《Feature Squeezing: Detecting Adversarial Examples in Deep Neural Networks》论文阅读报告
0 论文整体信息
论文题目:Feature Squeezing: Detecting Adversarial Examples in Deep Neural Networks
作者:Weilin Xu, David Evans, Yanjun Qi
机构:University of Virginia(美国弗吉尼亚大学)
出处:NDSS 2018
论文研究内容:DNNs(深度神经网络)经常会被Adversarial Examples(对抗性样例)愚弄,之前的一些预防方法都会修改网络本身,且开销较大,本文作者提出了一种称为 “feature squeezing” 的新策略,通过修改输入样例,来对对抗性样例做出精确的检测,为合法样本输出正确的预测,并拒绝对抗样本的输入,从而用于加强DNNs系统。
论文研究方法:论文的核心思想是检测出对抗样本,进而拒绝其输入。检测方法基于作者设计的一个Feature Squeezing检测框架。利用基于“feature squeezing” 提出的两种方法:Color Depth Reduction和 Spatial Smoothing对样本进行压缩,通过比较压缩后和原始样本的预测向量的差异,检测出是否是对抗样本。
本文中用于产生对抗样例的是FGSM、BIM、JSMA等11种攻击技术,用到的数据集有MNIST、CIFAR-10、ImageNet,作者评估了攻击技术产生对抗样例的精确度、压缩方法对预测模型的精确度、训练好的检测器对图像(包括合法的和对抗样本)检测精确度,以及由于无法知道对手使用的哪种攻击技术而采用了压缩器联合的检测器,并对检测精确度也进行了数据评估。
论文方法优点(创新点):之前的一些预防对抗样本的方法都会修改网络本身,且开销较大,本文作者提出的 “feature squeezing” 仅仅修改了输入样例,就能实现对对抗样本的精确检测,且相比较之前的方法,该压缩法具有更高精确性和更低成本,值得应用到图像识别中。
论文方法缺点(新方向):作者进行的一系列实验都是基于对手不会攻击我们的 “feature squeezing”方法,如果对手知道我们使用的压缩方法并攻破它,这样产生的对抗样本,利用作者提出的检测器则不再能被有效检测出,这也是以后值得深入研究的一个方向。
1 论文背景资料
1.1 神经网络
1.1.1 神经元模型
在人工智能领域,有一个方法叫机器学习。在机器学习这个方法里,有一类算法叫神经网络。神经网络中的每个单元被称为神经元,下面我们通过一个经典的神经元模型来理解神经网路的基本原理:
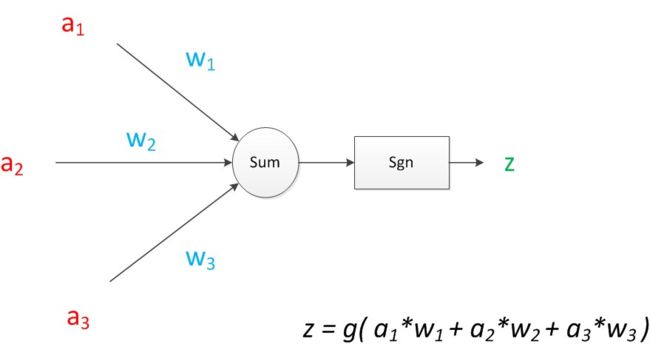
可见z是在输入和权值的线性加权和叠加了一个函数g的值。在MP模型里,函数g是sgn函数,也就是取符号函数,也是神经网络中的激活函数。
连接是神经元中最重要的东西。每一个连接上都有一个权重。一个神经网络的训练算法就是让权重的值调整到最佳,以使得整个网络的预测效果最好。
一个神经元模型的预测思路就是假设一个样本有四个属性,其中三个属性已知(也叫特征,即这里的$ a_1,a_2,a_3$),通过神经元公式计算得出未知属性(也叫目标,即这里的z)的值。
1.1.2 深度神经网络(DNN)
隐藏层比较多(大于2)的神经网络叫做深度神经网络(DNN)。DNN内部的神经网络层可以分为:输入层,隐藏层和输出层,一般第一层是输入层,最后一层是输出层,而中间的层数都是隐藏层。层与层之间是全连接的,即第i层的任意一个神经元一定与第i+1层的任意一个神经元相连。DNN结构图如图:
