2019/06/14日知识总结
1、os和os.path

2、tuple、list、dict和set的区别
tuple是不可变类型,大小固定,而list是可变类型、数据可以动态变化;
元组是不可变对象,对象一旦生成,它的值将不能更改;列表是可变对象,对象生成后可以对其进行更改、添加、删除和清空排序操作;
集合可以去重、求集合之间的交集、并集和差集等等;
3、浅拷贝和深拷贝
python中的赋值实际为对象的引用,当创建一个对象,然后把它赋值给另个变量的时候,python并没有拷贝这个对象,而只是拷贝这个对象的引用;直接赋值默认拷贝对象的引用而已,原始列表改变被赋值的对象也会改变;浅拷贝是没有拷贝子对象,所以原始数据改变子对象会改变;深拷贝则二者无任何关系;即:浅拷贝藕断丝连、深拷贝毫无关系二者;
4、sort和sorted的区别
sort 与 sorted 区别:
sort 是应用在 list 上的方法,属于列表的成员方法,sorted 可以对所有可迭代的对象进行排序操作。
list 的 sort 方法返回的是对已经存在的列表进行操作,而内建函数 sorted 方法返回的是一个新的 list,而不是在原来的基础上进行的操作。
sort使用方法为ls.sort(),而sorted使用方法为sorted(ls)

5、redis哨兵和集群
REDIS提供非常丰富的数据结构如dict、string、Hash、lsit、set、sorted set;
set 关键字 关键字值
get 关键字
REDIS的持久化:记录每次对服务器写的操作,当服务器重启的时候会重新执行这些命令来恢复原始的数据;
redis作为一种NoSQL数据库,其提供了一种高效的缓存方案,在数据存储上,其运行时将数据存储在内存中,以实现数据的高效读写,并且根据定制的持久化规则不同,其会不定期的将数据持久化到硬盘中;
REDIS的单例模式:
REDIS的安装make install,make是gcc中的一个命令,安装REDIS之前必须确保机器安装了gcc;编译完成之后在src目录下执行./redis-server启动REDIS,然后新开一个窗口执行./redis -cli即可连接启动的REDIS服务;REDIS的连接方式:./src/redis-server redis.conf中可以查看配置文件、连接命令:./src/redis -cli -h 127.0.0.1 -p 6379。
优点提供了一种数据缓存方式和丰富的数据操作API,缺点是将数据完全存储在单个REDIS中主要存在两个问题:数据备份和数据量较大造成的性能降低;
REDIS的主从模式:
主从模式指的是使用一个REDIS实例作为主机,其余的实体作为备份机,主机和从机的数据完全一致,主机支持数据的写入和读取等各项操作,而从机则支持与主机数据的同步和读取。即客户端可以将数据写入到主机,由主机自动将数据的写入操作同步到从机;主从模式很好的解决了数据备份问题,并且由于主从服务数据几乎是一致的,因而可以将写入数据的命令发送给主机执行,而读取数据的命令发送给不同的从机执行,从而达到读写分离的目的;
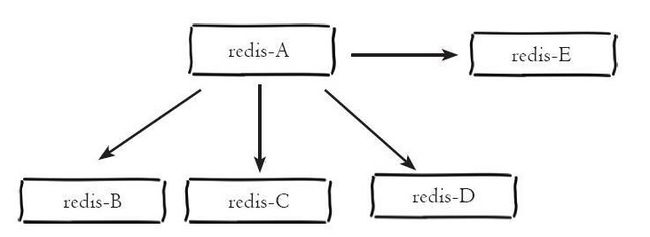
从机的配置文件中可以使用slaveof命令来指定当前节点称为某个节点的从节点;
有点解决了数据备份和单例可能存在的性能问题,但是其也引入了新的问题;即由于主从模式配置了三个REDIS实例,并且每个实例都使用不同的IP和端口号。且主从模式下可以将读写操作分配给不同的实例进行从而达到提高系统吞吐量的目的,但正因为如此造成使用上的不方便,因为每个客户端连接REDIS实例的时候都指定了IP和端口号,如果所连接的REDIS实例因为故障下线了,而主从模式没提供一定的手段通知客户端另外可连接的客户端的地址,因而需要手动更改客户端配置重新连接,另外主从模式下,如果主节点由于故障下线了,那么从节点因为没有主节点而同步中断,因而需要人工进行故障转移工作。
REDIS的哨兵模式:
哨兵模式解决了上述问题,每个哨兵节点其实就是一个REDIS实例,与主从节点不同的是哨兵节点作用是用于监控REDIS数据节点的,而哨兵节点集合则表示监控一组主从REDIS实例多个哨兵监控节点的集合,比如有主节点master和从节点slave1和slave2,为了监控这三个主从节点配置哨兵1、哨兵2和哨兵3;
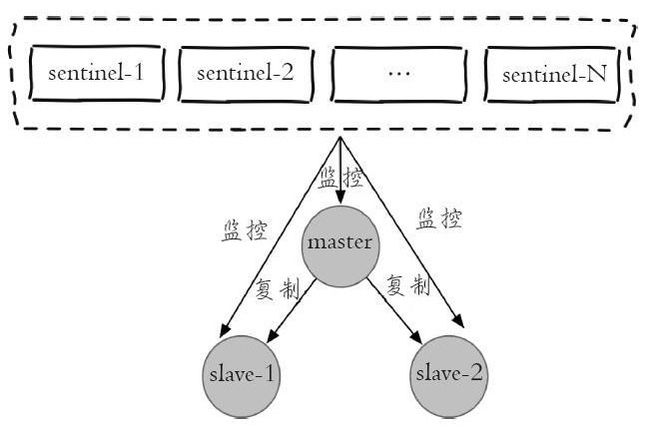
从图中可以看到哨兵节点之间会相互发送消息,以检测其余的哨兵节点是否整成工作,并且哨兵节点也会向主从节点发送消息,以检测监控的主从节点是否正常工作;哨兵架构的作用:解决主从模式下主节点故障转移工作;这里如果主节点因为故障下线,那么某个sentinel节点发送检测消息给主节点时,如果在指定时间内收不到回复,那么该sentinel就会主观的判断该主节点已经下线,那么其会发送消息给其余的sentinel节点,询问其是否“认为”该主节点已下线,其余的sentinel收到消息后也会发送检测消息给主节点,如果其认为该主节点已经下线,那么其会回复向其询问的sentinel节点,告知其也认为主节点已经下线,当该sentinel节点最先收到超过指定数目(配置文件中配置的数目和当前sentinel节点集合数的一半,这里两个数目的较大值)的sentinel节点回复说当前主节点已下线,那么其就会对主节点进行故障转移工作,故障转移的基本思路是在从节点中选取某个从节点向其发送slaveof no one(假设选取的从节点为127.0.0.1:6380),使其称为独立的节点(也就是新的主节点),然后sentinel向其余的从节点发送slaveof 127.0.0.1 6380命令使它们重新成为新的主节点的从节点。重新分配之后sentinel节点集合还会继续监控已经下线的主节点(假设为127.0.0.1:6379),如果其重新上线,那么sentinel会向其发送slaveof命令,使其成为新的主机点的从节点,如此故障转移工作完成。
REDIS集群模式:
主要是解决REDIS在分布式方面的需求。当遇到单击内存、并发和流量瓶颈等问题时,可采用Cluster方案达到负载均衡的目的;且REDIS中哨兵有效的解决了故障转移的问题,也解决了主节点下线客户端无法识别新的可用节点问题,但是如果从节点下线了,哨兵不会对其进行故障转移,并且连接从节点的客户端也无法获取新的可用节点;REDIS的集群模式正好解决了该问题;
REDIS中数据和槽slot挂钩,所有的数据根据一致哈希算法会被映射到槽中,同时这些槽按照设置被分配到不同的REDIS节点上,也就是说存储只与槽有关,并且槽的数量是一定的,REDIS集群通过这种方式达到其高效和高可用性目的;
6、nginx和aray
Nginx的作用实现反向代理、负载均衡、动静分离等;
反向代理:我们并不知道哪台服务器提供的内容,负载均衡当用户访问网站时先访问一个中间服务器,再让这个中间服务器再服务器集群中选择一个压力较小的服务器,然后将访问请求引入选择的服务器。
7、json解析
JSON是一种通用的数据类型,任何语言都认识,接口返回的数据类型都是JSON,长的像字典;
文件里只能写字符串,但可以把字典转成JSON串,JSON串是字符串,可以存到文件中;
dumps()方法:
stus={'xiaojun':'123456','xiaohei':'7891','abc':'11111'}
#先把字典转成json
res2=json.dumps(stus)
print(res2)#打印字符串
print(type(res2))#打印res2类型
with open('stus.txt','w',encoding='utf-8' as f:#打开文件
f.write(res2)#在文件里写入转成的json串
#使用dumps()方法前要先打开文件再写入
stus={'xiaojun':'123456','xiaohei':'7890','lrx':'111111'}
res2=json.dumps(stus,indent=8,ensure_ascii=False)
print(res2)
with open('stus.json','w',encoding='utf-8') as f:#使用.dumps()方法时,要写入
f.write(res2)dump()方法
stus={'xiaojun':'123456','xiaohei':'7890','lrx':'111111'}
f=open('stus2.json','w',encoding='utf-8')
json.dump(stus,f,indent=4,ensure_ascii=False).dump()不需要使用.write()方法,只需要写哪个字典、哪个文件即可;而.dumps()需要使用.write()方法写入
