大量数据去重:Bitmap和布隆过滤器(Bloom Filter)
5TB的硬盘上放满了数据,请写一个算法将这些数据进行排重。如果这些数据是一些32bit大小的数据该如何解决?如果是64bit的呢?
在面试时遇到的问题,问题的解决方案十分典型,但对于海量数据处理接触少的同学可能一时也想不到什么好方案。介绍两个算法,对于空间的利用到达了一种极致,那就是Bitmap和布隆过滤器(Bloom Filter)。
Bitmap算法
在网上并没有找到Bitmap算法的中文翻译,在《编程珠玑》中有提及。与其说是算法,不如说是一种紧凑的数据存储结构。其实如果并非如此大量的数据,有很多排重方案可以使用,典型的就是哈希表。
public int[] removeDuplicates(int[] array) {
int index = 0;
Map maps = new LinkedHashMap();
for(int num : array) {
if(!maps.contains(num)) {
array[index] = num;
index++;
maps.put(num, true);
}
}
return newArray;
} 实际上,哈希表实际上为每一个可能出现的数字提供了一个一一映射的关系,每个元素都相当于有了自己的独享的一份空间,这个映射由散列函数来提供(这里我们先不考虑碰撞)。实际上哈希表甚至还能记录每个元素出现的次数,这样的数据结构完成这个任务有点“大材小用”了。
我们拆解一下我们的需求:
- 集合中每个元素(示例中是
int)有一个独享的空间 - 找到一个到这个空间的映射方法
这个空间要多大?对于我们的问题来说,一个boolean就够了,或者说,1个bit就够了,我们只想知道某个元素出现过没有。如果为每个所有可能的值分配1个bit,32bit的int所有可能取值需要内存空间为:
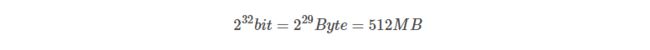
那怎么样完成这个映射呢?其实就是Bitmap所要完成的工作了。如果我们把整型0x01、0x02、…、0x08的空间依次映射到一个Byte上,每个bit就代表这个int值是否出现过,初值为0(false)。
若扩展到整个int取值域,申请一个byte[]即可,示例代码如下:
public static final int _1MB = 1024 * 1024;
public static byte[] flags = new byte[ 512 * _1MB ];
public static void main(String[] args) {
int[] array = {255, 1024, 0, 65536}
int index = 0;
for(int num : array) {
if(!getFlags(num)) {
//未出现的元素
array[index] = num;
index = index + 1;
//设置标志位
setFlags(num);
}
}
}
public static void setFlags(int num) {
flags[num >> 3] |= 0x01 << (num & (0x07));
}
public static boolean getFlags(int num) {
return flags[num >> 3] >> (num & (0x07)) & 0x01;
}其实,就是按int从小到大的顺序依次摆放到byte[]中,仅涉及到一些除以2的整次幂和对2的整次幂取余的位操作小技巧。很显然,对于小数据量、数据取值很稀疏,上面的方法并没有什么优势,但对于海量的、取值分布很均匀的集合进行去重,Bitmap极大地压缩了所需要的内存空间。于此同时,还额外地完成了对原始数组的排序工作。缺点是,Bitmap对于每个元素只能记录1bit信息,如果还想完成额外的功能,恐怕只能靠牺牲更多的空间、时间来完成了。
哈希 hash
原理
Hash (哈希,或者散列)函数在计算机领域,尤其是数据快速查找领域,加密领域用的极广。其作用是将一个大的数据集映射到一个小的数据集上面(这些小的数据集叫做哈希值,或者散列值)。