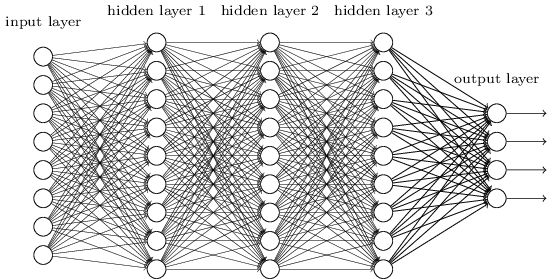
虽然DNN看起来很复杂,但是从小的局部模型来说,还是和感知机一样,即一个线性关系\(z=\sum{w_ix_i}+b_i\)加上一个激活函数\(\sigma(z)\)。当训练一个深度模型时,每一层的参数是随机赋予的,我们使用这些随机生成的参数值,来预测训练数据中的样本。每一层样本的预测目标为\(y_i\),真实目标为y。那么,定义一个值loss,计算公式为:\(loss=(y_i-y)^2\)。这个值称之为损失(loss),我们的目标就是使对所有训练数据的损失和尽可能的小。这个问题就被转化为一个优化问题,利用梯度下降的算法,在神经网络模型中,由于结构复杂,每次计算梯度的代价很大。因此还需要使用反向传播算法。
1.1.3 softmax分类器
深度学习中也是作者实验用到的一种重要分类器——softmax,在多分类的场景中使用广泛。softmax层放置在DNN的最后一层,输出一个向量,向量中每个元素都映射为[0,1]的实数,反映了第i个输入属于第i类的可能性,且进行了归一化,元素和为1。
1.2 对抗性样本
一个对抗性样本是由对手创建的输入,其目标是从目标分类器产生不正确的输出。作者将对抗性样本分为以下两大类:
(一) targeted
即对手的目标是把对抗样本分类成一个特定的输出t。
![]()
注:\(g(x')\):对抗样本的输出;
\(\Delta(x,x')\):最初输入样本和对抗样本的距离测度;
\(\varepsilon\):对手强度阈值,和距离测度共同衡量了对抗性样本和最初输入样本的高度相似性,人类肉眼几乎观察不到。
(二) untargeted
即对手的目标是把对抗样本分类成任意一个错误的输出。
![]()
无论是targeted还是untargeted,\(\Delta(x,x')\)的产生用到如下几种\(L_p\)规则:
-
\(L_\infty\)范数表示所有维度上最大变化的的度量。
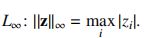
-
\(L_2\)范数对应于x和x′之间的欧几里得距离。
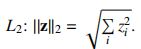
-
\(L_0\)范数x和x′之间变化的像素总数,而不是摄动量。
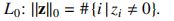
下面是基于上面分类和规范的11种攻击方法,这里就不详细介绍算法,直接进行整理如下:
-
以L范数分类如下:
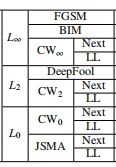
-
以是否有目标分类如下:
-
Untargeted: FGSM, BIM, DeepFool
-
Targeted (Next/Least-Likely): JSMA, Carlini-Wagner \(L_2/L_\infty/L_0\)
Next和Least-Likely指Targeted的两种不同目标。
Next:t=L+1 mod #classes;L:ground-truth类的索引。
Least-Likely(LL):\(t=min(\widehat{y})\),\(\widehat{y}\)是输入图像的预测向量。
-
1.3 之前的一些防御技术
-
对抗性训练
对抗性训练将发现的对抗性例子和对应的ground truth标签引入到训练中。
ground truth:真值,相当于为减少分歧设置的一个基准,一般用来进行误差估算和效果评价。
