Python海量数据处理之_Hadoop&Spark
1. 说明
前篇介绍了安装和使用Hadoop,本篇将介绍Hadoop+Spark的安装配置及如何用Python调用Spark。
当数据以TB,PB计量时,用单机处理数据变得非常困难,于是使用Hadoop建立计算集群处理海量数据,Hadoop分为两部分,一部分是数据存储HDFS,另一部分是数据计算MapReduce。MapReduce框架将数据处理分成map,reduce两段,使用起来比较麻烦,并且有一些限制,如:数据都是流式的,且必须所有Map结束后才能开始Reduce。我们可以引入Spark加以改进。
Spark的优点在于它的中间结果保存在内存中,而非HDFS文件系统中,所以速度很快。用Scala 语言可以像操作本地集合对象一样轻松地操作分布式数据集。虽然它支持中间结果保存在内存,但集群中的多台机器仍然需要读写数据集,所以它经常与HDFS共同使用。因此,它并非完全替代Hadoop。
Spark的框架是使用Scala语言编写的,Spark的开发可以使用语言有:Scala、R语言、Java、Python。
2. Scala
Scala是一种类似java的编程语言,使用Scala语言相对来说代码量更少,调用spark更方便,也可以将它和其它程序混用。
在不安装scala的情况下,启动hadoop和spark,python的基本例程也可以正常运行。但出于进一步开发的需要,最好安装scala。
(1) 下载scala
http://www.scala-lang.org/download/
我下载的是与spark中一致的2.11版本的非源码tgz包
(2) 安装
$ cd /home/hadoop #用户可选择安装的文件夹
$ tar xvzf tgz/scala-2.11.12.tgz
$ ln -s scala-2.11.12/ scala
在.bashrc中加入
export PATH=/home/hadoop/scala/bin:$PATH
3. 下载安装Spark
(1) 下载spark
http://spark.apache.org/downloads.html
我下载的版本是:spark-2.2.1-bin-hadoop.2.7.tgz
(2) 安装spark
$ cd /home/hadoop #用户可选择安装的文件夹
$ tar xvzf spark-2.2.1-bin-hadoop2.7.tgz
$ ln -s spark-2.2.1-bin-hadoop2.7/ spark
在.bashrc中加入
export SPARK_HOME=/home/hadoop/spark
export PATH=$SPARK_HOME/bin:$PATH
(3) 配置文件
不做配置,pyspark可以在本机上运行,但不能使用集群中其它机器。配置文件在$SPARK_HOME/conf/目录下。
i. 配置spark-env.sh
$ cd $SPARK_HOME/conf/
$ cp spark-env.sh.template spark-env.sh
按具体配置填写内容
export SCALA_HOME=/home/hadoop/scala
export JAVA_HOME=/exports/android/jdk/jdk1.8.0_91/
export SPARK_MASTER_IP=master
export SPARK_WORKER_MEMORY=1g
export HADOOP_CONF_DIR=/home/hadoop/hadoop/etc/hadoop/
ii. 设置主从服务器slave
$ cp slaves.template slaves
在其中列出从服务器地址,单机不用设
iii. 设置spark-defaults.conf
$ cp conf/spark-defaults.conf.template conf/spark-defaults.conf
按具体配置填写内容
spark.master spark://master:7077
spark.eventLog.enabled false
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.driver.memory 1g
spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"
(4) 启动
运行spark之前,需要运行hadoop,具体见之前的Hadoop文档
$ $SPARK_HOME/sbin/start-all.sh
该脚本启动了所有master和workers,在本机用jps查看,增加了Worker和Master,
4. 命令行调用
下面我们来看看从程序层面如何使用Spark
(1) 准备工作
在使用相对路径时,系统默认是从hdfs://localhost:9000/中读数据,因此需要先把待处理的本地文件复制到HDFS上,常用命令见之前的Hadoop有意思。
$ hadoop fs -mkdir -p /usr/hadoop
$ hadoop fs -copyFromLocal README.md /user/hadoop/
(2) Spark命令行
$ pyspark
>>> textFile = spark.read.text("README.md")
>>> textFile.count() # 返回行数
>>> textFile.first() # 返回第一行
>>> linesWithSpark = textFile.filter(textFile.value.contains("Spark")) # 返回所有含Spark行的数据集
5. 程序
(1) 实现功能
统计文件中的词频
(2) 代码
这里使用了spark自带的例程 /home/hadoop/spark/examples/src/main/python/wordcount.py,和之前介绍过的hadoop程序一样,同样是实现的针对key,value的map,reduce,一个文件就完成了,看起来更简徢更灵活,像是hadoop自带MapReduce的加强版。具体内容如下:
from __future__ import print_function
import sys
from operator import add
from pyspark.sql import SparkSession
if __name__ == "__main__":
if len(sys.argv) != 2:
print("Usage: wordcount ", file=sys.stderr)
exit(-1)
spark = SparkSession\
.builder\
.appName("PythonWordCount")\
.getOrCreate()
lines = spark.read.text(sys.argv[1]).rdd.map(lambda r: r[0])
counts = lines.flatMap(lambda x: x.split(' ')) \
.map(lambda x: (x, 1)) \
.reduceByKey(add)
output = counts.collect() # 收集结果
for (word, count) in output:
print("%s: %i" % (word, count))
spark.stop() (3) 运行
spark-submit命令在$HOME_SPARK/bin目录下,之前设置了PATH,可以直接使用
$ spark-submit $SPARK_HOME/examples/src/main/python/wordcount.py /user/hadoop/README.md
参数是hdfs中的文件路径。
此时访问$SPARK_IP:8080端口,可以看到程序PythonWordCount正在hadoop中运行。
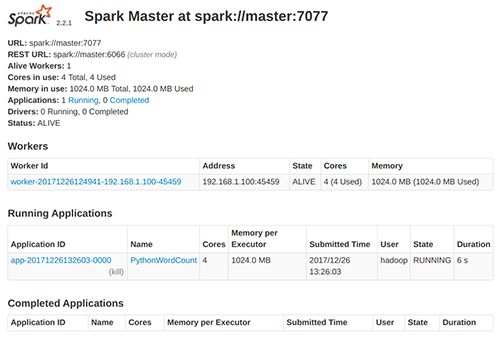
6. 多台机器上安装Spark以建立集群
和hadoop的集群设置类似,同样是把整个spark目录复制集群中其它的服务器上,用slaves文件设置主从关系,然后启动$SPARK_HOME/sbin/start-all.sh。正常开启后可以通过网页查看状态:SparkMaster_IP:8080
7. 参考
(1) 官方帮助文档,具体见其python部分
http://spark.apache.org/docs/latest/quick-start.html
(2) Hadoop2.7.3+Spark2.1.0 完全分布式环境 搭建全过程
https://www.cnblogs.com/purstar/p/6293605.html
技术文章定时推送
请关注公众号:算法学习分享