如果要把字典写到文件里面的时候,dump()好用;但如果不需要操作文件,或需要把内容存到数据库和Excel,则需要使用dumps()先把字典转成字符串,再写入;
dump/dumps中使用参数indent为字符串换行+缩进;
dumps/dump中使用参数ensure_ascii为内容输出为中文:
res2=json.dumps(stus,indent=4,ensure_ascii=False)#为False时内容输出显示正常的中文,而不是转码
print(res2)loads()方法
import json#引用json模块
res=json.loads(s)
print(res)#打印字典
print(type(res))#打印res类型
print(res.keys())#打印字典的所有Key
f=open('stus.json',encoding='utf-8')
content=f.read()#使用loads()方法,需要先读文件
user_dic=json.loads(content)
print(user_dic)
load()方法
import json
f=open('stus.json',encoding='utf-8')
user_dic=json.load(f)
print(user_dic)
区别:
loads()传的是字符串,而load()传的是文件对象
使用loads()时需要先读文件再使用,而load()则不用8、自动化核心代码
# 比较两个字典部分是否相等
def compare_two_dict(dict1, dict2, key_list=None):
flag = True
keys1 = dict1.keys()
keys2 = dict2.keys()
if key_list == None:
for key in keys2:
if key in keys1:
if dict1[key] == dict2[key]:
flag = flag & True
else:
flag = flag & False
else:
flag = flag & False
elif len(key_list) != 0:
for key in key_list:
if key in keys1 and key in keys2:
if dict1[key] == dict2[key]:
flag = flag & True
else:
flag = flag & False
else:
raise Exception('key_list contains error key')
else:
raise Exception('key_list is null')
if flag:
result = 'PASS'
else:
result = 'FAILED'
return resultdef dictRebuildWithreplaceDict(sourceDict,replaceDict):
"""
#替换掉字典中指定的key的value值
:param sourceDict: 原字典
:param replaceDict:需要替换的字典数据
:return:rebuild后的字典数据
"""
if isinstance(sourceDict, dict) and isinstance(replaceDict, dict):
sourceDictKeys = sourceDict.keys()
replaceDictKeys = replaceDict.keys()
for sourceDictKey in list(sourceDictKeys):
if isinstance(sourceDict[sourceDictKey], dict):
dictRebuildWithreplaceDict(sourceDict[sourceDictKey],replaceDict)
if isinstance(sourceDict[sourceDictKey], list):
for listKey in range(len(sourceDict[sourceDictKey])):
if isinstance(sourceDict[sourceDictKey][listKey], dict):
dictRebuildWithreplaceDict(sourceDict[sourceDictKey][listKey], replaceDict)
if sourceDictKey in replaceDictKeys:
sourceDict[sourceDictKey] = replaceDict[sourceDictKey]
else:
raise Exception('sourceDict or replaceDict is not a dict ')
return sourceDictdef dictRebuildWithIgnoreKeys(sourceDict,keyList):
""""
#忽略掉字典中指定的keys
:param sourceDict 原始dict
:param keyList 忽略的keys的list集合
:return 返回重构后的dict
"""
if isinstance(sourceDict,list):
for element in sourceDict:
dictRebuildWithIgnoreKeys(element, keyList)
elif isinstance(sourceDict,dict) and isinstance(keyList,list):
sourceDictKeys = sourceDict.keys()
for sourceDictKey in list(sourceDictKeys):
if isinstance(sourceDict[sourceDictKey], dict):
dictRebuildWithIgnoreKeys(sourceDict[sourceDictKey],keyList)
if isinstance(sourceDict[sourceDictKey],list):
for listKey in range(len(sourceDict[sourceDictKey])):
if isinstance(sourceDict[sourceDictKey][listKey],dict):
dictRebuildWithIgnoreKeys(sourceDict[sourceDictKey][listKey], keyList)
if sourceDictKey == "content" and isinstance(sourceDict[sourceDictKey],str):
#print("content is :"+sourceDict[sourceDictKey])
sourceDict['content'] = dictRebuildWithIgnoreKeys(json.loads(sourceDict[sourceDictKey]), keyList)
if sourceDictKey == "main_info" and isinstance(sourceDict[sourceDictKey],str):
#print("main_info is :"+sourceDict[sourceDictKey])
sourceDict['main_info'] = dictRebuildWithIgnoreKeys(json.loads(sourceDict[sourceDictKey]), keyList)
if sourceDictKey == "payload" and isinstance(sourceDict[sourceDictKey],str):
#print("payload is :" + sourceDict[sourceDictKey])
sourceDict['payload'] = dictRebuildWithIgnoreKeys(json.loads(sourceDict[sourceDictKey]), keyList)
if sourceDictKey in keyList:
sourceDict.pop(sourceDictKey)
else:
raise Exception('params is not a dict or keyList is not a list')
return sourceDictdef getJsonFromFile(filename):
"""
# 从json文件中获取请求参数
:param filename: 配置文件,格式为json
:return: 返回json串
"""
try:
if isfile(filename):
