分布式幂等性问题的详细剖析
目录
1、何为幂等性?---多次调用,对资源的影响一样
2、幂等性主要场景有哪些?---微服务+MQ+用户交互+第三方接口(支付)
3、幂等性的作用是什么?
1)查询
2)新增
3)修改
4)删除
4、如何解决幂等性问题?
1)控制重复请求-控制操作次数+及时重定向
2)过滤重复动作---分布式锁+token令牌+缓冲队列
3)解决重复写---乐观锁+唯一约束+悲观锁(for update)
后记
1、何为幂等性?---多次调用,对资源的影响一样
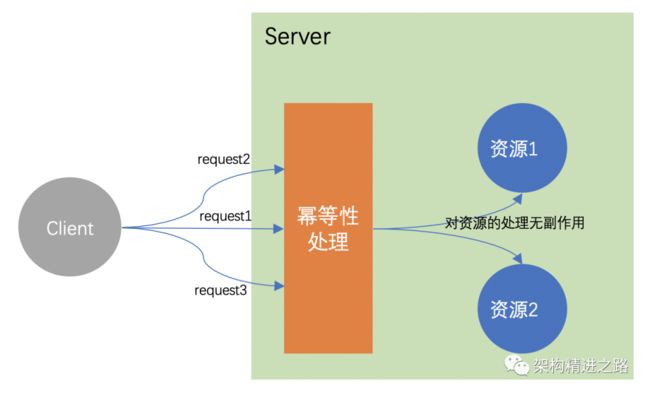
幂等(idempotence),来源于数学中的一个概念,例如:幂等函数/幂等方法(指用相同的参数重复执行,并能获得相同结果的函数,这些函数不影响系统状态,也不用担心重复执行会对系统造成改变)。
简单理解即:多次调用对系统的产生的影响是一样的,即对资源的作用是一样的。
幂等性
幂等性强调的是外界通过接口对系统内部的影响, 只要一次或多次调用对某一个资源应该具有同样的副作用就行。
注意:这里指对资源造成的副作用必须是一样的,但是返回值允许不同!
2、幂等性主要场景有哪些?---微服务+MQ+用户交互+第三方接口(支付)
根据上面对幂等性的定义我们得知:产生重复数据或数据不一致,这个绝大部分是由于发生了重复请求。这里的重复请求是指同一个请求在一些情况下被多次发起。
导致这个情况会有哪些场景呢?
1)微服务架构下,不同微服务间会有大量的基于http,rpc或者mq消息的网络通信,会有第三个情况【未知】,也就是超时。如果超时了,微服务框架会进行重试。
2)用户交互的时候多次点击,无意地触发多笔交易。
3)MQ消息中间件,消息重复消费
4)第三方平台的接口(如:支付成功回调接口),因为异常也会导致多次异步回调
5)其他中间件/应用服务根据自身的特性,也有可能进行重试。
3、幂等性的作用是什么?
幂等性主要保证多次调用对资源的影响是一致的。
在阐述作用之前,我们利用资源处理应用来说明一下:
HTTP与数据库的CRUD操作对应:
PUT :CREATE
GET :READ
POST :UPDATE
DELETE :DELETE
(其实不光是数据库,任何数据如文件图表都是这样)
1)查询
SELECT * FROM users WHERE xxx;
不会对数据产生任何变化,天然具备幂等性。
2)新增
INSERT INTO users (user_id, name) VALUES (1, 'zhangsan');
case1:带有唯一索引(如:`user_id`),重复插入会导致后续执行失败,具有幂等性;
case2:不带有唯一索引,多次插入会导致数据重复,不具有幂等性。
3)修改
case1:直接赋值,不管执行多少次score都一样,具备幂等性。
UPDATE users SET score = 30 WHERE user_id = 1;
case2:计算赋值,每次操作score数据都不一样,不具备幂等性。
UPDATE users SET score = score + 30 WHERE user_id = 1;
4)删除
case1:绝对值删除,重复多次结果一样,具备幂等性。
DELETE FROM users WHERE id = 1;
case2:相对值删除,重复多次结果不一致,不具备幂等性。
DELETE top(3) FROM users;
总结:通常只需要对写请求(新增&更新)作幂等性保证。
4、如何解决幂等性问题?
