用Pytorch手工实现ResNet50
《吴恩达深度学习课程》第四课第二周的作业是:使用Keras和Tensorflow编写ResNet50,用程序实现题目中描述的网络结构。由于程序填空提供了不少示例,做完后仍感觉理解不透彻,又使用Pytorch实现了一遍。
ResNet50包含49个卷积层和1个全连接层,属于较大型的网络,实现起来略有难度。对于理解数据流、卷积层、残差、瓶颈层,以及对大型网络的编写和调试都有很大帮助。
使用的数据仍是第四课第二周中的手势图片识别,题目说明、Keras例程和相关数据可从以下网址下载:https://blog.csdn.net/u013733326/article/details/80250818
Keras ResNet50程序填空的代码可从以下网址下载: https://github.com/Kulbear/deep-learning-coursera/blob/master/Convolutional%20Neural%20Networks/Residual%20Networks%20-%20v1.ipynb
Torch官方版本的ResNet实现可从以下网址下载(网络结构细节略有不同): https://github.com/pytorch/vision/blob/master/torchvision/models/resnet.py
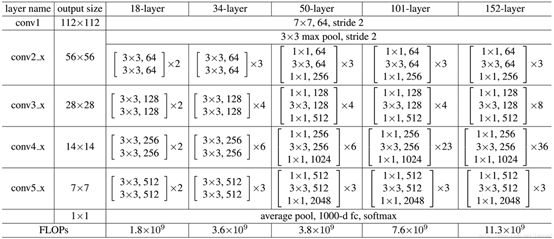
网络结构
ResNet网络结构如下图所示:
代码
下面使用约100行代码实现了ResNet50网络类(可缩减至80行左右),另外100行代码用于处理数据,训练和预测。
准备数据:
import math
import numpy as np
import h5py
import matplotlib.pyplot as plt
import scipy
from PIL import Image
from scipy import ndimage
import torch
import torch.nn as nn
from cnn_utils import *
from torch import nn,optim
from torch.utils.data import DataLoader,Dataset
from torchvision import transforms
%matplotlib inline
np.random.seed(1)
torch.manual_seed(1)
batch_size = 24
learning_rate = 0.009
num_epocher = 100
X_train_orig, Y_train_orig, X_test_orig, Y_test_orig, classes = load_dataset()
X_train = X_train_orig/255.
X_test = X_test_orig/255.
class MyData(Dataset): #继承Dataset
def __init__(self, data, y, transform=None): #__init__是初始化该类的一些基础参数
self.transform = transform #变换
self.data = data
self.y = y
def __len__(self):#返回整个数据集的大小
return len(self.data)
def __getitem__(self,index):#根据索引index返回dataset[index]
sample = self.data[index]
if self.transform:
sample = self.transform(sample)#对样本进行变换
return sample, self.y[index] #返回该样本
train_dataset = MyData(X_train, Y_train_orig[0],
transform=transforms.ToTensor())
test_dataset = MyData(X_test, Y_test_orig[0],
transform=transforms.ToTensor())
train_loader = DataLoader(train_dataset,batch_size=batch_size,shuffle=True)
test_loader = DataLoader(test_dataset,batch_size=batch_size,shuffle=False)
实现ResNet
class ConvBlock(nn.Module):
def __init__(self, in_channel, f, filters, s):
super(ConvBlock,self).__init__()
F1, F2, F3 = filters
self.stage = nn.Sequential(
nn.Conv2d(in_channel,F1,1,stride=s, padding=0, bias=False),
nn.BatchNorm2d(F1),
nn.ReLU(True),
nn.Conv2d(F1,F2,f,stride=1, padding=True, bias=False),
nn.BatchNorm2d(F2),
nn.ReLU(True),
nn.Conv2d(F2,F3,1,stride=1, padding=0, bias=False),
nn.BatchNorm2d(F3),
)
self.shortcut_1 = nn.Conv2d(in_channel, F3, 1, stride=s, padding=0, bias=False)
self.batch_1 = nn.BatchNorm2d(F3)
self.relu_1 = nn.ReLU(True)
def forward(self, X):
X_shortcut = self.shortcut_1(X)
X_shortcut = self.batch_1(X_shortcut)
X = self.stage(X)
X = X + X_shortcut
X = self.relu_1(X)
return X
class IndentityBlock(nn.Module):
def __init__(self, in_channel, f, filters):
super(IndentityBlock,self).__init__()
F1, F2, F3 = filters
self.stage = nn.Sequential(
nn.Conv2d(in_channel,F1,1,stride=1, padding=0, bias=False),
nn.BatchNorm2d(F1),
nn.ReLU(True),
nn.Conv2d(F1,F2,f,stride=1, padding=True, bias=False),
nn.BatchNorm2d(F2),
nn.ReLU(True),
nn.Conv2d(F2,F3,1,stride=1, padding=0, bias=False),
nn.BatchNorm2d(F3),
)
self.relu_1 = nn.ReLU(True)
def forward(self, X):
X_shortcut = X
X = self.stage(X)
X = X + X_shortcut
X = self.relu_1(X)
return X
class ResModel(nn.Module):
def __init__(self, n_class):
super(ResModel,self).__init__()
self.stage1 = nn.Sequential(
nn.Conv2d(3,64,7,stride=2, padding=3, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(True),
nn.MaxPool2d(3,2,padding=1),
)
self.stage2 = nn.Sequential(
ConvBlock(64, f=3, filters=[64, 64, 256], s=1),
