
1、本文章介绍Scrapy爬虫框架
有的朋友可能知道,写网络爬虫的挑战之一就是你经常需要不断地重复做一些简单任务:而这些任务通常是找出页面上的所有链接、区分内链与外链、跳转到新的页面等,掌握这些基本模式非常有用。
关于Scrapy的更多介绍可参考中文网站
https://scrapy-chs.readthedocs.io/zh_CN/0.24/index.html

值得一提的是Scrapy爬虫框架,Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。此外,Scrapy 就是一个帮你大幅度降低网页链接查找和识别工作复杂度的 Python 库,它可以让你轻松地采集一个或多个域名的信息。
2、Python 3.7.4安装Scrapy
安装scrapy之前需要做以下的一些准备:
本文的操作是在win系统下进行~~
(1).安装wheel
首先,cmd(或win+r)命令下切换到Scripts文件夹下
这是我的(你的自行打开Python解释器文件夹下找到就行)
其次,输入cd C:\Users\Administrator\AppData\Local\Programs\Python\Python37-32\Scripts
最后,输入pip install wheel,出现下面的界面即为安装成功。
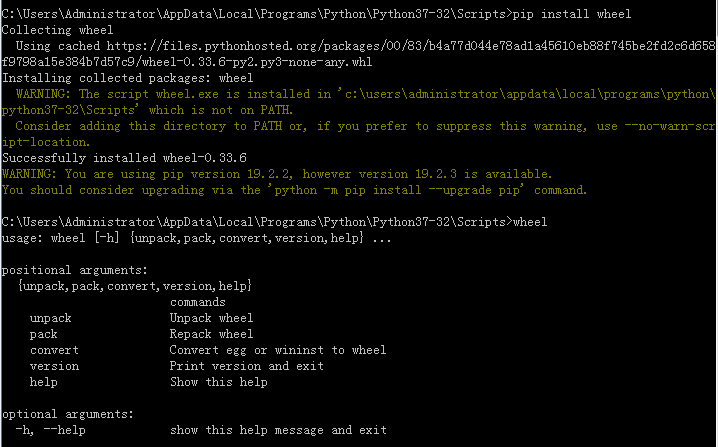
如果在上述安装过程中出现下面的错误提示

那就需要下载whl文件,下载网站是
http://www.lfd.uci.edu/~gohlke/pythonlibs/
打开以后找到符合自己的whl文件,我选择的是
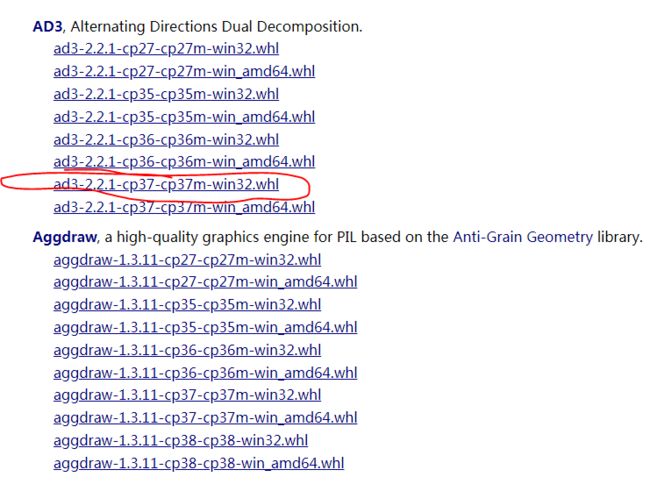
然后将下载好的whl文件拖拽到Scripts文件夹下重复上述安装命令操作就可以了。
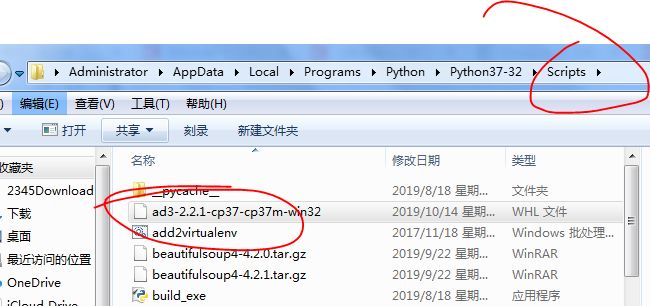
(2).安装lxml
类似(1)(这里就不截图了)输入命令pip install lxml

如果还是出错就进入网站:https://www.lfd.uci.edu/~gohlke/pythonlibs/#lxml
cp37对应py3.7,自行选择32 or 64位。
安装时,运行cmd,输入pip install + 文件路径 即可
