一些算法的MapReduce实现——矩阵分块乘法计算(2)
Problem
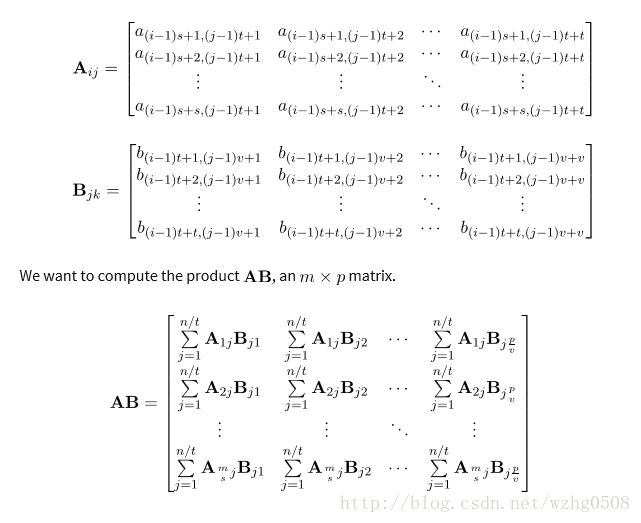
M*N的矩阵A分割成s*t, N*P的矩阵B分割成t*v,
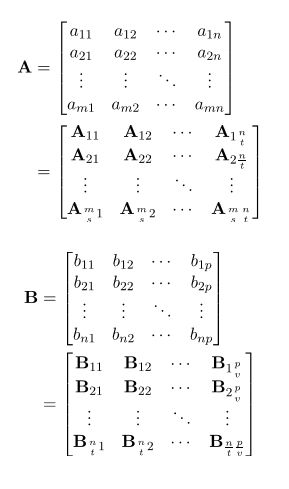
所以
Input
假设矩阵A,B为

输入的样例数据如下:
A,0,1,1.0
A,0,2,2.0
A,0,3,3.0
A,0,4,4.0
A,1,0,5.0
A,1,1,6.0
A,1,2,7.0
A,1,3,8.0
A,1,4,9.0
B,0,1,1.0
B,0,2,2.0
B,1,0,3.0
B,1,1,4.0
B,1,2,5.0
B,2,0,6.0
B,2,1,7.0
B,2,2,8.0
B,3,0,9.0
B,3,1,10.0
B,3,2,11.0
B,4,0,12.0
B,4,1,13.0
B,4,2,14.0
Output
上述样例数据的数出结果为:
0,0,90.0
0,1,100.0
0,2,110.0
1,0,240.0
1,1,275.0
1,2,310.0
Pseudocode
矩阵AB的分块乘法计算分两步map-reduce进行
第一步
map(key, value):
// value is ("A", i, j, a_ij) or ("B", j, k, b_jk)
if value[0] == "A":
i = value[1]
j = value[2]
a_ij = value[3]
for k_per_v = 0 to p/v - 1:
emit((i/s, j/t, k_per_v), ("A", i%s, j%t, a_ij))
else:
j = value[1]
k = value[2]
b_jk = value[3]
for i_per_s = 0 to m/s - 1:
emit((i_per_s, j/t, k/v), ("B", j%t, k%v, b_jk))
reduce(key, values):
// key is (i_per_s, j_per_t, k_per_v)
// values is a list of ("A", i_mod_s, j_mod_t, a_ij) and ("B", j_mod_t, k_mod_v, b_jk)
list_A = [(i_mod_s, j_mod_t, a_ij) for (M, i_mod_s, j_mod_t, a_ij) in values if M == "A"]
list_B = [(j_mod_t, k_mod_v, b_jk) for (M, j_mod_t, k_mod_v, b_jk) in values if M == "B"]
hash = {}
for a in list_A:
for b in list_B:
if a[1] == b[0]: // a.j_mod_t == b.j_mod_t
hash[(a[0], b[1])] += a[2]*b[2]
for {(i_mod_s, k_mod_v): v} in hash:
emit((key[0]*s + i_mod_s, key[2]*v + k_mod_v), v)
第二步
map(key, value):
emit(key, value)
reduce(key, values):
result = 0
for value in values:
result += value
emit(key, result)
Hadoop代码
import java.io.IOException;
import java.util.*;
import java.util.AbstractMap.SimpleEntry;
import java.util.Map.Entry;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.*;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class BlockMatrixMultiplication {
public static class Map extends Mapper {
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
Configuration conf = context.getConfiguration();
int m = Integer.parseInt(conf.get("m"));
int p = Integer.parseInt(conf.get("p"));
int s = Integer.parseInt(conf.get("s"));
int t = Integer.parseInt(conf.get("t"));
int v = Integer.parseInt(conf.get("v"));
int mPerS = m/s; // Number of blocks in each column of A.
int pPerV = p/v; // Number of blocks in each row of B.
