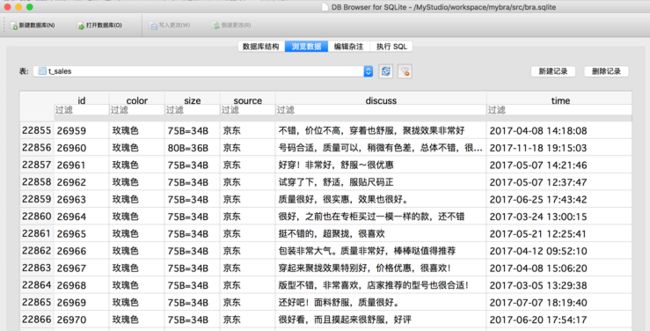
本文会继续抓取京东商城的商品评论数据是通过 productPageComments.action 页面获取的 JSON 数据,在这个 Url 中有一个 page 参数可以设置当前获取的评论页数,如图1所示。
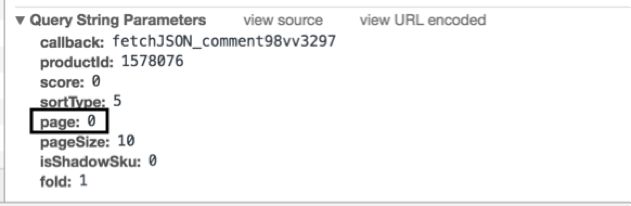
图1 获取当前评论页数
不过将这个 Url 在浏览器中访问后,会显示如图2所示的内容,很明显,这并不是纯粹的 JSON 数据,前面还有fetchJSON_comment98vv3297,以及其他一些不属于 JSON 数据的内容,我们不需要管这些是什么东西,直接去掉就可以了。这个fetchJSON_comment98vv3297就是 Url 最后的 callback 参数的值,应该是一个回调函数,我们不需要管它,直接去掉就可以了。
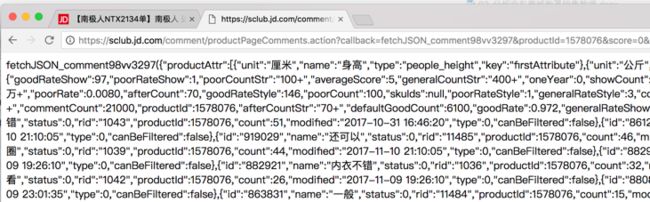
图2 在浏览器中访问 Url
去掉这些零碎的方法很多,本例采用了直接替换的方式。代码如下:
# productId 是商品 ID,page 是页码
def getComments(productId,page):
# 定义获取评论数据的url
url = 'https://sclub.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv14&productId=' + str(productId) + '&score=0&sortType=5&page=' + str(page) + '&pageSize=10&isShadowSku=0&fold=1'
# 向服务端发送HTTP GET请求
r = http.request('GET',url)
# 下面的代码开始替换json文本中的内容,以便可以解析
c = r.data.decode('ISO-8859-1')
c = c.replace('fetchJSON_comment98vv14(','')
c = c.replace(')','')
c = c.replace('false','"false"')
c = c.replace('true','"true"')
c = c.replace('null','"null"')
c = c.replace(';','')
# 将json文本转换为字典对象
jdDict = json.loads(c)
return jdDict
由于京东商城服务端会检测浏览器类型,所以在向服务端发送 HTTP 请求是需要加上 HTTP 请求头,为了方便,这里将 HTTP 请求头的信息都放到了 headers.txt 文件中,并编写了 str2Headers() 函数,将 headers.txt 文件中的 HTTP 请求头转换为字典对象。
def str2Headers(file):
headerDict = {}
f = open(file,'r')
headersText = f.read()
headers = re.split('\n',headersText)
# 将每一行http请求拆分成key和value
for header in headers:
result = re.split(':',header,maxsplit = 1)
headerDict[result[0]] = result[1]
f.close()
return headerDict
# 将headers.txt文件中的http请求头转换为字典对象(headers)
headers = str2Headers('headers.txt')
接下来的任务就是抓取搜索页面的所有商品列表,搜索页面是 Search,后面会跟一堆参数,不需要管它,只需要从返回的 HTML 代码中使用 BeautifulSoup 进行分析,得到我们想要的结果即可,实现代码如下:
# 以列表形式返回商品ID
def getProductIdList():
# 定义用于搜索商品的Url
url = "https://search.jd.com/Search?keyword=%E8%83%B8%E7%BD%A9&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq=%E8%83%B8%E7%BD%A9&psort=3&click=0"
# 向服务的发送HTTP GET请求
r = http.request('GET', url,headers = headers)
r = r.data.decode('ISO-8859-1')
# 创建用于解析HTML的BeautifulSoup对象
soup = BeautifulSoup(r,'lxml')
links = []
idList = []
# 获取满足一定条件的a标签的href属性值
tags = soup.find_all(href=re.compile('//item.jd.com/'))
for tag in tags:
links.append(tag['href'])
linkList = list(set(links))
for k in linkList:
a = k.split('com/')
idList.append(a[1].replace('.html','').replace('#comment',''))
return idList
最后就很容易了,只需要利用前面给出的两个函数抓取评论数据,然后利用 SQLite 3 模块中的 API 将抓取的数据写入 SQLite 数据库即可,下面看一下完整的实现代码。
from urllib3 import *
import sqlite3
import json
import re
import os
from bs4 import BeautifulSoup
disable_warnings()
http = PoolManager()
# 定义SQLite数据库文件名
dbPath = 'bra.sqlite'
# 链接SQLite数据库
conn = sqlite3.connect(dbPath)
cursor = conn.cursor()
# 根据产品ID和指定页数获取产品的评论数据
def getComments(productId,page):