这项技术在预测对抗样本方面表现出鲁棒性,然而,由于对抗样本的产生和训练需要巨大的成本,且生成与对手使用相似的样本的有效性并不能很好实现。
-
梯度屏蔽
针对这种防御技术,有人提出在训练时添加一个gradient penalty term,这项技术在预测对抗样本方面表现出鲁棒性,然而牺牲了精确性;还有人提出一种“defensive distillation”策略,核心思想是隐藏该模型的梯度信息,不过提出者最后总结出由于对抗性例子的可转移性,设计用于隐藏梯度信息的方法成功的可能性有限。
-
输入变换
Bhagoji等人提出使用降维技术,例如PCA(Principal Component Analysis)来防御,该方法破坏了图片的空间结构,而且最先进的CNN模型已经不再适用; Meng and Chen又提出了训练一个自动编码器作为图像过滤器;与我们的研究方法类似,Osadchy等人提出利用二进制过滤器和中值平滑过滤器来消除对手扰动,提出通过增加攻击者的扰动强度来攻击防御,作者在本文的研究方法与其类似,只是更加关注于检测对抗样例并发现增加扰动值会导致图像的不可识别。
2 论文具体研究内容
DNNs(深度神经网络)经常会被Adversarial Examples(对抗性样例)愚弄,之前的一些预防方法都会修改网络本身,且开销较大,本文作者提出了一种称为 “feature squeezing” 的新策略,包括两种方法:reducing the color bit depth of each pixel 和 spatial smoothing,均不涉及DNN本身,而是通过修改输入样例,来对对抗性样例做出精确的检测,从而用于加强DNN系统。
相较于其他防御方法,该新策略表现出更高的精确度和更低的开销,且数据表明,上面几种方法组合起来更具优势。下面详细介绍本文的研究内容。
2.1 本文关键思想——Feature Squeezing检测框架
特征压缩检测框架如下:
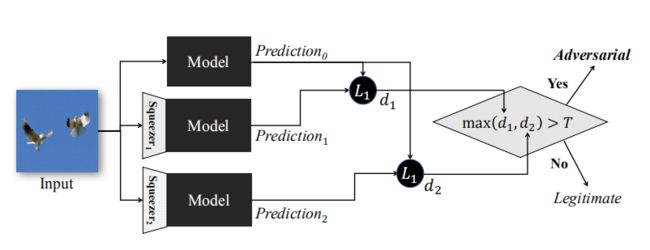
将模型对原始样本的预测与压缩后对样本的预测进行比较。如果原始输入和压缩后的输入产生了与模型实质上不同的输出,则输入可能是对抗性的。 这是由于Squeezing有降噪的功能,正常图片降噪后,和真实图片降噪后的结果差不多的,如果是对抗样例,就肯定会差比较多。通过将预测之间的差异与选定的阈值进行比较,系统会为合法样本输出正确的预测,并拒绝对抗样本的输入。
2.2 Feature Squeezing 方法介绍
-
特征压缩核心思想:特征输入空间通常不需要太大,因为过大的特征输入空间会为对手生成对抗样本提供更多可能。该策略是通过“压缩”不必要的特征来降低对手生成对抗样本的自由度。 作者提出两种压缩图像的方法:
-
Color Depth Reduction
-
原理:较大的位深度会使显示的图像更接近自然图像,但是通常不需要太大的色彩深度来解释图像。两种普遍的图像表示:8位灰度和24位彩色,例如8位表示法的每个像素就会提供\(2^8=256\)种颜色值,我们利用压缩公式会将8位缩减为i位(\(1\leq i\geq7\))。
-
实现方法:用到Python的NumPy库,将input先限制到[0,1] (整体除以255),然后乘上\((2^i-1)\),取整,再除以\((2^i-1)\)限制到[0,1],这样就将原本\(2^8\)表示的图像降到了\(2^i\)。
-
实验:作者在三种流行的图像分类数据集(MNIST,CIFAR-10和ImageNet)研究了位深度压缩。