String line = value.toString();
String[] indicesAndValue = line.split(",");
Text outputKey = new Text();
Text outputValue = new Text();
if (indicesAndValue[0].equals("A")) {
int i = Integer.parseInt(indicesAndValue[1]);
int j = Integer.parseInt(indicesAndValue[2]);
for (int kPerV = 0; kPerV < pPerV; kPerV++) {
outputKey.set(Integer.toString(i/s) + "," + Integer.toString(j/t) + "," + Integer.toString(kPerV));
outputValue.set("A," + Integer.toString(i%s) + "," + Integer.toString(j%t) + "," + indicesAndValue[3]);
context.write(outputKey, outputValue);
}
} else {
int j = Integer.parseInt(indicesAndValue[1]);
int k = Integer.parseInt(indicesAndValue[2]);
for (int iPerS = 0; iPerS < mPerS; iPerS++) {
outputKey.set(Integer.toString(iPerS) + "," + Integer.toString(j/t) + "," + Integer.toString(k/v));
outputValue.set("B," + Integer.toString(j%t) + "," + Integer.toString(k%v) + "," + indicesAndValue[3]);
context.write(outputKey, outputValue);
}
}
}
}
public static class Reduce extends Reducer {
public void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
String[] value;
ArrayList> listA = new ArrayList>();
ArrayList> listB = new ArrayList>();
for (Text val : values) {
value = val.toString().split(",");
if (value[0].equals("A")) {
listA.add(new SimpleEntry(value[1] + "," + value[2], Float.parseFloat(value[3])));
} else {
listB.add(new SimpleEntry(value[1] + "," + value[2], Float.parseFloat(value[3])));
}
}
String[] iModSAndJModT;
String[] jModTAndKModV;
float a_ij;
float b_jk;
String hashKey;
HashMap hash = new HashMap();
for (Entry a : listA) {
iModSAndJModT = a.getKey().split(",");
a_ij = a.getValue();
for (Entry b : listB) {
jModTAndKModV = b.getKey().split(",");
b_jk = b.getValue();
if (iModSAndJModT[1].equals(jModTAndKModV[0])) {
hashKey = iModSAndJModT[0] + "," + jModTAndKModV[1];
if (hash.containsKey(hashKey)) {
hash.put(hashKey, hash.get(hashKey) + a_ij*b_jk);
} else {
hash.put(hashKey, a_ij*b_jk);
}
}
}
}
String[] blockIndices = key.toString().split(",");
String[] indices;
String i;
String k;
Configuration conf = context.getConfiguration();
int s = Integer.parseInt(conf.get("s"));
int v = Integer.parseInt(conf.get("v"));
Text outputValue = new Text();
for (Entry entry : hash.entrySet()) {
indices = entry.getKey().split(",");
i = Integer.toString(Integer.parseInt(blockIndices[0])*s + Integer.parseInt(indices[0]));
k = Integer.toString(Integer.parseInt(blockIndices[2])*v + Integer.parseInt(indices[1]));
outputValue.set(i + "," + k + "," + Float.toString(entry.getValue()));
context.write(null, outputValue);
}
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
// A is an m-by-n matrix; B is an n-by-p matrix.
conf.set("m", "2");
conf.set("n", "5");
conf.set("p", "3");
conf.set("s", "2"); // Number of rows in a block in A.
conf.set("t", "5"); // Number of columns in a block in A = number of rows in a block in B.
conf.set("v", "3"); // Number of columns in a block in B.
Job job = new Job(conf, "MatrixMatrixMultiplicationTwoStepsBlock");
job.setJarByClass(BlockMatrixMultiplication.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
}
第二步map-reduce代码简单,在此省略
Analysis
上述第一步map-reduce过程中:
1、reduce job的数目 = 所有发送给reduce任务的unique keys 的数目,即
(m*n*p) / (s*t*v)
2、矩阵A发送给每个reduce元素的个数为st
3、矩阵B发送给每个reduce元素的个数为tv
communication cost:
1、The communication cost of the first Map tasks is
2、The communication cost of the first Reduce tasks is
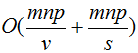
3、The communication cost of the second Map tasks is
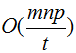
4、The communication cost of the second Reduce tasks is

如果s、t、v变大的话,那么矩阵被分割的块的数目就变少了,也就reduce的数目也将变少,每个reduce处理的数据将变大,也就需要更过的内存
Reference
翻译自 1、http://importantfish.com/block-matrix-multiplication-with-hadoop/
2、http://www.norstad.org/matrix-multiply/ 讲的十分详细的矩阵乘法计算