return json.load(open(filename,'r', encoding='UTF-8'))
else:
return None
except Exception as e:
logging.warning("%s -- The json file is Wrong! Pleas check file: %s" % (e, filename))
return Noneimport json
import datetime
class DateEncoder(json.JSONEncoder):
def default(self,obj):
if isinstance(obj,datetime.datetime):
return obj.strftime('%Y-%m-%d %H:%M:%S')
elif isinstance(obj,datetime.date):
return obj.strftime("%Y-%m-%d")
else:
return json.JSONEncoder.default(self,obj)from Common.CommonUtils import compare_two_dict
import json
from Common.DateEncoder import *
class HttpResponseCheck(object):
def HttpResponseCheck(self,actually_httpResponse_result,expected_httpResponse__result,keyCheckList=None):
if actually_httpResponse_result != None and expected_httpResponse__result != None:
result = compare_two_dict(actually_httpResponse_result,expected_httpResponse__result,keyCheckList)
if result == "PASS":
assert True, "HTTP_RESPONSE_CHECK is : PASS"
else:
assert False, "HTTP_RESPONSE_CHECK is : FAILED ,actually_httpResponse_result is :\n%s" %json.dumps(actually_httpResponse_result, cls=DateEncoder,ensure_ascii=False)
elif actually_httpResponse_result != None and expected_httpResponse__result == None:
assert False, "The expected_httpResponse_result is null!"
elif actually_httpResponse_result == None and expected_httpResponse__result != None:
assert False, "The actually_httpResponse_result is null!"
HTTP_RESPONSE_CHECK = HttpResponseCheck()#!/usr/bin/env python
# encoding: utf-8
import sys
import json
import requests
from time import sleep
from Common.env_mc import baseRequestURL
from Common.CommonUtils import sDict2dDict
from Common.Logging import *
import importlib
importlib.reload(sys)
import operator
class HttpClient(object):
def __init__(self, reqHeaderParams, params, sufRequestURL, reqMethod):
self.sufRequestURL = sufRequestURL # 接口请求URL后缀
self.reqHeaderParams = reqHeaderParams
self.params = params
self.reqMethod = reqMethod
self.headers = {'content-type': 'application/json;charset=UTF-8'}
if self.reqHeaderParams != None:
self.headers.update(self.reqHeaderParams)
def requestSend(self, auth="", sleeptime=0):
"""
# 发送请求
:param sleeptime: 请求等待时间(请求结果已返回,但数据库结果需要经过sleeptime后才生成)
:param auth: 鉴权方式,取值分别为:token,session,service
:return: 返回请求对象
"""
if auth == "":
httpRequestURL = "%s%s" % (baseRequestURL, self.sufRequestURL)
else:
httpRequestURL = "%s/%s%s" % (baseRequestURL, auth, self.sufRequestURL)
if self.reqMethod in ["post", "POST"]:
self.result = requests.post(httpRequestURL, data=json.dumps(self.params,ensure_ascii=False).encode(), headers=self.headers)
logging.debug("Post - Request URL: %s" % self.result.url)
logging.debug("Request params: %s" % self.params)
elif self.reqMethod in ["get", "GET"]:
self.result = requests.get(httpRequestURL, params=self.params, headers=self.headers)
logging.debug("Get - Request URL: %s" % self.result.url)
elif self.reqMethod in ["put", "PUT"]:
self.result = requests.put(httpRequestURL, data=json.dumps(self.params,ensure_ascii=False).encode(), headers=self.headers)
logging.debug("PUT - Request URL: %s" % self.result.url)
sleep(sleeptime)
return self.result
def compareResponse(self, exp_response, ignoreList):
"""
# 将实际结果与预期结果进行比较,忽略ignoreList中的key
:param exp_result: 预期结果(json格式)
:param ignoreList: 忽略的key列表
:return:
"""
assert self.result.status_code == 200, u"服务端异常!status_code:%s" % self.result.status_code
real_response = self.result.json()
old_result = self.result.text
if ignoreList == None: ignoreList = []
sDict2dDict(real_response, ignoreList)
sDict2dDict(exp_response, ignoreList)
assert operator.eq(real_response, exp_response) == 0, "The http request real result:\n%s" % old_result.encode("utf8")import sys
import re
import pymysql
from os.path import isfile
from pymysql import cursors
