Alibaba Cloud German AI Challenge 2018比赛记录
1 基本信息
Alibaba Cloud German AI Challenge 2018是天池举办的卫星遥感数据分类比赛,网址为https://tianchi.aliyun.com/competition/entrance/231683/introduction?spm=5176.12281957.0.0.38b04c2aARBU3H。比赛的基本信息为参赛者将利用欧洲地球观测卫星Sentinel-1和Sentinel-2的数百万张匹配影像资料,尝试解决都市化带来的挑战。数据集将包括雷达和多光谱传感器数据,覆盖42个城市。竞赛的目标是将数据分类为17个所谓的当地气候区,这将有助于为城市规划者找到解决方案。例如,这些数据可能被用于量化城市热岛的大小或绘制城市地形。对应需要分类的17个类别如下图所示。

初赛和复赛都是解决同一个问题,使用相同的训练集和验证集,其中训练集一共352366组数据,验证集一共24119组数据。只是测试集不同。每组数据包含Sen1和Sen2两份,其中Sen1为合成孔径雷达(SAR),一共给了8个维度;Sen2为高光谱,一共给了10个维度,每个维度大小都为32*32。每个维度的详细说明见下图。一共17个类别。

2 个人成绩及代码
初赛取得了0.809的准确率,名次为136/1329,前两百名晋级复赛。复赛取得了0.817的准确率,名次为67/200。相关代码我已经上传至github:https://github.com/wtrnash/Alibaba-Cloud-German-AI-Challenge-2018。
3 初赛经历
由于数据是HDF5数据,和以往之前的图像数据不同,所以首先使用了官网提供的demo,运行并提交,来了解整个比赛流程,包括数据预处理、划分数据集以及训练后如何输出结果等。官网的demo是把所有像素点当做特征直接svm进行多分类,验证集准确率0.32,线上成绩0.274。可以看出用传统机器学习方法来处理图像分类问题效果是不好的。
3.1 类vgg网络
然后不做任何预处理,使用类似vgg的网络结构(13个卷积层,3个全连接层,考虑到图像大小只有32*32,比原本vgg是使用的224*224小得多,所以池化层减少为只有三层,在github代码中为model.py文件,),每张图像的输入都为32*32*18,即将sen1和sen2的通道进行了叠加,batch size为100,使用adam进行优化。损失函数就是交叉熵。训练从第3个epochs开始到第10个,验证集准确率基本不变。最后选取第6个epochs的,验证集准确率0.61,线上成绩0.627。可以看出验证集和测试集的准确率比较类似,可以用线下的成绩来衡量线上的成绩。
然后对数据进行归一化处理,这里没有按所有样本的均值和标准差进行归一化,而是对每个样本的每个通道进行归一化处理,使得每个样本的每个通道满足正态分布。并且batch size从之前的100提升到200,选取第8个epochs,验证集准确率0.654,线上成绩0.672。可以看出归一化还是对准确率有提升,因为sen1的数据有些分布相差较大,会对准确率有一定的影响。再将batch size调整为512,验证集准确率只有0.637。
把雷达数据和高光谱数据分开,用之前的网络,各一个总共两个网络分别输入sen1的8维度数据和sen2的10维度数据,相当于人为地告诉网络这两份数据的差异而不用网络在训练中自行根据通道进行区分,最后在最后一层直接相加,其他超参数不变。使用第10个epochs, 线下0.666, 线上0.683。使用第14个epochs,线下0.66,线上0.684。
考虑到样本不均衡是本次比赛的一大难点,训练集和验证集的类别数量分布如下:
训练集
[ 5068. 24431. 31693. 8651. 16493. 35290. 3269. 39326. 13584. 11954.
42902. 9514. 9165. 41377. 2392. 7898. 49359.]
验证集
[ 256. 1254. 2353. 849. 757. 1906. 474. 3395. 1914. 860. 2287. 382.
1202. 2747. 202. 672. 2609.]