一个应用是Hash table(散列表,也叫哈希表),是根据哈希值 (Key value) 而直接进行访问的数据结构。也就是说,它通过把哈希值映射到表中一个位置来访问记录,以加快查找的速度。下面是一个典型的 hash 函数 / 表示意图:
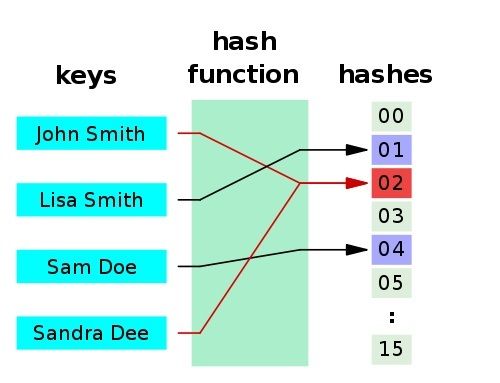
- 如果两个散列值是不相同的(根据同一函数),那么这两个散列值的原始输入也是不相同的。
- 散列函数的输入和输出不是唯一对应关系的,如果两个散列值相同,两个输入值很可能是相同的。但也可能不同,这种情况称为 “散列碰撞”(或者 “散列冲突”)。
所以要引入下面的 Bloom Filter。
布隆过滤器 Bloom Filter
原理
如果想判断一个元素是不是在一个集合里,一般想到的是将集合中所有元素保存起来,然后通过比较确定。链表、树、散列表(又叫哈希表,Hash table)等等数据结构都是这种思路。但是随着集合中元素的增加,我们需要的存储空间越来越大。同时检索速度也越来越慢。Bloom Filter 是一种空间效率很高的随机数据结构,Bloom filter 可以看做是对 bit-map 的扩展, 它的原理是:
当一个元素被加入集合时,通过 K 个 Hash 函数将这个元素映射成一个位阵列(Bit array)中的 K 个点,把它们置为 1。检索时,我们只要看看这些点是不是都是 1 就(大约)知道集合中有没有它了:
- 如果这些点有任何一个 0,则被检索元素一定不在;
- 如果都是 1,则被检索元素很可能在。
优点
它的优点是空间效率和查询时间都远远超过一般的算法,布隆过滤器存储空间和插入 / 查询时间都是常数O(k)。另外, 散列函数相互之间没有关系,方便由硬件并行实现。布隆过滤器不需要存储元素本身,在某些对保密要求非常严格的场合有优势。缺点
但是布隆过滤器的缺点和优点一样明显。误算率是其中之一。随着存入的元素数量增加,误算率随之增加。但是如果元素数量太少,则使用散列表足矣。(误判补救方法是:再建立一个小的白名单,存储那些可能被误判的信息。)
另外,一般情况下不能从布隆过滤器中删除元素. 我们很容易想到把位数组变成整数数组,每插入一个元素相应的计数器加 1, 这样删除元素时将计数器减掉就可以了。然而要保证安全地删除元素并非如此简单。首先我们必须保证删除的元素的确在布隆过滤器里面. 这一点单凭这个过滤器是无法保证的。另外计数器回绕也会造成问题。
Example
可以快速且空间效率高的判断一个元素是否属于一个集合;用来实现数据字典,或者集合求交集。如: Google chrome 浏览器使用bloom filter识别恶意链接(能够用较少的存储空间表示较大的数据集合,简单的想就是把每一个URL都可以映射成为一个bit),这种方法效率非常高,并且误判率在万分之一以下。
又如: 检测垃圾邮件
假定我们存储一亿个电子邮件地址,我们先建立一个十六亿二进制(比特),即两亿字节的向量,然后将这十六亿个二进制全部设置为零。对于每一个电子邮件地址 X,我们用八个不同的随机数产生器(F1,F2, ...,F8) 产生八个信息指纹(f1, f2, ..., f8)。再用一个随机数产生器 G 把这八个信息指纹映射到 1 到十六亿中的八个自然数 g1, g2, ...,g8。现在我们把这八个位置的二进制全部设置为一。当我们对这一亿个 email 地址都进行这样的处理后。一个针对这些 email 地址的布隆过滤器就建成了。
再如此题:
A,B 两个文件,各存放 50 亿条 URL,每条 URL 占用 64 字节,内存限制是 4G,让你找出 A,B 文件共同的 URL。如果是三个乃至 n 个文件呢?
分析 :如果允许有一定的错误率,可以使用 Bloom filter,4G 内存大概可以表示 340 亿 bit。将其中一个文件中的 url 使用 Bloom filter 映射为这 340 亿 bit,然后挨个读取另外一个文件的 url,检查是否与 Bloom filter,如果是,那么该 url 应该是共同的 url(注意会有一定的错误率)。”