from Common.CommonUtils import getKeyValue
from Common.CommonUtils import FormatList
from Common.CommonUtils import sDict2dDict
from Common.Logging import *
import json
import operator
import importlib
importlib.reload(sys)
class JDBCUtils(object):
def __init__(self, host, user, passwd, db, port):
self.conn = pymysql.connect(host=host, user=user, passwd=passwd,
db=db, port=port, cursorclass = cursors.DictCursor, charset="utf8")
self.user = user
self.db = db
def executesql(self, sqlstr):
#if self.user == "gspmc" and self.db == "gspmc":
try:
cur = self.conn.cursor()
cur.execute(sqlstr)
cur.close()
self.conn.commit()
except Exception as e:
self.conn.rollback()
assert False, "Error: %s!" % e
def query(self, sqlstr):
if "select" in sqlstr.lower():
try:
cur = self.conn.cursor()
cur.execute(sqlstr)
result = cur.fetchall()
cur.close()
return result
except Exception as e:
assert False, "Error: %s!" % e
self.conn.close()
#调用小蜜丰存储过程执行初始化标签数据
def callProcedure(self,procedure):
try:
cur = self.conn.cursor()
cur.callproc(procedure)
result = cur.fetchall()
logging.info("procedure result is: %s" % json.dumps(result))
cur.close()
self.conn.close()
except Exception as e:
assert False, "Error: %s!" % e
def getExcutSqls(self, sqlfile, jsonfile):
"""
# 获取可执行的sql列表
:param sqlfile:
:param jsonfile:
:return:
"""
sqlList = []
keyvalue = getKeyValue(sqlfile, jsonfile)
fp = open(sqlfile, 'r')
for line in fp.readlines():
sql = line.strip() # 去除行尾行首空格和换行
if sql == "" or sql[:2] == "--": continue # 忽略空行和注释行(以--开头表示注释)
sqlkeyList = re.findall("{(\w+)}", sql)
for key in sqlkeyList:
oldstr = r"{%s}" % key
#3.6直接是获取,不需要encode("utf-8")
#if type(keyvalue[key]) == unicode:
# newstr = keyvalue[key].encode("utf-8")
#else:
newstr = str(keyvalue[key])
sql = sql.replace(oldstr, newstr)
sqlList.append(sql)
fp.close()
return sqlList
def initOrflush_sql(self, sqlfile, jsonfile):
"""
# 数据库数据setup和teardown
:param sqlfile:
:param jsonfile:
:return:
"""
sqllist = self.getExcutSqls(sqlfile, jsonfile)
for sql in sqllist:
logging.info("InitOrFlush Sql: %s" % sql)
self.executesql(sql)
def getDbResult(self, sqlfile, jsonfile):
"""
# 从jsonfile中获取sql中需要替换的内容,并返回sqlfile中sql查询结果
:param sqlfile: sql语句存放文件
:param jsonfile: 请求参数存放文件(json格式)
:return: 格式化对象,包含text和json属性
"""
if isfile(sqlfile) and isfile(jsonfile):
sqllist = self.getExcutSqls(sqlfile, jsonfile)
resultList = []
for sql in sqllist:
logging.info("Query Sql: %s" % sql)
if sql != "":
result = list(self.query(sql))
resultList.append(result)
return FormatList(resultList)
else:
return None
def compareResult(self, exp_result, real_result, ignoreList):
"""
# 验证数据库结果
:param exp_result: 预期结果
:param real_result: 实际结果(格式化对象)
:param ignoreList: 需要忽略检查的key列表
:return:
"""
if exp_result != None and real_result != None:
old_result = real_result.text
real_result = real_result.json
if ignoreList == None: ignoreList = []
sDict2dDict(real_result, ignoreList)
sDict2dDict(exp_result, ignoreList)
assert operator.eq(exp_result, real_result) == 0, "The db request real resutl:\n%s" % old_result
elif exp_result == None and real_result != None:
assert False, "The exp_result is null! Please check file 'dbResult.json'"
elif exp_result != None and real_result == None:
assert False, "The real_result is null! Please check file 'queryResult.sql'"
from kafka import KafkaConsumer
from kafka.errors import KafkaError
import json
import logging
class Kafka_consumer():
'''
使用Kafka—python的消费模块
'''
def __init__(self, kafkahost, kafkaport, kafkatopic, groupid):
self.kafkaHost = kafkahost
self.kafkaPort = kafkaport
self.kafkatopic = kafkatopic
self.groupid = groupid
self.consumer = KafkaConsumer(self.kafkatopic, group_id=self.groupid,
bootstrap_servers='{kafka_host}:{kafka_port}'.format(
kafka_host=self.kafkaHost,
kafka_port=self.kafkaPort))
def consume_data(self):
