∑ i , k λ k t k ( y i − 1 , y i , i ) + ∑ i , l μ l s l ( y i , X , i ) ) Z\left( x \right) = \sum\nolimits_y {\exp \left( {\sum\nolimits_{i,k} {{\lambda _k}{t_k}\left( {{y_{i - 1}},{y_i},i} \right) + \sum\nolimits_{i,l} {{\mu _l}{s_l}\left( {{y_i},X,i} \right)} } } \right)} Z(x)=∑yexp(∑i,kλktk(yi−1,yi,i)+∑i,lμlsl(yi,X,i))为规范化因子,转移函数 t k ( y i − 1 , y i , i ) {t_k}\left( {{y_{i - 1}},{y_i},i} \right) tk(yi−1,yi,i)依赖于当前和前一个位置,状态函数 s l ( y i , X , i ) {s_l}\left( {{y_i},X,i} \right) sl(yi,X,i)依赖于当前概率,通常取值为 1 1 1和 0 0 0。
日期识别
- 代码实现
import re
from datetime import datetime,timedelta
from dateutil.parser import parse
import jieba.posseg as psg
UTIL_CN_NUM = {
'零': 0, '一': 1, '二': 2, '两': 2, '三': 3, '四': 4,
'五': 5, '六': 6, '七': 7, '八': 8, '九': 9,
'0': 0, '1': 1, '2': 2, '3': 3, '4': 4,
'5': 5, '6': 6, '7': 7, '8': 8, '9': 9
}
UTIL_CN_UNIT = {'十': 10, '百': 100, '千': 1000, '万': 10000}
#对句子进行解析,提取其中所有可能表示日期时间的词,并进行上下文拼接
def time_extract(text):
time_res=[]
word=''
keyDate={'今天':0,'明天':1,'后天':2}
for k,v in psg.cut(text):
if k in keyDate:
if word!='':
time_res.append(word)
word=(datetime.today()+timedelta(days=keyDate.get(k,0))).strftime('%Y年%m月%d日') #对日期进行转化为年月日的形式
elif word!='':
if v in ['m','t']: #如果word不为空且v为时间、数字标签
word=word+k
else:
time_res.append(word)
word=''
elif v in ['m','t']: #如果word为空且v为时间、数字标签
word=k
if word !='':
time_res.append(word)
result=list(filter(lambda x:x is not None, [check_time_valid(w) for w in time_res])) #对提取出的日期进行有效性判断
final_res=[parse_datetime(w) for w in result] #对文本日期串进行时间转换
return [x for x in final_res if x is not None]
#对获得的日期进行有效性判断
def check_time_valid(word):
m=re.match("%d+$",word)
if m:
if len(word)<=6:
return None
wordl=re.sub('[号|日]\d+$','日',word)
if wordl !=word:
return check_time_valid(wordl)
else:
return wordl
#对提取的文本日期串进行时间转换
def parse_datetime(msg):
if msg is None or len(msg) == 0:
return None
try:
dt = parse(msg, fuzzy=True)
return dt.strftime('%Y-%m-%d %H:%M:%S')
except Exception as e:
m = re.match(
r"([0-9零一二两三四五六七八九十]+年)?([0-9一二两三四五六七八九十]+月)?([0-9一二两三四五六七八九十]+[号日])?([上中下午晚早]+)?([0-9零一二两三四五六七八九十百]+[点:\.时])?([0-9零一二三四五六七八九十百]+分?)?([0-9零一二三四五六七八九十百]+秒)?",
msg)
if m.group(0) is not None:
res = {
"year": m.group(1),
"month": m.group(2),
"day": m.group(3),
"hour": m.group(5) if m.group(5) is not None else '00',
"minute": m.group(6) if m.group(6) is not None else '00',
"second": m.group(7) if m.group(7) is not None else '00',
}
params = {}
for name in res:
if res[name] is not None and len(res[name]) != 0:
tmp = None
if name == 'year':
tmp = year2dig(res[name][:-1])
else:
tmp = cn2dig(res[name][:-1])
if tmp is not None:
params[name] = int(tmp)
target_date = datetime.today().replace(**params)
is_pm = m.group(4)
if is_pm is not None:
if is_pm == u'下午' or is_pm == u'晚上' or is_pm =='中午':
hour = target_date.time().hour
if hour < 12:
target_date = target_date.replace(hour=hour + 12)
return target_date.strftime('%Y-%m-%d %H:%M:%S')
else:
return None
#文本转换数字
def cn2dig(src):
if src == "":
return None
m = re.match("\d+", src)
if m:
return int(m.group(0))
rsl = 0
unit = 1
for item in src[::-1]:
if item in UTIL_CN_UNIT.keys():
unit = UTIL_CN_UNIT[item]
elif item in UTIL_CN_NUM.keys():
num = UTIL_CN_NUM[item]
rsl += num * unit
else:
return None
if rsl < unit:
rsl += unit
return rsl
#文本转换数字
def year2dig(year):
res = ''
for item in year:
if item in UTIL_CN_NUM.keys():
res = res + str(UTIL_CN_NUM[item])
else:
res = res + item
m = re.match("\d+", res)
if m:
if len(m.group(0)) == 2:
return int(datetime.datetime.today().year/100)*100 + int(m.group(0))
else:
return int(m.group(0))
else:
return None
- 测试及结果
######测试######
text1 = '我要住到明天下午三点'
print(text1, time_extract(text1), sep=':')
text2 = '预定28号的房间'
print(text2, time_extract(text2), sep=':')
text3 = '我要从26号下午4点住到11月2号'
print(text3, time_extract(text3), sep=':')
text4 = '我要预订今天到30的房间'
print(text4, time_extract(text4), sep=':')
text5 = '今天30号呵呵'
print(text5, time_extract(text5), sep=':')
结果如下所示:
我要住到明天下午三点:[‘2019-03-30 15:00:00’]
预定28号的房间:[‘2019-03-28 00:00:00’]
我要从26号下午4点住到11月2号:[‘2019-03-26 16:00:00’, ‘2019-11-02 00:00:00’]
我要预订今天到30的房间:[‘2019-03-30 00:00:00’]
今天30号呵呵:[‘2019-03-30 00:00:00’]
完整代码
词性标注:https://github.com/canshang/python-nlk/blob/master/词性标注与命名实体识别.ipynb
日期识别:https://github.com/canshang/python-nlk/blob/master/日期识别.ipynb
参考文献
《Python自然语言处理实战》