在MNIST数据集上选择0-9的数字图像,所有图像都是28x28像素,每像素是8位灰度表示的,作者用了60000张图像进行训练,10000张进行测试。
在CIFAR-10数据集上包括60000张图像,所有图像是32x32像素,每像素是24位表示的。ImageNet上的50000张图像用于训练,5000张用于验证,图像是224x224像素,每像素24位表示的。
如下图展示了利用位深度压缩方法后三种数据集上数字0图像的变化,下面的数字i表示图像维度。可见,减少颜色位后,除了灰度表示法,在8-4位表示中肉眼很难辨别出不同,但如果位深度小于4,确实会造成一些人类可观察到的损失。这是因为即使减少到每个通道相同的位数,我们也会丢失更多的彩色图像信息。经过之后实验发现位深度压缩到4位足以消除许多对抗样本,同时保留了对正常图像的准确性。即证明了降低位深度确实可以在不损害分类精度的情况下减小对抗样本生成的可能性。

-
-
Spatial Smoothing
Local Smoothing
-
原理:局部平滑利用相邻像素来平滑每个像素。通过选择加权相邻像素的不同机制,可以将局部平滑方法设计为Gaussian smoothing, mean smoothing or the median smoothing(高斯平滑,均值平滑或中值平滑方法)。中值平滑在应对由\(L_0\)范数的生成的对抗样本时特别有效。本文使用的就是中值平滑。中值平滑是在图像的每个像素上运行一个滑动窗口,其中中心像素被窗口内相邻像素的中值代替。 中值平滑没有减少图像中像素的数量,而是将像素值分布在附近的像素上。边缘上的像素采用反射填充。 中值平滑实质上是通过使相邻像素更相似来将特征进行压缩。中值平滑特别有效地去除图像中稀疏出现的黑白像素(被称为椒盐噪声),同时很好地保留对象的边缘。
相当于卷积神经网络的pooling,取的是\(n\times n\)大小filter的中值,替代原来区域的值。对于原理的理解是,相邻区域的像素点,值其实是相似相关的,所以我们对整张图smoothing以后不会影响到最后的总体结果,但是将那些加进去的noise去除了。
-
实现方法:在SciPy库上实验,选择2×2滑动窗口,中心像素总是位于右下角。当一个窗口中由于像素个数为偶数而有两个等中值时,我们(任意)使用较大的值作为中值。
-
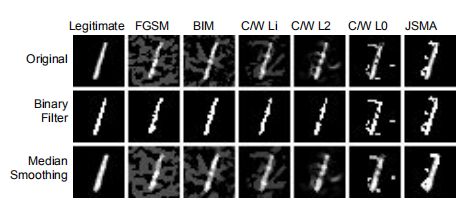
实验:如下图第一行是合法样本和各种攻击产生的对抗样本,下面是Binary Filter(属于颜色位深度压缩)和Median Smoothing(属于Spatial Smoothing)两种方法压缩后的图像:
Non-local Smoothing
-
原理:它是在更大的区域上平滑相似像素,对于给定的图像色块,非局部平滑可在图像的较大区域中找到几个相似的色块,并用这些相似色块的平均值替换中心色块。衡量相似的方法也有Gaussian, mean,median。
-
实现方法:本文使用高斯核的一种变体。非局部平滑方法的参数通常包括搜索窗口大小(用于搜索相似块的较大区域),块(patches)大小和滤波器强度。滤波器“non-local means (a-b-c)”的a表示搜索窗口的大小axa,b表示块大小bxb,c表示滤波器强度。
采用OpenCV中实现的 fast non-local means denoising(快速非局部均值去噪方法)。首先将一幅彩色图像转换为CIELAB的颜色空间,然后分别对L和AB分量进行去噪,然后转换回RGB空间。
-
2.3 Feature Squeezing方法评估
-