try:
for message in self.consumer:
# print json.loads(message.value)
yield message
except KafkaError as e:
logging.info('KafkaError is : %s' % e)
from kafka import KafkaProducer
from kafka.errors import KafkaError
import json
import logging
from Common.Kafka_consumer import Kafka_consumer
class Kafka_producer():
'''
使用kafka的生产模块
'''
def __init__(self, kafkahost, kafkaport, kafkatopic):
self.kafkaHost = kafkahost
self.kafkaPort = kafkaport
self.kafkatopic = kafkatopic
self.producer = KafkaProducer(bootstrap_servers='{kafka_host}:{kafka_port}'.format(
kafka_host=self.kafkaHost,
kafka_port=self.kafkaPort
))
def sendjsondata(self, params):
try:
parmas_message = json.dumps(params)
producer = self.producer
producer.send(self.kafkatopic, parmas_message.encode('utf-8'))
producer.flush()
except KafkaError as e:
logging.info('KafkaError is : %s' % e)
from Common.Kafka_producer import Kafka_producer
KAFAKA_HOST = "10.202.*.*" # 服务器端口地址
KAFAKA_PORT = * # 端口号 1080
KAFAKA_TOPIC = "1111111111111111111"
class SGS_EXP_DELIVERY_INFO_TO_GSP(object):
def kafka_producer(self):
return Kafka_producer(KAFAKA_HOST,KAFAKA_PORT,KAFAKA_TOPIC)
KAFKA_SGS_EXP_DELIVERY_INFO_TO_GSP = SGS_EXP_DELIVERY_INFO_TO_GSP()import logging
import sys
from paramiko import AuthenticationException
from paramiko.client import SSHClient, AutoAddPolicy
from paramiko.ssh_exception import NoValidConnectionsError
class SSHClientUtils():
def __init__(self):
self.ssh_client = SSHClient()
# 此函数用于输入用户名密码登录主机
def ssh_login(self,host_ip,username,password):
try:
# 设置允许连接known_hosts文件中的主机(默认连接不在known_hosts文件中的主机会拒绝连接抛出SSHException)
self.ssh_client.set_missing_host_key_policy(AutoAddPolicy())
self.ssh_client.connect(host_ip,port=22,username=username,password=password,timeout=30)
except AuthenticationException:
logging.warning('username or password error')
return 1001
except NoValidConnectionsError:
logging.warning('connect time out')
return 1002
except:
logging.warning('unknow error')
print("Unexpected error:", sys.exc_info()[0])
return 1003
return 1000
# 此函数用于执行command参数中的命令并打印命令执行结果
def execute_command(self,command):
stdin, stdout, stderr = self.ssh_client.exec_command(command)
result = stdout.read().decode('utf-8')
return result
# 此函数用于退出登录
def ssh_logout(self):
logging.warning('will exit host')
self.ssh_client.close()
SSHClientz = SSHClientUtils()
class TM_SSH_SERVICE():
def run_command(self,cmd):
for i in range(len(list(host_ip))):
# 登录,如果返回结果为1000,那么执行命令,然后退出
if SSHClientz.ssh_login(host_ip[i],username,password) == 1000:
logging.warning(f"{host_ip[i]}-login success, will execute command:{cmd}")
result = SSHClientz.execute_command(cmd)
#logging.warning(f"result is : {result}")
logging.info('result is : \n%s' %result)
SSHClientz.ssh_logout()
TM_SSH_SERVICEZ = TM_SSH_SERVICE()9、activemq、rabbitmq及kafka原理比较
activemq:
支持主从复制、集群。但是集群功能看起来很弱,只有failover功能,即我连一个失败了,可以切换到其他的broker上,这点貌似不科学,假设有三个broker,其中一个上面没有consumer,但另外两个挂了,消息会转到这个上面来,堆积起来;activemq工作模型比较简单,只有两种模式queue、topics;
queue就多对一,producer往queue里发送消息,消费者从queue里取,消费一条,就从queue里移除一条。如果一个消费者消费速度不够快怎么办呢?在activemq里,提供messageGroup的概念,一个queue可以有多个消费者,但是他们得标记自己是一个messageGroup里的。这样,消息会轮训发送给每个消费者,也就是说消费者不会重复消费同一条消息。但是每条消息只被消费一次。
topics就是广播。producer往broker发消息,每个消息包含topic。消费者订阅感兴趣的topic,所有订阅了topic的消费者都会收到消息。当然订阅分持久不持久。持久订阅,当消费者断开一会,再连上来,仍然会把没收到的消费发过来。不持久的订阅,断开这段时间的消息就收不到了。activemq支持mqtt、ssl。
rabbitmq:
rabbitmq用erlang写的。安装完才10m不到,在windows上使用也非常方便,在这点上完爆了activemq,java又臭又长没办法啊。rabbitmq给我感觉更像oracle,功能非常强大。安装完,也有实例的概念,可以像建数据库一样,建实例,建用户划权限。同时监控系统也很好用。这些都是好处,同时也是累赘,整体上来说rabbitmq比activemq复杂太多了。
从机制上来讲,rabbitmq也有queue和topic的概念,发消息的时候还要指定消息的key,这个key之后会做路由键用。但是,多了一个概念叫做交换器exchange。exchange有四种,direct、fanout、topic、header。也就是说,发消息给rabbitmq时,消息要有一个key,并告诉他发给哪个exchange。exchange收到之后,根据key分发或者广播给queue。消费者是从queue里拿消息的,并接触不到交换机。
