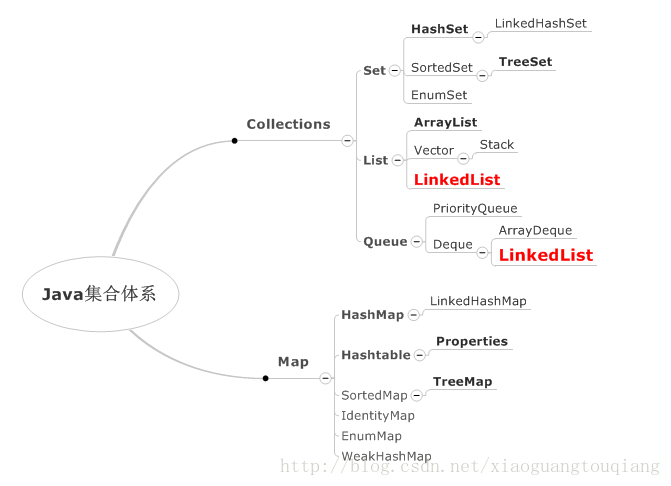
Java集合类List、Set、Queue、Map实现类
1.Collection
Collection最基本的集合接口,一个Collection代表一组Object的集合
public interface Collection<E> extends Iterable<E> {
任何实现Collection接口的类,都必须实现iterator方法来提供遍历集合中的元素
Iterator<T> iterator();
例如List中集合的遍历可以采用如下方式
Liststrings = Arrays.asList(array); Iterator iterator = strings.iterator(); while(iterator.hasNext()){ System.out.printf(iterator.next()); }
注意Collection和Collectors的区别,这个在面试的时候也是经常问到的问题,Collection是集合的接口,所有的集合类都实现该接口,Collectors是一个类,提供了sort方法对集合进行排序;简单提一下Collectors.sort方法的使用:
1>.要排序的类实现Comparable接口,实现compareTo方法;然后使用Collerctors.sort(List
2>在排序的时候再去new一个Comparator,比如
Collections.sort(list,new Comparator(){
public int compare(User arg0, User arg1) {
return arg0.getOrder().compareTo(arg1.getOrder());
}
}); 1.1.Set
Set继承Collection接口,不能包含重复元素,Set判断两个对象不是使用==来判断,是使用equals方法,新加入的元素会与已有的元素判断equals比较返回false则加入,否则拒绝加入;所以使用Set的时候有两点需要注意:1.放入的对象要实现equals方法;2.对set的构造函数中,传入的Collection参数不能包含重复的元素。
1.1.1HashSet
HashSet实现了Set接口,由哈希表提供支持,不保证Set的迭代顺序;允许使用null值,同时不允许元素有重复,因为HashSet底层是使用HashMap来实现的,HashSet中的元素都存放在HashMap的key上面,value是一个统一的静态变量;
HashSet中添加元素调用add方法,然后会调用HashMap的put方法插入元素,HashMap的put方法插入元素时,会首先判断是否存在key,如果不存在,则插入这个key-value,存在则修改value值;在set中,value值没用,因此往HashSet中添加元素,首先判断key是否存在,不存在插入元素,存在则不做处理;
HashSet使用Hash算法存储集合中的元素,具有很好的查找和存取性能。向HashSet中存入一个元素时,HashSet调用对象的HashCode方法获取对象的HashCode值,根据HashCode值决定对象的存储位置。HashSet判断元素对象是否相同的方法是同时使用HashCode和equals方法来判断,关于equals方法和HashCode的说明:
1>.equals相等的对象,hashCode一定相等;
2>.equals不相等的对象,hashCode可能相等,也可能相等。(哈希生成的时候产生碰撞)
3>.反之,HashCode不相等,则equals方法一定不相等(如果equals相等则与规则1矛盾);
4>.HashCode相等,equals可以相等,也可以不相等。
HashSet判断元素相等方法时,首先判断两个对象的HashCode是否相等,如果不相等,则认为两个对象也不相等,如果相等再判断equals方法是否相等;如果hashCode相等,equals方法不相等,则认为时不同的对象;为什么这样做,主要是为了提高效率,HashCode的效率比equals效率更高,不必每次重新计算Hash值