所以使用focal loss来增加对较难分类的类别的权值,从而部分缓解样本不均衡问题。仍然是使用之前两个类似vgg网络的相关配置,线下0.6658,线上0.683。 基本没有提升,只是收敛的速度加快了。
基于0.683使用的相关条件。使用类别权值来增加少类别的损失,减少多类别的损失,如下图公式所示,其中lambdai为给每个类别i的权值,Ni为该类别的样本数,Nc为总的样本数,K为类别数。其中batch size 128, adam 0.0001, weight decay 0.001, drop out 0.5,训练23个epochs,线下0.679。 线上0.68,效果一般。
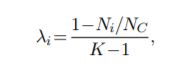
进行调参,weight decay设为0.001, batch size 128, drop out 0.5,训练20个epochs,线下0.676。线上0.68。
尝试调整sen1和sen2的叠加,将叠加放到卷积层之后全连接层之前,线下0.664,线上0.676。
尝试使用翻转来进行数据增强,缓解样本不平衡和过拟合问题,在之前使用focal loss的准确率0.683的网络配置基础上,对于张数小于10000张的图像使用水平翻转、竖直翻转、水平竖直翻转,数量乘4,验证集测试集全部乘4,线下0.657,线上0.674。后来搜索相关资料,发现遥感数据对于方向是敏感的,所以翻转用在遥感数据上效果不会好。
再根据技术圈的讨论等,发现只用sen2或者给sen2较高的权值可能会有较好的效果,所以尝试了一下,只用sen2的数据, 不翻转,Batch size 256 线下0.6568。用0.3 * sen1 + 0.7 * sen2的权值, batch size 128.线下0.6718。线上0.679。0.1 * sen1 + 0.9 * sen2, batch size 128.线下0.665。 效果没有提升。
后来考虑到验证集和测试集的分数差距非常稳定,说明验证集和测试集的分布比较一致,而训练集和测试集的分布可能差别有些大。所以尝试将在训练集训练好后的网络再通过验证集进行训练。之前使用focal loss线上0.683的网络,在验证集上训练12个epochs, 验证集准确率0.9975,线上0.766。23个epochs, 验证集准确率0.9996(此时在训练集上准确率0.812),线上0.776,有了巨大的提升。
对于之前使用类别权值的网络,在验证集上训练,adam 改成0.00001, 3 个epochs, 线下0.868,线上0.744;4个epochs,线下0.888,线上0.747;20及25个epochs,线下均为1, 线上0.734和0.735,效果反而没有不使用类别权值的好。划出3000验证集做测试。adam0.0001,10个epochs,在3000验证集上准确率0.93,线上准确率0.763。所有验证集做训练,不用类别权值,adam0.001,线上准确率0.767。
对于调参后线上0.68的网络,在验证集上训练9个epochs,线下准确率0.991,线上0.76;26个epochs,线下准确率0.999,线上0.769。
以不使用focal loss的线上0.684的为基准,在验证集上训练2个epochs,线上准确率0.768;训练5个epochs,线上准确率0.767。训练10个epochs, 线上准确率0.758。训练20个epochs, 线上准确率0.769。
3.2 ResNet
用类vgg尝试了很多方法后效果提升不大,基本上只用训练集准确率在0.68左右,加了验证集后准确率在0.77左右。所以换网络结构来试试。使用ResNet50,将卷积层的stride和池化层进行修改,为了匹配低分辨率的图像。就使用一个网络,然后18个维度一起输入,超参数和之前类似,使用数据归一化,验证集准确率最高只有0.627,线上0.644。调低网络层数,设成26层(网络结构详见github上代码),数据归一化。验证集准确率最高0.649。在验证集上训练两个epochs,线上0.747。5个epochs,线上0.751。
考虑到使用sen1可能效果不好,所以只用sen2的10个维度作为输入,resnet26,数据归一化,只用sen2,验证集0.642。验证集上训练5个epochs,准确率0.976,线上0.757。训练12个epochs,准确率0.999,线上0.77。
换了一下数据处理方式,20000张验证集数据混进训练集,训练15个epochs,剩下4119张验证集准确率0.832,全部验证集准确率0.929,线上准确率0.731。再训练3个epochs,线下0.9956,线上0.769。
3.3 5层卷积层模型
考虑到数据的分辨率低,之前使用较复杂的ResNet在准确率上相比类似VGG网络并没有提高,说明问题还是过拟合。在网上搜索相关资料时,发现别人只用几层的神经网络也能得到很好的成绩,所以这里使用一个简单的5个卷积层的神经网络(代码见github model_low.py),sen1和sen2数据使用一个模型,focal loss, batchsize 256,adam 0.001, l2 0.01,线下0.64,线上0.659。
将sen1和sen2用两个网络分别训练,再在输出时进行叠加,batchsize 128,线下0.657,线上0.675。 在0.675的基础上,在验证集上训练10个epochs和20个epochs,线上准确率都为0.773。 也能取得和之前类似的效果。