在rabbitmq里,有各种默认行为,如果我们不指定exchange,会有个默认的direct类型的exchange,如果不指定队列和交换器的绑定关系,默认就按消息的key绑定对应的queue。此时发一个消息,消息的key是什么,就会被默认交换器送给对应的queue。

此时,其实等同于activemq的queue模式。
在rabbitmq里,一个queue可以有多个消费者

通过设置prefetch的值为1,可以让多个消费者每次都取到一条记录,消费完再取下一条。这两种都是使用direct交换器,即消息的key是多少,就把消息放到key对应的queue中。
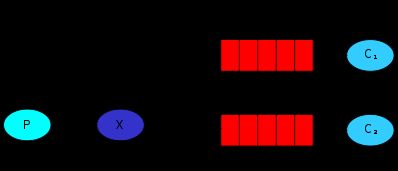
fanout交换器。实际上就是广播,发送到fanout交换器的消息,会被转发给所有和这个交换器绑定的队列。通常我们把队列搞成临时的,这样就解耦了。例如用户登录,发送一个登陆消息到fanout交换器,同时有一个smsQueue和交换器绑定,一个消费者从这个smsQueue里取出谁登陆了,并发送一条短信。过了几天,我们希望用户登陆可以获得积分。那么我再声明一个scoreQueue绑定到这个fanout交换器,实现积分更改逻辑。下图是fanout(X为交换器)

总体说来fanout其实就是direct交换器实现的。把两个队列都绑定到direct,绑定的时候指定同一个key,就变成fanout交换器了,如下图
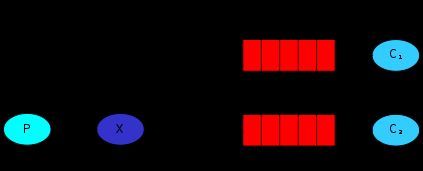
queue和exchange绑定的时候,也可以指定多个绑定key,这时候就实现了简单版的订阅。如下图
当然这样不够灵活,我想要靠通配符绑定如何呢,这时候就不用direct交换器了,用topic交换器
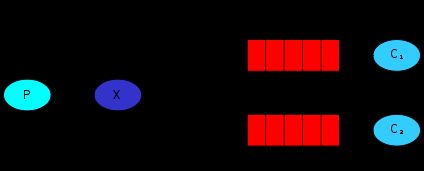
“#”通配剩余字符,"*"通配部分字符。 如果绑定的时候key为“#”,那么其实就是fanout交换器。如果一个通配符都没有,其实就是direct交换器。
head交换器貌似是通过消息附带的头信息来路由的,不过官方对这个介绍的少之又少,平时也应该没什么人用,死信队列貌似依赖于这个。
通过交换器的概念,rabbitmq在机制上要比activemq灵活不少。对于activemq来说,你要么是个queue的消费者,要么是个topic的订阅者。你要同时订阅多个topic,要自己在消费者端写代码来实现。在rabbitmq中,你只是queue的消费者,至于你这个queue的消息是从哪个topic来,或者从哪里直接发过来,这个和消费者没有关系,而且queue里的消息从哪来可以在rabbitmq里动态配置。所以灵活度得到了提升。
rabbitmq同样也支持主从复制和集群。但是rabbitmq的集群非常多样化,而且需要至少一台机器做为磁盘节点,可以持久化queue和exchange的信息,其他的可以为内存节点。普通集群中,只有exchange,queue这些定义是分布在所有机器上的,而queue中的数据不是冗余的,比如有三台rabbitmq组成了集群,他们共享同样的exchange,queue,但是一条消息数据落到了第一台机器上,另外两台实际上没有这条数据的。 对于整个集群的使用,这样其实没有任何问题。 但出于高可用的角度来想,还是需要完完全全的分布式集群的,万一中间有数据这台机器挂了? rabbitmq对此也有支持,把队列数据也冗余存到三台机器上,称之为镜像队列,但性能要比普通集群低,毕竟一条消息被复制到其他机器上是耗时的事情。
rabbitmq以plugin的形式支持mqtt,和spring整合也非常简单;
kafka:
kafka号称为分布式而生。和activemq以及rabbitmq这些企业级队列而言确实更有分布式系统的优势。
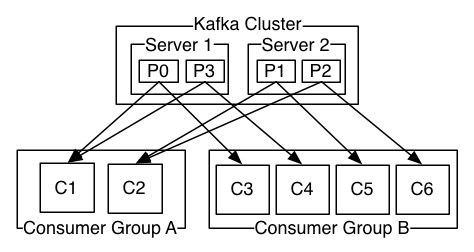
kafka中,只有topic,但是每个topic可以有很多partition分区。上图中kafka集群由两台机器组成。topic被分成四个分区,server1维护p0,p3。 在kafka中,每个消费者都要指出自己属于哪个consumerGroup,每个consumer可以读取多个partition。但是一个partition在同一个consumerGroup中,只会被一个consumer消费。以此保证不会重复消费。而且在一个partition中,消息被消费的顺序是可保障的。上图中,consumer group A 由两个consumer组成,因此一个consumer可以消费两个partition。如果要保证严格的顺序性,那么就要像consumer group B一样,每个consumer只消费一个partition。kafka和rabbitmq及activemq机制上略有区别。rabbitmq和activemq都是消费后就删除消息,没有重复消费的功能,而kafka 队列中的内容按策略存储一定时间,消费者通过指定偏移量来读取数据。如果使用基础api可以从任意位置读取。kafka同时提供高级api,即kafka来维护每个消费者当前读到什么位置了,下次再来,可以接着读。
kafka中partition是冗余存储的。如果一个partition不幸挂了,通过选主,马上可以切换到另外一台机器上继续使用。这一点上,是当之无愧的分布式队列。相比之下,rabbitmq需要配置镜像队列,操作太麻烦。kafka搭建集群也是非常简单。
kafka的优势在于: 传统的消息队列只有两种模式,要么是queue,要么是publish-subscribe发布订阅。在queue模式中,一组消费者消费一个队列,每条消息被发给其中一个消费者。在publish-subscribe模式中,消费被广播给所有消费者。queue模式的好处在于,他可以把消费分发给一组消费者,从而实现消费者的规模化(scale);问题在于,这样一个消息只能被一组消费者消费,一旦消费,消息就没有了。publish-subscribe的好处在于,一个消息可以被多组消费者消费;问题在于,你的消费者没法规模化,即不可能出现多个消费者订阅同一个topic,但每个消费者只处理一部分消息(虽然这个可以通过设计topic来解决)。
kafka的设计意义在于,大家都publish-subscribe,因为我的队列数据是不删除的,多个subscriber可以订阅同一个topic,但是各自想从哪读,从哪读,互不干扰。同时提出了consumer group的概念。每个subscriber可以是多个consumer组成的,在consumer group内部,你们自己分配,不要两个人消费同一条数据。为了达到这种目的,一个topic里的消息,被分成多个partition,既实现了上面的想法,同时又冗余(一个partition可以冗余存储在多台机器上),达到分布式系统的高可用效果。
kafka也支持mqtt,需要写一个connecter。kafka还提供流式计算的功能,做数据的初步清理还是很方便的。
总体而言。我感觉kafka安装使用最简单,同时,如果有集群要求,那么kafka是当仁不让的首选。尤其在海量数据,以及数据有倾斜问题的场景里,因为partition的缘故,数据倾斜问题自动解决。比如个别Topic的消息量非常大,在kafka里,调整partition数就好了。反而在rabbitmq或者activemq里,这个不好解决。
rabbitmq是功能最丰富,最完善的企业级队列。基本没有做不了的,就算是做类似kafka的高可用集群,也是没问题的,不过安装部署麻烦了点。
activemq相对来说,显的老套了一些。不过毕竟是java写的,在内嵌到项目中的情况下,或者是简单场景下,还是不错的选择。
补充一下。在kafka中,创建一个topic是一个比较重的操作,因为是分布式的,topic要同步到其他的broker,中间还要经过zookeeper。所以kafka仅仅做mqtt的输入是ok的,但是你需要给每个硬件推送消息,实际上不太好。这方面反倒是rabbitmq比较好,因为在rabbitmq中创建几万的topic是很容易的,所以是可以做到每个硬件订阅不同的topic。
10、kafka原理pull和push
Broker
Kafka集群包含一个或多个服务器,这种服务器被称为broker
Topic
每条发布到Kafka集群的消息都有一个类别,这个类别被称为topic。(物理上不同topic的消息分开存储,逻辑上一个topic的消息虽然保存于一个或多个broker上但用户只需指定消息的topic即可生产或消费数据而不必关心数据存于何处)
Partition
parition是物理上的概念,每个topic包含一个或多个partition,创建topic时可指定parition数量。每个partition对应于一个文件夹,该文件夹下存储该partition的数据和索引文件