我们在网上搜索幂等性问题的解决方案,会有各种各样的解法,但是如何判断哪种解决方案对于自己的业务场景是最优解,这种情况下,就需要我们抓问题本质。
经过以上分析,我们得到了解决幂等性问题就是要控制对资源的写操作。
我们从问题各个环节流程来分析解决:![]()

1)控制重复请求-控制操作次数+及时重定向
控制动作触发源头,即前端做幂等性控制实现
相对不太可靠,没有从根本上解决问题,仅算作辅助解决方案。
主要解决方案:
-
控制操作次数,例如:提交按钮仅可操作一次(提交动作后按钮置灰)
-
及时重定向,例如:下单/支付成功后跳转到成功提示页面,这样消除了浏览器前进或后退造成的重复提交问题。
2)过滤重复动作---分布式锁+token令牌+缓冲队列
控制过滤重复动作,是指在动作流转过程中控制有效请求数量。
(a)分布式锁
利用Redis记录当前处理的业务标识,当检测到没有此任务在处理中,就进入处理,否则判为重复请求,可做过滤处理。
订单发起支付请求,支付系统会去Redis缓存中查询是否存在该订单号的Key,如果不存在,则向Redis增加Key为订单号。查询订单支付已经支付,如果没有则进行支付,支付完成后删除该订单号的Key。通过Redis做到了分布式锁,只有这次订单订单支付请求完成,下次请求才能进来。
分布式锁相比去重表,将放并发做到了缓存中,较为高效。思路相同,同一时间只能完成一次支付请求。
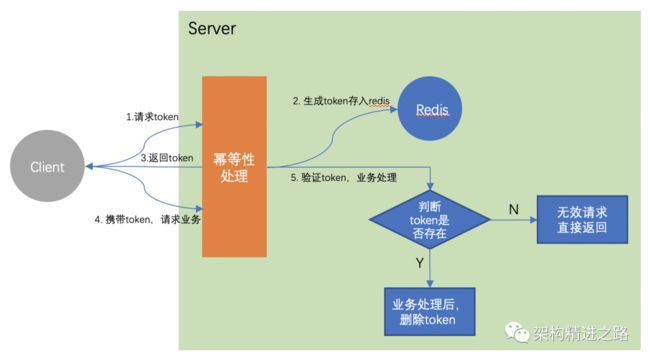
(b)token令牌
应用流程如下:
1)服务端提供了发送token的接口。执行业务前先去获取token,同时服务端会把token保存到redis中;
2)然后业务端发起业务请求时,把token一起携带过去,一般放在请求头部;
3)服务器判断token是否存在redis中,存在即第一次请求,可继续执行业务,执行业务完成后将token从redis中删除;
4)如果判断token不存在redis中,就表示是重复操作,直接返回重复标记给client,这样就保证了业务代码不被重复执行。
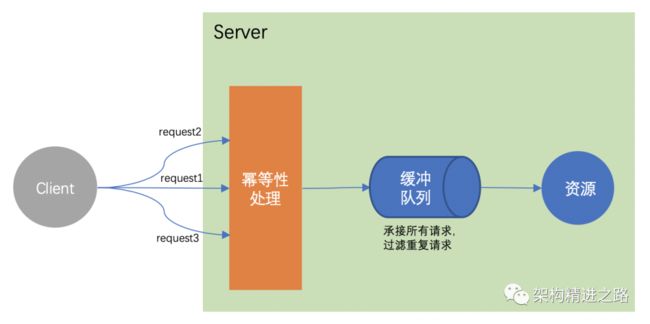
(c)缓冲队列
把所有请求都快速地接下来,对接入缓冲管道。后续使用异步任务处理管道中的数据,过滤掉重复的请求数据。
优点:同步转异步,实现高吞吐。
缺点:不能及时返回处理结果,需要后续监听处理结果的异步返回数据。
3)解决重复写---乐观锁+唯一约束+悲观锁(for update)
实现幂等性常见的方式有:悲观锁(for update)、乐观锁、唯一约束。
1)悲观锁(Pessimistic Lock)
简单理解就是:假设每一次拿数据,都有认为会被修改,所以给数据库的行或表上锁。
当数据库执行select for update时会获取被select中的数据行的行锁,因此其他并发执行的select for update如果试图选中同一行则会发生排斥(需要等待行锁被释放),因此达到锁的效果。
select for update获取的行锁会在当前事务结束时自动释放,因此必须在事务中使用。(注意for update要用在索引上,不然会锁表)
START TRANSACTION; # 开启事务
SELETE * FROM users WHERE id=1 FOR UPDATE;
UPDATE users SET name= 'xiaoming' WHERE id = 1;
COMMIT; # 提交事务
2)乐观锁(Optimistic Lock)
简单理解就是:就是很乐观,每次去拿数据的时候都认为别人不会修改。更新时如果version变化了,更新不会成功。
不过,乐观锁存在失效的情况,就是常说的ABA问题,不过如果version版本一直是自增的就不会出现ABA的情况。
UPDATE users SET name='xiaoxiao', version=(version+1) WHERE id=1 AND version=version;
缺点:就是在操作业务前,需要先查询出当前的version版本
另外,还存在一种:状态机控制
例如:支付状态流转流程:待支付->支付中->已支付。具有一定要的前置要求的,严格来讲,也属于乐观锁的一种。
3)唯一约束
常见的就是利用数据库唯一索引或者全局业务唯一标识(如:source+序列号等)。
这个机制是利用了数据库的主键唯一约束的特性,解决了在insert场景时幂等问题。但主键的要求不是自增的主键,这样就需要业务生成全局唯一的主键,
全局ID生成方案:
-
UUID:结合机器的网卡、当地时间、一个随记数来生成UUID;
-
数据库自增ID:使用数据库的id自增策略,如 MySQL 的 auto_increment。
-
Redis实现:通过提供像 INCR 和 INCRBY 这样的自增原子命令,保证生成的 ID 肯定是唯一有序的。
-
雪花算法-Snowflake:由Twitter开源的分布式ID生成算法,以划分命名空间的方式将 64-bit位分割成多个部分,每个部分代表不同的含义。
小结:按照应用上的最优收益,推荐排序为:乐观锁 > 唯一约束 > 悲观锁。
后记
1)幂等性处理 虽然复杂了业务处理,也可能会降低接口的执行效率,但是为了保证系统数据的准确性,是非常有必要的;
2)遇到问题,善于发现并挖掘本质问题,这样解决起来才能高效且精准;
3)选择自身业务场景适合的解决方案,而不要去硬套一些现成的技术实现,无论是组合还是创新,要记住适合的才是最好的。