IndentityBlock(256, 3, [64, 64, 256]),
IndentityBlock(256, 3, [64, 64, 256]),
)
self.stage3 = nn.Sequential(
ConvBlock(256, f=3, filters=[128, 128, 512], s=2),
IndentityBlock(512, 3, [128, 128, 512]),
IndentityBlock(512, 3, [128, 128, 512]),
IndentityBlock(512, 3, [128, 128, 512]),
)
self.stage4 = nn.Sequential(
ConvBlock(512, f=3, filters=[256, 256, 1024], s=2),
IndentityBlock(1024, 3, [256, 256, 1024]),
IndentityBlock(1024, 3, [256, 256, 1024]),
IndentityBlock(1024, 3, [256, 256, 1024]),
IndentityBlock(1024, 3, [256, 256, 1024]),
IndentityBlock(1024, 3, [256, 256, 1024]),
)
self.stage5 = nn.Sequential(
ConvBlock(1024, f=3, filters=[512, 512, 2048], s=2),
IndentityBlock(2048, 3, [512, 512, 2048]),
IndentityBlock(2048, 3, [512, 512, 2048]),
)
self.pool = nn.AvgPool2d(2,2,padding=1)
self.fc = nn.Sequential(
nn.Linear(8192,n_class)
)
def forward(self, X):
out = self.stage1(X)
out = self.stage2(out)
out = self.stage3(out)
out = self.stage4(out)
out = self.stage5(out)
out = self.pool(out)
out = out.view(out.size(0),8192)
out = self.fc(out)
return out
训练和预测
device = 'cuda'
def test():
model.eval() #需要说明是否模型测试
eval_loss = 0
eval_acc = 0
for data in test_loader:
img,label = data
img = img.float().to(device)
label = label.long().to(device)
out = model(img) #前向算法
loss = criterion(out,label) #计算loss
eval_loss += loss.item() * label.size(0) #total loss
_,pred = torch.max(out,1) #预测结果
num_correct = (pred == label).sum() #正确结果
eval_acc += num_correct.item() #正确结果总数
print('Test Loss:{:.6f},Acc: {:.6f}'
.format(eval_loss/ (len(test_dataset)),eval_acc * 1.0/(len(test_dataset))))
model = ResModel(6)
model = model.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=learning_rate, momentum=0.8)
#开始训练
for epoch in range(num_epocher):
model.train()
running_loss = 0.0
running_acc = 0.0
for i,data in enumerate(train_loader,1):
img,label = data
img = img.float().to(device)
label = label.long().to(device)
#前向传播
out = model(img)
loss = criterion(out,label) #loss
running_loss += loss.item() * label.size(0)
_,pred = torch.max(out,1) #预测结果
num_correct = (pred == label).sum() #正确结果的数量
running_acc += num_correct.item() #正确结果的总数
optimizer.zero_grad() #梯度清零
loss.backward() #后向传播计算梯度
optimizer.step() #利用梯度更新W,b参数
#打印一个循环后,训练集合上的loss和正确率
if (epoch+1) % 1 == 0:
print('Train{} epoch, Loss: {:.6f},Acc: {:.6f}'.format(epoch+1,running_loss / (len(train_dataset)),
running_acc / (len(train_dataset))))
test()
实验1000张图片作为训练集,120张图片作为测试集,在使用GPU的情况下几分钟即可完成100次迭代,使用CPU两三个小时也能训练完成,训练好的模型约100M左右,在测试集准确率基本稳定在97.5%。对比简单的网络结构,ResNet50可以较短的时间内达到较好的效果。
瓶颈层
使用Pytorch实现ResNet时,需要注意卷积层间的对接,比如在第二层conv2.x中有3个Block,Block内部3层通道输出分别是64,64,256,于是有64->64->256,较容易理解;而第二层的3个Block之间,需要将256再转回64,在第二层内部,通道变化是64->64->256->64->64->256->64->64->256。
其数据流变化如下图所示:

block中的三个卷积层:第一层,卷积核1x1用于实现通道数转换,第二层3x3实现特征提取,第三层将通道数转换成目标大小。
不同的块内结构是Resnet50与Resnet34的主要区别:
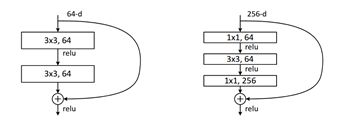
不同的结构,在Block块数相同,且参数规模相似的情况下,Resnet34提取512个特征(输出通道数),而ResNet50能提取2048个特征。从论文中可以看到同结构的对比效果。
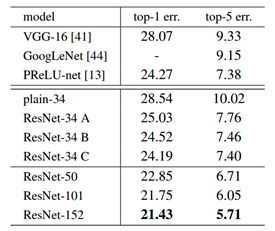
论文地址:https://arxiv.org/pdf/1512.03385.pdf
在图像处理中卷积核是四维的,其大小为:卷积核长x卷积核宽x输入通道数x输出通道数。在数据处理后期通道数越来越大,因此左图中的结构在层数多,输出特征多的情况下,参数将变得非常庞大;而右图限制了3x3卷积处理的通道数,1x1的卷积操作运算量又比较小,有效地解决了这一问题。
调试方法
搭建大型网络时,数据在网络中逐层处理,常出现相邻层之间数据接口不匹配的问题。在本例中可对照官方版本的ResNet结构排查问题,使用下面程序可打印出torchvision中ResNet的网络结构。
import torchvision
resnet50 = torchvision.models.resnet.ResNet(torchvision.models.resnet.Bottleneck,[3, 4, 6, 3],1000)
res_layer1 = torch.nn.Sequential(resnet50.conv1, resnet50.maxpool, resnet50.layer1)
img = torch.rand((2, 3, 224, 224)) # 生成图片
print(res_layer1(img).shape) # 查看第一层输出数据的形状
print(res_layer1) # 查看第一层网络结构