Python全栈 面试问题
1、TCP/UDP/HTTP协议区别?
TCP协议,传输控制协议(英语:Transmission Control Protocol,缩写为 TCP)是⼀ 种⾯向连接的、可靠的、基于字节流的传输层通信协议,由IETF的RFC 793定义。
UDP 是User Datagram Protocol的简称, 中文名是用户数据报协议。一种无连接的传输层协议,提供面向事务的简单不可靠信息传送服务。
HTTP协议(HyperText Transfer Protocol,超文本传输协议)是因特网上应用最为广泛的一种网络传输协议,所有的WWW文件都必须遵守这个标准。HTTP是一个基于TCP/IP通信协议来传递数据(HTML 文件, 图片文件, 查询结果等)。
区别TCP通信需要经过创建连接、数据传送、终⽌连接三个步骤。TCP通信模型中,在通信开始之前,⼀定要先建⽴相关的链接,才能发送数
udp通信模型中,在通信开始之前,不需要建立相关链接,只需要发送数据即可。
TCP严格区分客户端和服务端,服务端一般都需要绑定端口,否则客户端找不到该服务器,客户端一般不绑定端口,如果客户端绑定端口就会出现端口冲突导致无法多开的问题。
2、深拷贝浅拷贝
深拷贝深拷贝是对于一个对象所有层次的拷贝(递归)保证了数据的独立性。
如果是可变类型,浅拷贝只拷贝外层,而深拷贝是完全拷贝
如果是纯的不可变类型,那么无论是浅拷贝还是深拷贝,都只是指向同一个地址。如果不可变类型里面还存在可变类型,则浅拷贝是指向,而深拷贝则为完全拷贝。
浅拷贝浅拷贝是对于一个对象的顶层拷贝,通俗的理解是:拷贝了引用,并没有拷贝内容。
3、简述一个前端请求的处理流程,在uwsgi/nginx/django之间的处理流程
4、redis用过哪些数据结构?怎么保存的
5、celery队列
6、modelfirst dbfirst区别?
7、线程/进程/协程区别
进程是资源分配的单位,真正执行代码的是线程,操作系统真正调度的是线程。
进程没有线程效率高,进程占用资源多,线程占用资源少,比线程更少的是协程。
协程依赖于线程、线程依赖于进程,进程一死线程必挂,线程一挂协程必死
一般不用多进程,可以考虑使用多线程,如果多线程里面有很多网络请求,网络可能会有堵塞,此时用协程比较合适。
8、tornado框架
9、向量化–one-hot编码/数据分箱
10、栈、堆
11、你知道的排序算法
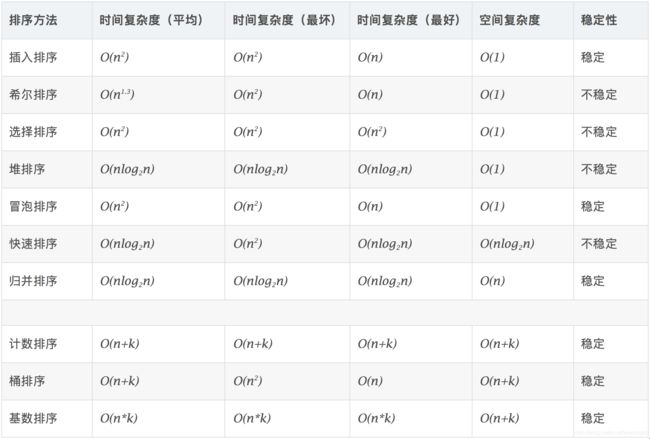
12、MySQL优化、多表查询
对查询进行优化,要尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。
应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num is null
最好不要给数据库留NULL,尽可能的使用 NOT NULL填充数据库.备注、描述、评论之类的可以设置为 NULL,其他的,最好不要使用NULL。不要以为 NULL 不需要空间,比如:char(100) 型,在字段建立时,空间就固定了, 不管是否插入值(NULL也包含在内),都是占用 100个字符的空间的,如果是varchar这样的变长字段, null 不占用空间。可以在num上设置默认值0,确保表中num列没有null值,然后这样查询 select id from t where num=0
应尽量避免在 where 子句中使用 != 或 <> 操作符,否则将引擎放弃使用索引而进行全表扫描
13、Linux下找文件
使用find命令
常用用法:
find ./ -name test.sh 查找当前目录下所有名为test.sh的文件
find ./ -name '.sh’ 查找当前目录下所有后缀为.sh的文件
find ./ -name "[A-Z]" 查找当前目录下所有以大写字母开头的文件
find /tmp -size 2M 查找在/tmp 目录下等于2M的文件
find /tmp -size +2M 查找在/tmp 目录下大于2M的文件
find /tmp -size -2M 查找在/tmp 目录下小于2M的文件
find ./ -size +4k -size -5M 查找当前目录下大于4k,小于5M的文件
find ./ -perm 777 查找当前目录下权限为 777 的文件或目录
14、闭包、装饰器
闭包多层函数嵌套,(函数里面还有定义函数,一般是两个),往往内层函数会用到外层函数的变量,把内层函数以及外部函数的变量当成一个特殊的对象,这就是闭包。闭包比面向对象更纯净、更轻量,既有数据又有执行数据的代码;比普通函数功能更强大,不仅有代码还有数据。
装饰器利用闭包的基本原理,对一个目标函数进行装饰,即在执行一个目标函数之前或之后执行一些特定的事情。
15、Django模型类继承
16、时间更新模型类
17、Settings里面设置东西
18、ajax请求的csrf解决方法
19、机器数据分析/建模有什么感悟?