Producer
负责发布消息到Kafka broker
Consumer
消费消息。每个consumer属于一个特定的consuer group(可为每个consumer指定group name,若不指定group name则属于默认的group)。使用consumer high level API时,同一topic的一条消息只能被同一个consumer group内的一个consumer消费,但多个consumer group可同时消费这一消息。
Kafka架构
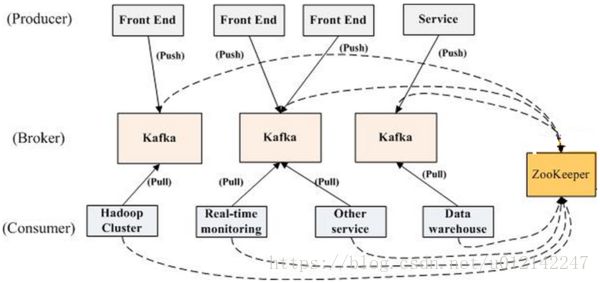
如上图所示,一个典型的kafka集群中包含若干producer(可以是web前端产生的page view,或者是服务器日志,系统CPU、memory等),若干broker(Kafka支持水平扩展,一般broker数量越多,集群吞吐率越高),若干consumer group,以及一个Zookeeper集群。Kafka通过Zookeeper管理集群配置,选举leader,以及在consumer group发生变化时进行rebalance。producer使用push模式将消息发布到broker,consumer使用pull模式从broker订阅并消费消息。
Push vs. Pull
作为一个messaging system,Kafka遵循了传统的方式,选择由producer向broker push消息并由consumer从broker pull消息。一些logging-centric system,比如Facebook的Scribe和Cloudera的Flume,采用非常不同的push模式。事实上,push模式和pull模式各有优劣。
push模式很难适应消费速率不同的消费者,因为消息发送速率是由broker决定的。push模式的目标是尽可能以最快速度传递消息,但是这样很容易造成consumer来不及处理消息,典型的表现就是拒绝服务以及网络拥塞。而pull模式则可以根据consumer的消费能力以适当的速率消费消息。
Topic & Partition
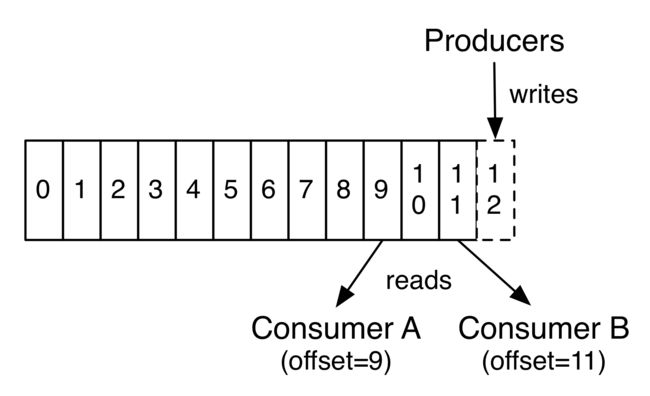
Topic在逻辑上可以被认为是一个在的queue,每条消费都必须指定它的topic,可以简单理解为必须指明把这条消息放进哪个queue里。为了使得Kafka的吞吐率可以水平扩展,物理上把topic分成一个或多个partition,每个partition在物理上对应一个文件夹,该文件夹下存储这个partition的所有消息和索引文件。

每个日志文件都是“log entries”序列,每一个log entry包含一个4字节整型数(值为N),其后跟N个字节的消息体。每条消息都有一个当前partition下唯一的64字节的offset,它指明了这条消息的起始位置。磁盘上存储的消费格式如下:
message length : 4 bytes (value: 1+4+n)
“magic” value : 1 byte
crc : 4 bytes
payload : n bytes
这个“log entries”并非由一个文件构成,而是分成多个segment,每个segment名为该segment第一条消息的offset和“.kafka”组成。另外会有一个索引文件,它标明了每个segment下包含的log entry的offset范围,如下图所示。 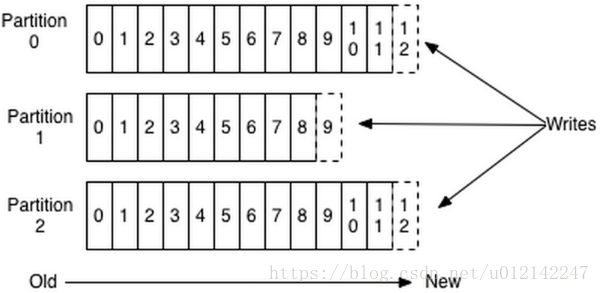
因为每条消息都被append到该partition中,是顺序写磁盘,因此效率非常高(经验证,顺序写磁盘效率比随机写内存还要高,这是Kafka高吞吐率的一个很重要的保证)。
每一条消息被发送到broker时,会根据paritition规则选择被存储到哪一个partition。如果partition规则设置的合理,所有消息可以均匀分布到不同的partition里,这样就实现了水平扩展。(如果一个topic对应一个文件,那这个文件所在的机器I/O将会成为这个topic的性能瓶颈,而partition解决了这个问题)。在创建topic时可以在$KAFKA_HOME/config/server.properties中指定这个partition的数量(如下所示),当然也可以在topic创建之后去修改parition数量。
The default number of log partitions per topic. More partitions allow greater # parallelism for consumption, but this will also result in more files across # the brokers. num.partitions=3
在发送一条消息时,可以指定这条消息的key,producer根据这个key和partition机制来判断将这条消息发送到哪个parition。paritition机制可以通过指定producer的paritition. class这一参数来指定,该class必须实现kafka.producer.Partitioner接口。本例中如果key可以被解析为整数则将对应的整数与partition总数取余,该消息会被发送到该数对应的partition。(每个parition都会有个序号)
import kafka.producer.Partitioner;
import kafka.utils.VerifiableProperties;
public class JasonPartitioner implements Partitioner {
public JasonPartitioner(VerifiableProperties verifiableProperties) {}
@Override
public int partition(Object key, int numPartitions) {
try {
int partitionNum = Integer.parseInt((String) key);
return Math.abs(Integer.parseInt((String) key) % numPartitions);
} catch (Exception e) {
return Math.abs(key.hashCode() % numPartitions);
}
}
} 如果将上例中的class作为partition.class,并通过如下代码发送20条消息(key分别为0,1,2,3)至topic2(包含4个partition)。
public void sendMessage() throws InterruptedException{
for(int i = 1; i <= 5; i++){
List messageList = new ArrayList>();
for(int j = 0; j < 4; j++){
messageList.add(new KeyedMessage("topic2", j+"", "The " + i + " message for key " + j));
}
producer.send(messageList);
}
producer.close();
} 11、读取配置文件实现
python中使用configparser模块支持读取.conf和.ini等类型的文件;
# coding=utf-8
import configparser
import os
os.chdir("E:\\Automation\\UI\\testcase")
cf = configparser.ConfigParser()
# read(filename) 读文件内容
filename = cf.read("test.ini")
print(filename)
# sections() 得到所有的section,以列表形式返回
sec = cf.sections()
print(sec)
# options(section) 得到section下的所有option
opt = cf.options("mysql")
print(opt)
# items 得到section的所有键值对
value = cf.items("driver")
print(value)
# get(section,option) 得到section中的option值,返回string/int类型的结果
mysql_host = cf.get("mysql","host")
mysql_password = cf.getint("mysql","password")
print(mysql_host,mysql_password)cf.read(filename):读取文件内容