11种攻击方法花费成本、创建对抗样本成功率、预测可信度等的评估结果:
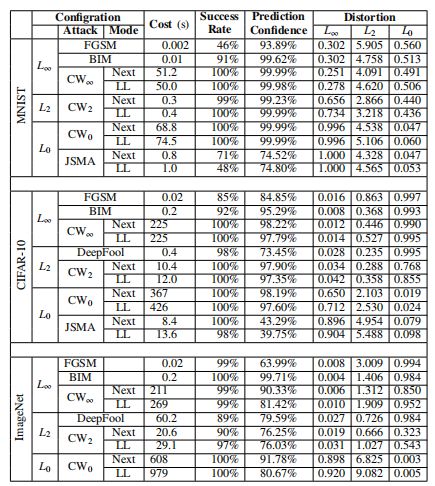
由表发现:大多数攻击在产生对抗样例方面都是有效的,CW攻击表现出更小的失真(distortion),但产生的成本要高得多。FGSM、DeepFool和JSMA经常产生一些低可信度的对抗性例子。
-
不同Feature Squeezing方法的模型精确性的评估结果:
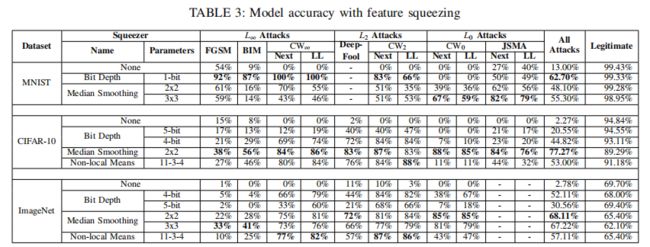
分析:
- 在MNIST数据集上,Color Depth Reduction几乎没有降低合法输入的精确性(仅从99.43%降到99.33%),且对\(L_\infty\)和\(L_2\)攻击最为有效(可见加粗数据),对\(L_0\)攻击预测精确性很低,而Median smoothing 的3x3压缩对所有\(L_0\)攻击预测精确性表现良好,且数据显示3x3窗口更加有效。
- 在CIFAR-10 and ImageNet数据集上,Color Depth Reduction包括了4位和5位的压缩,经过数据比较,4位压缩对所有攻击产生的对抗样例的预测精确性较5位更高,Median smoothing 的2x2窗口压缩对\(L_0\)攻击预测精确性表现最好。
- Non-local smoothing压缩对除了\(L_0\)攻击外其他的对抗样例也表现出较好的预测精确度,且对合法样本预测精确率也很高。
-
将压缩方法和先前的对抗性训练组合起来进行防御的评估
正如前面背景资料介绍,对抗性训练是之前最好的防御技术,作者考虑将同样表现突出的压缩方法(这里,我们以位深度压缩为例)和对抗性训练进行组合,对抗样本由FGSM(对抗强度\(\varepsilon\)设为0-0.4的范围)和基于PGD(之前的研究中用于对抗性训练)的攻击产生,下图为对两种攻击下组合防御方法预测对抗样本的精确性曲线图:
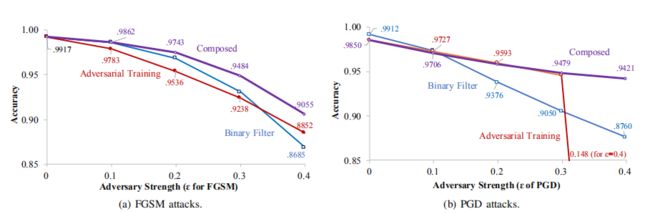
分析:
从整体可发现bit-depth reduction比adversarial training预测精确度更高,且二者的组合总是最有效。
我们其实可以考虑将两者进行组合来对对抗样本进行防御,尽管adversarial training成本较高,但效果显著。
2.4 Feature Squeezing检测对抗样本
通过上面的评估结果,可见Feature Squeezing能够对许多对抗性的样本进行准确的模型预测,而对合法的例子的预测精度几乎没有降低。这样就可以使用图中介绍的框架来检测对抗性输入。检测思想如上面2.1节所描述,如果是合法输入,压缩后的模型预测和原图预测应该是相似的,而如果是对抗输入,压缩后会产生实质性的差别,因此很容易被检测出来。
检测框架:
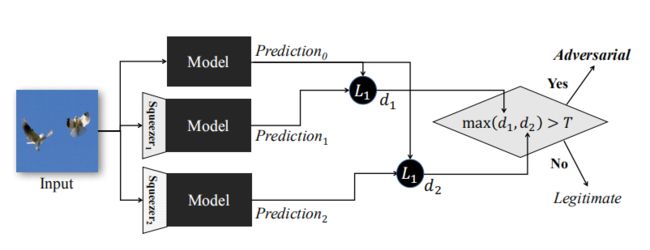
检测方法:
-
DNN分类器产生的预测向量往往代表了输入样本的概率分布,因此比较初始输入和压缩后样本的区别可以转化为比较概率向量,作者采用了\(L_1\)范数来比较二者的概率,公式如下:
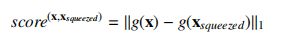
- 这里g(x)是softmax层产生的DNN模型的输出向量,它的第i个元素描述了输入x在第i类中的可能性。这里作者将\(L_1score\)映射为0-2区间,值越大意味着初始输入和压缩后样本的区别越大。且不出所料,实验数据显示合法性样本的\(L_1score\)接近0,而对抗样本的\(L_1score\)几乎接近2.