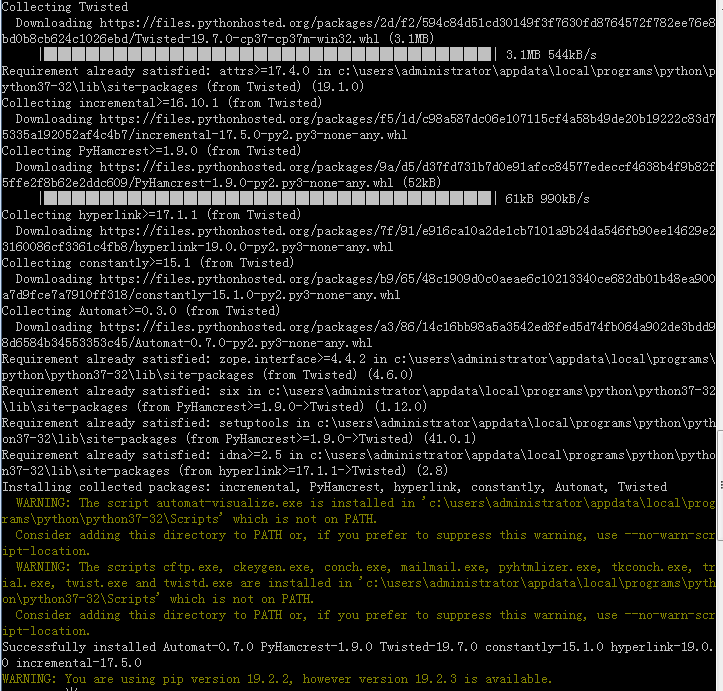
(3).安装Twisted:输入命令pip install Twisted
看到关键词Successfully 即为安装成功。
如果不成功,同(2)进入网站:https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
安装注意事项同上
(4).安装Pywin32:pip install Pywin32
进入网站,找到对应的python版本:
https://sourceforge.net/projects/pywin32/files/pywin32/Build%20221/
(5).cmd中安装Scrapy
在cmd中输入pip install scrapy,安装成功后输入scrapy测试
再次检测安装情况,出现下面提示说明已经全部安装完成。
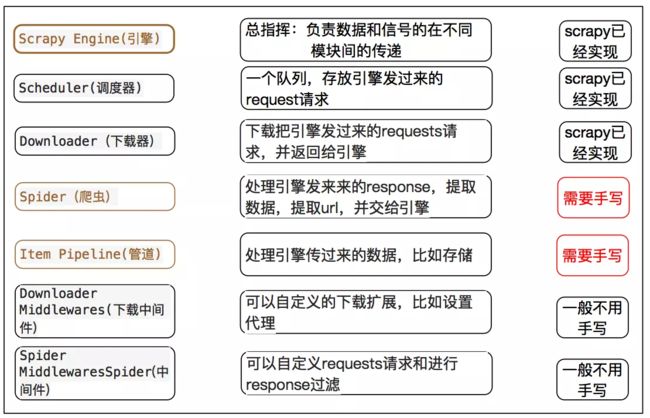
3、Scrapy框架的五大基本构成
学习使用 Scrapy 之前,我们需要先来了解一下 Scrapy 框架以及它的组件之间的交互,下面这个图展现的就是 Scrapy 的框架,包括组件以及在系统中发生的数据流。(数据流就是绿色的线,描述各个组件之间是如何通信的)
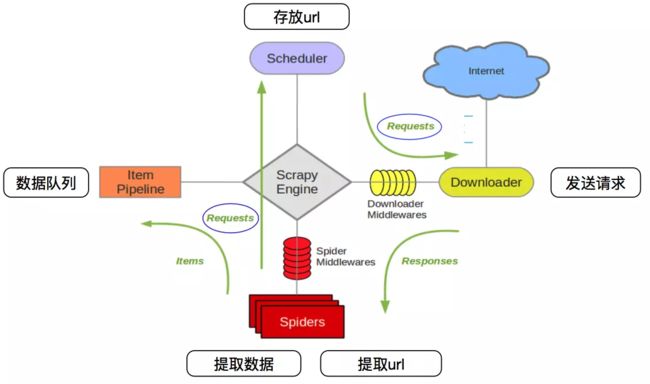
Scrapy框架主要由五大组件组成,它们分别是调度器(Scheduler)、下载器(Downloader)、爬虫(Spider)和实体管道(Item Pipeline)、Scrapy引擎(Scrapy Engine)。下面我们分别介绍各个组件的作用。
(1)、crapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
(2)、Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
(3)、Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
(4)、Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),
(5)、Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.