# 定义用于获取评论数据的Url
url = 'https://sclub.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv14&productId=' + str(productId) + '&score=0&sortType=5&page=' + str(page) + '&pageSize=10&isShadowSku=0&fold=1'
# 向服务端发送HTTP GET请求
r = http.request('GET',url)
# 用ISO-8859-1编码格式对数据进行解码
c = r.data.decode('ISO-8859-1')
# 下面的代码开始替换json文本中的部分字符串,
# 以便让json可以转化为字典对象
c = c.replace('fetchJSON_comment98vv14(','')
c = c.replace(')','')
c = c.replace('false','"false"')
c = c.replace('true','"true"')
c = c.replace('null','"null"')
c = c.replace(';','')
jdDict = json.loads(c)
return jdDict
# 得到指定商品ID的最大评论页数
def getMaxPage(productId):
return getComments(productId,0)['maxPage']
# 从指定文件读取HTTP响应头,并将其转化为字典对象
def str2Headers(file):
headerDict = {}
f = open(file,'r')
headersText = f.read()
headers = re.split('\n',headersText)
for header in headers:
result = re.split(':',header,maxsplit = 1)
headerDict[result[0]] = result[1]
f.close()
return headerDict
headers = str2Headers('headers.txt')
def getProductIdList():
# 定义用户获取京东搜索商品搜索列表的Url
url = "https://search.jd.com/Search?keyword=%E8%83%B8%E7%BD%A9&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq=%E8%83%B8%E7%BD%A9&psort=3&click=0"
# 向服务端发送HTTP GET请求
r = http.request('GET', url,headers = headers)
# 用ISO-8859-1编码格式解码返回结果
r = r.data.decode('ISO-8859-1')
# 创建用于解析HTML代码的BeautifulSoup对象
soup = BeautifulSoup(r,'lxml')
links = []
idList = []
# 获取所有满足条件的a标签
tags = soup.find_all(href=re.compile('//item.jd.com/'))
for tag in tags:
links.append(tag['href'])
linkList = list(set(links))
# 获取所有商品的ID
for k in linkList:
a = k.split('com/')
idList.append(a[1].replace('.html','').replace('#comment',''))
return idList
productIdList = getProductIdList()
initial = 0
# 开始抓取所有的胸罩评论数据
while initial < len(productIdList):
try:
# 获取商品ID
productId = productIdList[initial]
# 获取当前商品最大评论数
maxnum = getMaxPage(productId)
num = 1
# 开始抓取特定商品的所有评论数据
while num <= maxnum:
try:
jdDict = getComments(productId, num)
comments = jdDict['comments']
n = 0
# 获取每一页评论的数据
while n < len(comments):
comment = comments[n]
content = comment['content'].encode(encoding='ISO-8859-1').decode('GB18030')
productColor = comment['productColor'].encode(encoding='ISO-8859-1').decode('GB18030')
creationTime = comment['creationTime'].encode(encoding='ISO-8859-1').decode('GB18030')
productSize = comment['productSize'].encode(encoding = 'ISO-8859-1').decode('GB18030')
# 开始将评论数据写入SQLite数据库
cursor.execute('''insert into t_sales(color,size,source,discuss,time)
values('%s','%s','%s','%s','%s')'''
% (productColor,productSize,'京东','a',creationTime))
conn.commit()
n += 1
num += 1
except Exception as e:
print(e)
continue
initial += 1
except Exception as e:
print(e)
conn.close()
现在可以运行这个 Python 脚本文件,首先会自动建立名为 bra.sqlite 的 SQLite 数据库,然后会将抓取的数据保存到 bra.sqlite 数据库中的t_sales表中,效果如图3所示。