- 检测器的有效性取决于阈值的选择。
-
由于我们不能明确对手使用的哪种攻击,因此需要用到联合检测,即将多种有效压缩方法组合起来,联合检测公式为

- 这里选择最大值,最高的\(L_1score\)能够几乎无误的体现出差异。
实验所需配置:
-
作者采用的数据集及对应的DNN模型:
Datasets Models MNIST 7-layer-CNN CIFAR-10 DenseNet ImageNet MobileNet -
用于产生对抗样例的攻击技术:
以L范数分类如下:
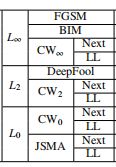
以是否有目标分类如下:
- Untargeted: FGSM, BIM, DeepFool
- Targeted (Next/Least-Likely): JSMA, Carlini-Wagner \(L_2/L_\infty/L_0\)
-
检测器的训练
一个经典的检测器应该具备较高的精确性和较低的失真率,因此,我们选择阈值不能直接低于5%,而是在合法样本上低于5%,这样训练阈值不会依赖于对抗样本。
-
检测器的验证
作者使用上面选定的阈值在以下三种情况下测试检测率:
- SAEs(successful adversarial examples):成功产生的对抗样本;
- FAEs( failed adversarial examples):失败的对抗样本;
- legitimate examples(产生 false positive rates/FPR):这里可能会判断错误,导致失真率。
除非有明确说明,这里的“检测率”是指在成功的对抗样本上的检测率。
实验结果
-
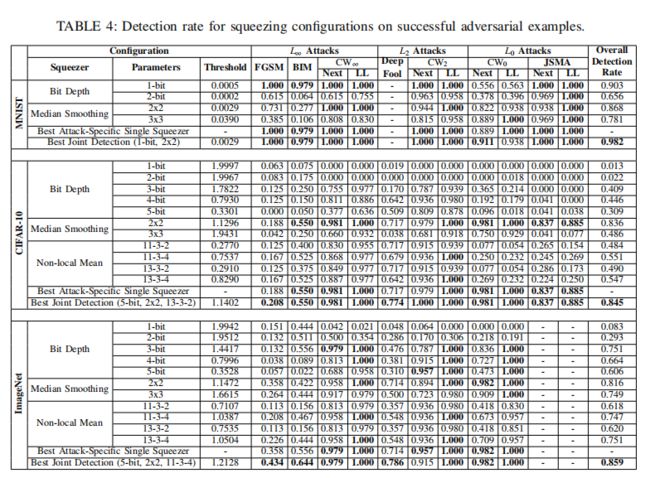
下图所示为在不同攻击产生的成功对抗样本中利用不同压缩方法进行检测的成功率,在每个数据集上,首先列出独立压缩方法的检测率,下面是将效果最好的两种压缩方法进行组合进行的检测率数据:
-
分析
- MNIST的最佳比特深度缩减是将颜色位压缩为1位,对所有\(L_\infty\)和\(L_2\)攻击的检测至少达到97.87%,对7次攻击的检测率达到100%。但是,它对\(CW_0\)攻击不那么有效,因为这些攻击会对少量像素进行较大的更改。相反,3×3中值平滑对L0攻击的检测效果最好,检测率在88%以上。
- 对于CIFAR-10,除了DeepFool(非局部方法检测效果最好)外,2×2中值平滑是检测所有攻击的最佳独立压缩器。
- ImageNet数据集上,几种压缩方法有着相似的检测效果。
- 上图中的阈值可以用来衡量对抗样本和原始样本的差异,这正是检测框架中的阈值T,阈值越小代表检测器对对抗样本的敏感度越灵敏,检测器性能越好。例如,对于MNIST上的二进制滤波器,极小的阈值0.0005就足以产生低于5%的失真率,这意味着压缩对合法示例的影响可以忽略不计,95%的合法示例基于\(L_1\)的距离得分低于0.0005。