(6)、Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。
(7)、Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)。图表如下:
4、Scrapy请求发出去的整个流程
Scrapy运行时,请求发出去的整个流程大概如下:
1.首先爬虫将需要发送请求的url(requests)经引擎交给调度器;
2.排序处理后,经ScrapyEngine,DownloaderMiddlewares(有User_Agent, Proxy代理)交给Downloader;
3.Downloader向互联网发送请求,并接收下载响应.将响应经ScrapyEngine,可选交给Spiders;
4.Spiders处理response,提取数据并将数据经ScrapyEngine交给ItemPipeline保存;
5.提取url重新经ScrapyEngine交给Scheduler进行下一个循环。直到无Url请求程序停止结束。
5、Scrapy抓取一个网站的步骤及项目的创建
使用 Scrapy抓取一个网站一共分为四个步骤:
a–创建一个Scrapy项目;
b–定义Item容器;
c–编写爬虫;
d–存储内容。
下面以创建一个项目为例子
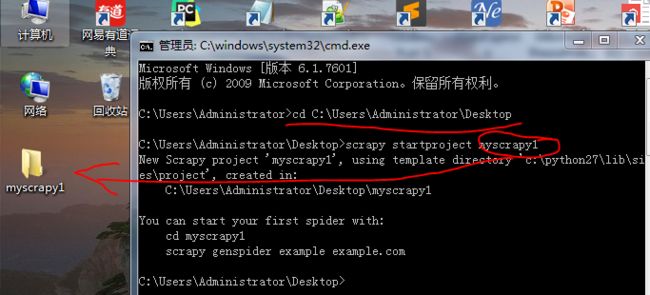
a、第一步要做的就是运行命令行,Scrapy 是命令行的,在爬取之前,我们要先创建一个 Scrapy 项目,我们来到桌面,运行 scrapy startproject myscrapy1,回车之后,在桌面就出现了 tutorial 文件夹。
打开这个文件夹就是按照下面的形式存储的:
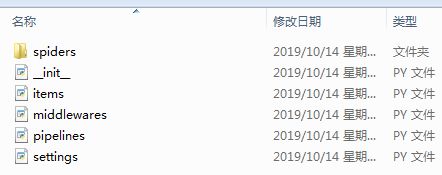
备注:scrapy.cfg 是项目的配置文件(暂时不用,保持默认即可)
myscrapy1子文件夹 存放的是模块的代码,也是我们要填充的代码
items.py 是项目中的容器.
b、步骤二:定义 Item 容器~未完待续
每日三道题, 笔试面试不吃亏:
题目16:输入一行字符,分别统计出其中英文字母、空格、数字和其它字符的个数。
程序分析:利用 while 或 for 语句,条件为输入的字符不为 '\n'。
使用 while 循环
import string
s = input('请输入一个字符串:\n')
letters = 0
space = 0
digit = 0
others = 0
i=0
while i < len(s):
c = s[i]
i += 1
if c.isalpha():
letters += 1
elif c.isspace():
space += 1
elif c.isdigit():
digit += 1
else:
others += 1
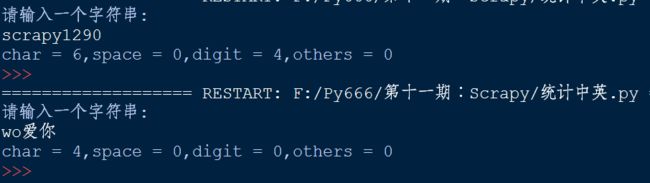
print ('char = %d,space = %d,digit = %d,others = %d' % (letters,space,digit,others))
运行结果:
使用 for 循环
import string
s = input('请输入一个字符串:\n')
letters = 0
space = 0
digit = 0
others = 0
for c in s:
if c.isalpha():
letters += 1
elif c.isspace():
space += 1
elif c.isdigit():
digit += 1
else:
others += 1
print ('char = %d,space = %d,digit = %d,others = %d' % (letters,space,digit,others))
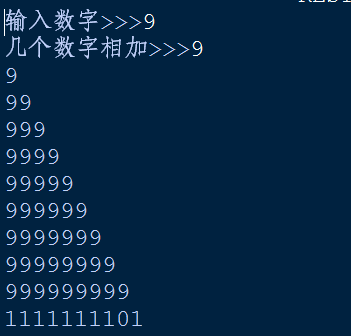
题目17:求s=a+aa+aaa+aaaa+aa...a的值,其中a是一个数字。例如2+22+222+2222+22222(此时共有5个数相加),几个数相加由键盘控制。
程序分析:关键是计算出每一项的值。
a=input('输入数字>>>')
count=int(input('几个数字相加>>>'))
ret=[]
for i in range(1,count+1):
ret.append(int(a*i))
print(ret[i-1])
print(sum(ret))
运行结果:
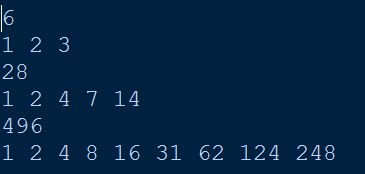
题目18:一个数如果恰好等于它的因子之和,这个数就称为"完数"。例如6=1+2+3.编程找出1000以内的所有完数。
from sys import stdout
for j in range(2,1001):
k = []
n = -1
s = j
for i in range(1,j):
if j % i == 0:
n += 1
s -= i
k.append(i)
if s == 0:
print (j)
for i in range(n):
stdout.write(str(k[i]))
stdout.write(' ')
print ("完数为:",k[n])
运行结果:
扫码关注我,一起交流学习