20、爬虫原理
21、redis为什么快?除了他是内存型数据库外,还有什么原因
22、python2和python3的区别?
print 函数
print语句没有了,取而代之的是print()函数。 Python 2.6与Python 2.7部分地支持这种形式的print语法。
Unicode
Python 2 有 ASCII str() 类型,unicode() 是单独的,不是 byte 类型。
现在, 在 Python 3,我们最终有了 Unicode (utf-8) 字符串,以及一个字节类:byte 和 bytearrays。Python3.X 源码文件默认使用utf-8编码。
除法运算python 2.x中/除法就跟我们熟悉的大多数语言,比如Java啊C啊差不多,整数相除的结果是一个整数,把小数部分完全忽略掉,浮点数除法会保留小数点的部分得到一个浮点数的结果。
在python 3.x中/除法不再这么做了,对于整数之间的相除,结果也会是浮点数。
异常
在 Python 3 中处理异常也轻微的改变了,在 Python 3 中我们现在使用 as 作为关键词。
捕获异常的语法由 except exc, var 改为 except exc as var。
使用语法except (exc1, exc2) as var可以同时捕获多种类别的异常。 Python 2.6已经支持这两种语法。
- 在2.x时代,所有类型的对象都是可以被直接抛出的,在3.x时代,只有继承自BaseException的对象才可以被抛出。
- 2.x raise语句使用逗号将抛出对象类型和参数分开,3.x取消了这种奇葩的写法,直接调用构造函数抛出对象即可。
xrange
在 Python 2 中 xrange() 创建迭代对象的用法是非常流行的。比如: for 循环或者是列表/集合/字典推导式。
这个表现十分像生成器(比如。“惰性求值”)。但是这个 xrange-iterable 是无穷的,意味着你可以无限遍历。
由于它的惰性求值,如果你不得仅仅不遍历它一次,xrange() 函数 比 range() 更快(比如 for 循环)。尽管如此,对比迭代一次,不建议你重复迭代多次,因为生成器每次都从头开始。
在 Python 3 中,range() 是像 xrange() 那样实现以至于一个专门的 xrange() 函数都不再存在(在 Python 3 中 xrange() 会抛出命名异常)。
八进制字面量表示
八进制数必须写成0o777,原来的形式0777不能用了;二进制必须写成0b111。
新增了一个bin()函数用于将一个整数转换成二进制字串。 Python 2.6已经支持这两种语法。
在Python 3.x中,表示八进制字面量的方式只有一种,就是0o1000。
不等运算符
Python 2.x中不等于有两种写法 != 和 <>
Python 3.x中去掉了<>, 只有!=一种写法,还好,我从来没有使用<>的习惯
去掉了repr表达式``
Python 2.x 中反引号``相当于repr函数的作用
Python 3.x 中去掉了``这种写法,只允许使用repr函数,这样做的目的是为了使代码看上去更清晰么?不过我感觉用repr的机会很少,一般只在debug的时候才用,多数时候还是用str函数来用字符串描述对象。
数据类型
1)Py3.X去除了long类型,现在只有一种整型——int,但它的行为就像2.X版本的long
2)新增了bytes类型,对应于2.X版本的八位串
23、你觉得python2的项目如果迁移到python3,困难会在哪里?
exit(❓)