- 通过数据对比,我们发现,FGSM和BIM检测效果不佳,作者认为原因可能是二者的攻击需要制造较大的扰动,而特征压缩器是适合小扰动的,之后的研究中可以不断改进完善使得特征压缩抵抗所有攻击都有效。
- 这里我们用到了联合检测技术(将效果最好的压缩方法组合),数据表明,每个数据集上联合检测的效果最好,作者认为原因是我们的检测器并不能明确对手用的哪种攻击技术,因此联合检测能很好地针对任一种检测出对抗样本。下面我们详细介绍联合检测技术。
多项压缩方法的联合检测
-
作者在不同数据集上分别联合了多种压缩方法对SAEs、FAEs、合法样本的失真率FPR、ROC-AUC进行了数据统计,如图:
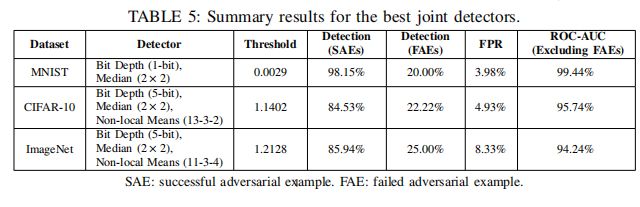
这里的 ROC-AUC scores指体现出学习器的泛化能力,来衡量模型性能。作者选择去除FAEs是由于出错的对抗样本对输出是不清楚的。实验数据表明,对于成功的对抗性样本,使用1位滤波器和2×2中值滤波器的MNIST最佳配置的检出率超过98%,而使用三种不同参数的特征压缩方法组合的其他两个数据集的检出率接近85%。
对手自适应
-
作者进行的一系列实验都是基于对手不会攻击我们的特征压缩方法,这其实在现实中有一定的风险
-
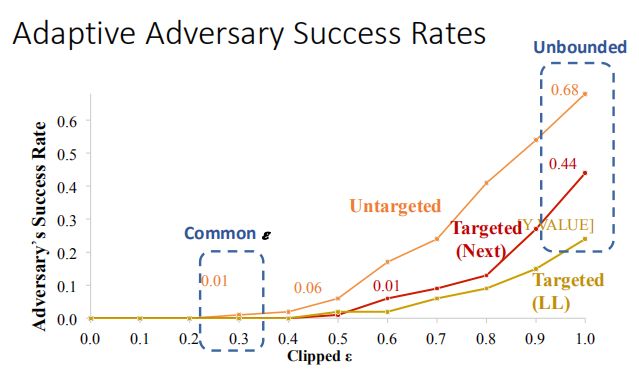
Warren He等人提出了一种自适应攻击,它可以成功地产生击败特征压缩防御的配置的对抗样本,他们的方法适应\(CW_2\)攻击(untargeted),作者将他们的模型应用到自己的检测器,修改阈值,对untargeted和targeted两类攻击进行了测试,结果如图:

\(L_2\)范数的平均值是原始输入和压缩输入的欧几里得距离,因此越小代表差异越不易被检测器发现,从而更易成功。
targeted攻击的成功率很低,targeted(next)攻击的成功率为44%,targeted(LL)攻击的成功率为24%。作者认为这些较低的对抗成功率是由于使用了不同的MNIST模型(最先进模型的代表),而且我们的检测器的阈值(0.0029)比他们使用的阈值(超过0.3076)小得多。
-
这种新方法不能很好的表现出鲁棒性,如下图,随着扰动的变化,对手成功率变化较大:
-
对策:为了抵抗这种对手自适应,作者提出一种随机方法,因为对手知道你要用的压缩方法,因此,我们可以使用加密的随机性使部署的框架不可预测,例如,使用0.5±rand(0.1)代替1位滤波器的固定0.5阈值(可以对每个像素使用不同的随机值),或者选择随机区域进行中值平滑,而不是固定的2×2区域)。
-