只用sen2的数据,batchsize 256,线下0.66,线上0.672。0.3 * sen1 + 0.7 * sen2,batchsize 128,线下 0.67, 线下0.68。线下0.66,线上0.672。可以看出区别不大。
3.4 其他尝试
考虑sen1数据比较难分,sen1数据用上文的resnet26,sen2用类vgg,batchsize 128,weight_decay0.01,dropout 0.5。训练14个epochs,线下0.67,线上0.677。训练17个epochs,线下0.6696,线上0.686。以0.686为基准,在验证集上训练15个epochs,线下准确率0.9986,34个epochs,验证集准确率为1。线上准确率都为0.77。
同样的sen1用resnet26,sen2用vgg,batchsize 128 + 验证集的 7张。将20000张val数据混合进训练集一起训练。用剩下4119张验证集做val。18个epochs,验证集准确率0.842,线上准确率0.731。
使用inception_resnet_v2,除去部分池化层和修改stride。batchsize128,只用sen2,训练16个epochs,线下准确率0.654。验证集上训练3个epochs,线下准确率0.988,线上准确率0.767;验证集上训练4个epochs,线下准确率0.994,线上0.759;验证集上训练24个epochs,线下0.997,线上准确率0.767。
使用层数很少的cifarnet,18个维度一个网络,线下10个epochs,batchsize256,线下0.648。验证集上训练29个epochs,准确率0.94。线上准确率0.729。
3.5 集成学习
集成学习,使用类vgg线上23个epochs 准确率0.776的、5层模型10个epochs线上准确率0.773和resnet、vgg一起的15个epochs线上准确率0.77,进行3模型简单投票少数服从多数,如果都不一样则听从0.776的模型。线上准确率0.797。
集成学习,使用类vgg线上23个epochs 准确率0.776的、5层模型10个epochs线上准确率0.773和resnet只用sen2的12个epochs线上准确率0.77,进行3模型简单投票少数服从多数,如果都不一样听从0.776的模型。线上准确率0.799。
集成学习,5模型集成,使用vgg线上23epoch 0.776的、5层模型10个epoch线上0.773和resnet、vgg一起的15个epochs线上0.77,esnet只用sen2 12个epochs线上0.77, resnet50只用sen2线上0.769。投票少数服从多数。3个一样就选3个的,2个一样再选2个的。都不一样选第一个分最高的。线上0.808。
还是5个投票,带了两个0.68左右的模型,最后线上准确率只有0.745。
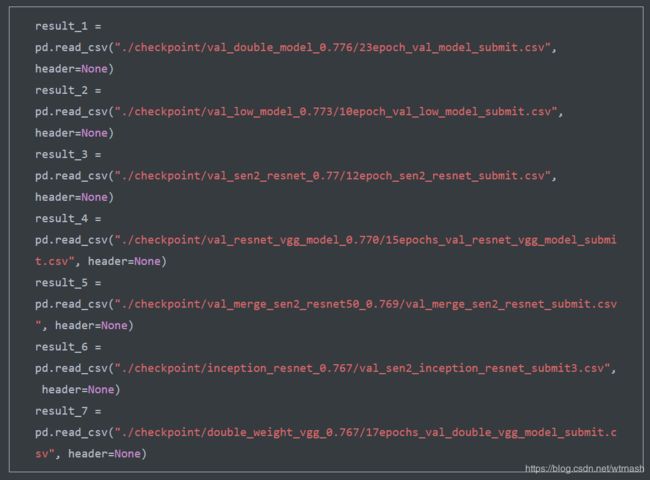
使用7个模型进行集成,配置如下图所示,线上准确率0.816。
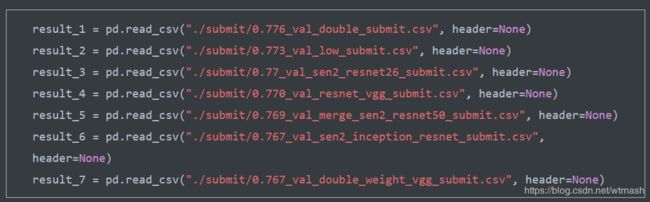
初赛换b榜后,使用如下配置进行集成,最终准确率0.809。
使用5模型在训练集上比较高,没有在验证集上训练的,集成只有0.707。说明测试集b的分布仍然和验证集比较类似,而和训练集不同。
4 复赛经历
由于复赛题目没有更新,只是换了测试集,加上比赛时逢春节,所以没有花非常多的心思,而基本上使用了初赛的模型。
用初赛0.776的版本去测复赛数据集,线上准确率0.779。 初赛0.773去测试,线上准确率0.772。0.683的版本是0.678。 0.7的sen2 resnet 0.759。0.779、0.772、0.759三模型融合 0.803。
使用tensorflow slim提供的在ImageNet上预训练好的vgg,只是第一层和最后一层的参数随机初始化。只用sen2数据, vgg pre train 第11个epochs 线下0.683,线上0.689。 用验证集前21000张进行训练,后3000张进行测试。训练了23个epochs, 准确率0.957。 线上0.796。可以看出用了预训练模型,提高了2个多的百分点,还是有非常好的效果。
只有sen2, resnet50使用预训练模型, 7个 epochs 线下0.61。用验证集21000张训练,8个epochs, 0.90。线上0.742。
使用0.796的进行7模型融合,线上准确率0.823。
使用预训练的resnet50 + vgg,sen1使用resnet50,sen2使用vgg,训练集5个epochs , 0.653。 在21000验证集上训练13个epochs,准确率0.923,线上准确率0.788。
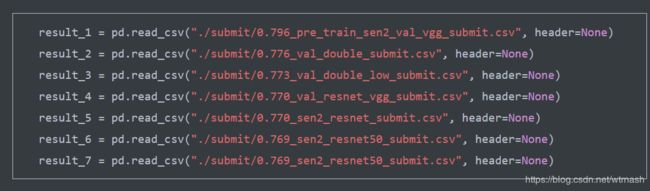
复赛test b,用 7模型融合,配置如下。分数0.817。

仍然是7模型融合,换了几个网络结果进行集成,分数0.812。
5 总结
这次比赛主要是对各个经典网络结构、调参更加熟悉,对于模型集成的效果也更了解,对于预训练模型的效果也有更深的体会。由于是遥感图像,专业问题导致可能对于几个维度的如何专业化进行数据预处理不了解,导致单模型的分数可能不高。然后图像分辨率较低、样本不平衡导致的问题,今后还要看更多论文来进行解决。