1.1.1.1 linkedHashSet
linkedHashSet继承自HashSet,同时使用链表来维护元素的顺序,元素以插入的顺序进行访问;在性能上略低于HashSet,但在迭代访问时有很好的性能;
1.1.2 SortedSet
主要用于排序操作,实现此接口的子类都属于排序子类。
1.1.2.1 TreeSet
基于SortedSet,底层实现是通过二叉树,插入的元素要实现Comparable接口。
1.2 List
List代表元素有序,可重复的集合,集合中每个元素都有对应的顺序索引,允许加入重复元素,通过索引指定元素的位置,实现有ArrayList,Vector,Queue。
1.2.1 ArrayList
ArrayList是基于数组的实现,封装了一个动态增长,允许再分配的Object[]数组。
1.2.2 Vector
public class Vector<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable
使用方法和ArrayList基本相同,子类有Stack,和ArrayList区别是Vector是线程安全的,对集合元素操作的时候都加了Synchronized,保证线程的安全;在扩容时,Vector默认增长一倍的容量,而List只增长50%;
1.2.2.1 Stack
class Stack<E> extends Vector<E> {
stack(栈)实现了Vector类,后进先出。
1.2.3 LinkedList
public class LinkedList<E> extends AbstractSequentialList<E> implements List<E>, Deque<E>, Cloneable, java.io.Serializable
实现List接口,Deque接口;基于链式的存储方式
1.3.Queue
queue用于模拟队列这种数据结构,先进先出。
2.Map
map用于保存映射关系的数据结构,java先是实现了Map数据结构,然后在这个基础上进行包装,key用来存放具体的值,value为null的map就实现了set的数据结构;
2.1 HashMap
HashMap根据键的HashCode值存储数据,具有很快的访问速度,遍历时,获取的元素顺序是随机的;允许null key存在,不支持线程的同步,即同一时刻有多个线程写map,可能导致最终数据不一致。如果需要同步可以用SynchroizedMap方法或者使用ConcurrentHashMap(基于ReentrantLock来实现的),HashMap的数据结构
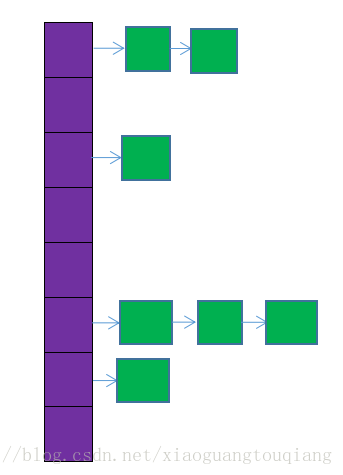
紫色部分是hash数组,数组的每个元素时链表的头节点,链表是用来解决hash冲突的,如果不同的key映射到同一个位置就将它放到链表中去。插入元素时,放在链表的头节点。HashMap是无序的,元素遍历的顺序和插入的顺序是不一致的,如果要一致可以使用下面的LinkedHashMap;
2.1.1 LinkedHashMap
使用双向链表来维护Map的key-value的顺序,保持读取顺序和插入元素的顺序一致。
2.2 HashTable
在处理元素时使用Synchronize,所以它是线程安全的。
2.3 SortedMap
public interface SortedMap<K,V> extends Map<K,V> {
正如set派生出SortedSet一样,Map也派生出SortedMap,实现排序功能,任何实现该接口的类必须实现排序接口。
Comparatorsuper K> comparator();
实现类有TreeMap;
2.3.1 TreeMap
TreeMap数据结构是红黑树,TreeMap存储key-value时,根据key对节点进行排序,保证所有节点的有序状态。