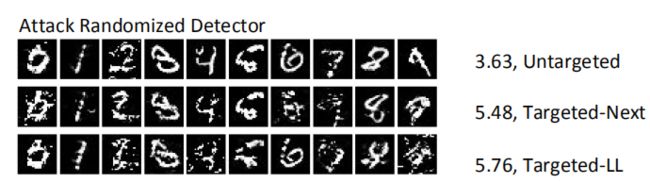
对手可能会试图通过攻击一组随机挤压器来适应这种随机性。我们考虑了一个ensemble-adaptive对手,它同时考虑了二进制滤波器的三个阈值:0.4、0.5和0.6。执行10次后,成功率增加到(46.5±2.1%,34.5±3.5%,28.5±2.1%)。然而,扰动变得更大,导致许多无法识别和可疑的图像,如图:
3 实验重现
4 实践总结
5 学习总结和建议意见
回顾这特殊的一学期,感觉网络攻防是我最大的收获了,虽然不得不提一下,确实很累,因为初次接触攻防的知识,理解起来比较吃力,而且还需要在掌握知识的基础上做实践,很多时候其实是理论知识一知半解,在做实践的过程中才能理解。而实践往往是让我一头雾水,对于我这个动手能力差的学生来说这学期着实是一种挑战,每次实践我几乎都需要参考大佬们的博客,但是我没有机械式地跟着做,我一定会要求自己理解每个实验的原理和操作过程,起码明白自己在干什么,以及为什么要这么做。这一学期的前12周每周都在紧张的阅读、实践,很多时候都熬夜做到两点左右,累是肯定的,但更多的是收获。
首先,很赞成老师的教学方式,网络攻防本身就是实践为主,老师安排课下自学一章节内容是很符合课程特点的,而且这确实锻炼了我逐字逐句研究知识点的能力;
其次,每周的实践就是一个不断地出错,再不断摸索解决的过程,每次遇到问题我都尽量自己解决,提升了我的动手能力和解决问题能力,当然也学到了很多网络安全相关的基础知识;
再次,老师课上又会给出一道本章知识点相关的实践题,需要我们真正掌握知识点才能顺利完成,这也督促了我每周博客一定认真对待,之后的学习中,我一定要保持这种严格要求自己、把控好时间、注意效率的良好习惯。
再提一下这次的综合实践,属实让我劳神费力了很久,但成果可喜,对我的阅读研究论文、理解总结能力都有很大的帮助,同时,也让我基本入门了神经网络这一领域,当然仅限于理论,实践方面我会进一步学习研究。
小小的建议:刚开始课堂上老师出的题都是和课本实践一样,感觉得分容易,但确实没什么用。但老师不断改进,课堂形式丰富多样,很赞,建议老师以后的课程可以穿插地稍微讲解一下重要的但教材上没有的知识点,(其实老师也提过,就是被大家无情地拒绝了,主要是综合实践这块大石头在心里悬着,也没心思接触别的知识,而且,很怕又有作业【捂眼笑】,希望老师理解)或者推荐一些值得研究的方向、书目、视频等。
最后,非常感谢王老师一学期的授课和教育,真的受益匪浅,在未来道路上,愿自己能做到不因舒适而散漫放纵,不因辛苦而放弃追求,努力做一个优秀的人。
6 参考文献
-
深度神经网络(DNN)模型与前向传播算法
-
神经网络——最易懂最清晰的一篇文章
-
零基础入门深度学习
-
ROC曲线和AUC面积理解
-
SoftMax多分类器原理及代码理解
-
小白都能看懂的softmax详解