cf.sections():得到所有的section,并且以列表形式返回
cf.options(section):得到section下所有的option
cf.items(option):得到该section所有的键值对
cf.get(section,option):得到section中option的值,返回string类型的结果
cf.getint(section,option):得到section中option的值,返回int类型的结果
12、dubbo接口测试实现
# coding:utf-8
import json
import dubbo_telnet
# Doubble服务器IP
Host = '10.202.*.*'
# Doubble服务端口
Port = 20941
# 初始化dubbo对象
conn = dubbo_telnet.connect(Host, Port)
# 设置telnet连接超时时间
conn.set_connect_timeout(10)
# 设置dubbo服务返回响应的编码
conn.set_encoding('gbk')
# 显示服务列表
print conn.do("ls")
# 显示指定服务的方法列表
print conn.do("ls com.sf.sgs.rss.service.rpc.ICommonPlanService")
# 方法1 调用
interface = 'com.sf.sgs.rss.service.rpc.ICommonPlanService'
method = 'getPlanDetailByUnitAreaCode'
result = conn.invoke(interface, method, '"J755AU001","20180814"')
# json格式化 sort_keys=True, 缩进行数 indent=4
print json.dumps(result, sort_keys=True, indent=4)
# 方法2 调用
# command = 'invoke com.sf.sgs.rss.service.rpc.ICommonPlanService.getPlanDetailByUnitAreaCode("J755AU001", "20180814")'
# result2 = conn.do(command)
# print json.dumps(result2, sort_keys=True, indent=4)RPC接口为远程调用协议,程序可使用这种协议向网络中的另一台计算机上的程序请求服务,由于RPC的程序不必了解支持通信的网络协议的情况,因此RPC提高了程序的互操作性。其原理就是从一台机器上通过参数 传递的方式调用另一台机器上的一个函数或方法并得到返回的结果;其会隐藏通信细节不需要直接处理Socket通讯和HTTP通讯;其在使用形式上就像调用本地函数和方法一样去调用远程的函数和方法。
13、Robot Framework
变量标示符:单值变量${var}、list变量@{var},二者均可以用set Variable来赋值;常量用%{var3}设置。
${var2} Set Variable abcd
${var2} Set Variable If abcd def
@{var} Set Variable 1 2 3
@{var} Create List 1 2 3
Get返回值:Get Length/Get Time
打印:log针对单值变量、log many针对list变量;
变量作用范围:Set Global Variable为设置全局变量。当执行过这个设置后,这个变量在所有的测试案例和测试套件中都有效;Set Suite Variable为设定File Suite级变量,当执行过这个变量后,这个变量在当前的File Suite中有效;Set Test Variable为设定Case级变量;
for循环::FOR 循环变量 IN RANGE end;
针对web自动化:引入Selenium2Libarary,需要装浏览器驱动,常用关键字:open browser、close browser、go to跳转到某个URL、go back相当于浏览器的后退、Select window选择浏览器窗口、Close window关闭浏览器窗口、Wait until keyword Succeed、close all browser关闭所有浏览器、select window by handle通过handle选择、get window handle、get current window handle、select frame、unselect frame等;add cookie、delete cookie、delete all cookie、get cookies、get cookie value、click element、click link、click image、select checkbox、unselect checkbox、select radio button、choose file、input text、input password、select from list by index/value/lable、get table cell、get index in table column/row、wait for condition、wait unit page contains、wait until page contains element。
针对C/S自动化:Autoit用于对window图形界面进行自动化操作的软件,它可以模拟键盘操作、鼠标操作、窗口和控件来操作自动化,针对Windows32平台设计的,需安装AutoitLibrary。主要支持:Windows操作、Control操作即窗口上的按钮和文本框等、鼠标坐标操作、Process操作,run操作、
针对数据库自动化:databaseLibrary库,主要关键字有:connect to database、connect to database use custom params、disconnect from database、query、row count、execute sql script执行SQL文件、execute sql string执行SQL脚本;
针对接口自动化:requestsLibary,支持的关键字为:Create session、get request、post request、head request、to json文本转json。
遇到的问题如下:
【问题1】使用IEDriverServer.exe驱动,运行脚本时总提示找不到页面元素
运行脚本的时候总是提示找不到元素,解决办法是将ie的安全级别修改为低,而且将保护模式去掉。
【问题2】一些selenium无法定位元素
对于一些能过selenium无法定位的元素, 可以发散一下思路, 使用js解决,例:对于window.showModalDialog()模式打开的新窗口,通过selennium无法定位 ,使用js dom来解决.
【问题3】case跑完后,“Report”和“Log”按钮是灰色的,点击不了
启动任务管理器把浏览器进程杀掉,比如IEDriverServer.exe;
14、TCP三次握手、4次分手、HTTPS和HHTP的区别及HTTPs的实现方式
序列号seq:占4个字节,用来标记数据段的顺序,TCP把连接中发送的所有数据字节都编上一个序号,第一个字节的编号由本地随机产生;给字节编上序号后,就给每一个报文段指派一个序号;序列号seq就是这个报文段中的第一个字节的数据编号。
确认号ack:占4个字节,期待收到对方下一个报文段的第一个数据字节的序号;序列号表示报文段携带数据的第一个字节的编号;而确认号指的是期望接收到下一个字节的编号;因此当前报文段最后一个字节的编号+1即为确认号。
确认ACK:占1位,仅当ACK=1时,确认号字段才有效。ACK=0时,确认号无效
同步SYN:连接建立时用于同步序号。当SYN=1,ACK=0时表示:这是一个连接请求报文段。若同意连接,则在响应报文段中使得SYN=1,ACK=1。因此,SYN=1表示这是一个连接请求,或连接接受报文。SYN这个标志位只有在TCP建产连接时才会被置1,握手完成后SYN标志位被置0。
终止FIN:用来释放一个连接。FIN=1表示:此报文段的发送方的数据已经发送完毕,并要求释放运输连接
PS:ACK、SYN和FIN这些大写的单词表示标志位,其值要么是1,要么是0;ack、seq小写的单词表示序号。
三次握手过程理解:
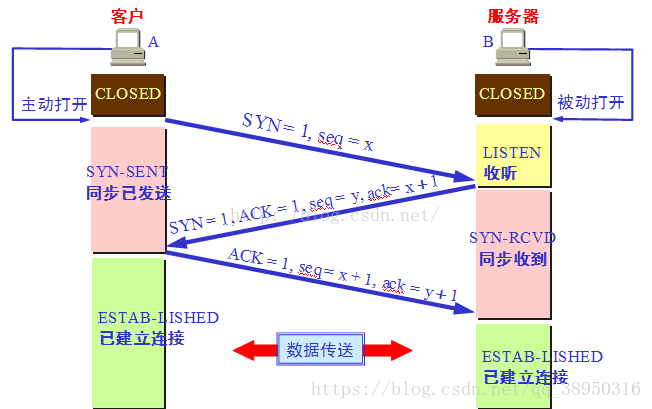
第一次握手:建立连接时,客户端发送syn包(syn=j)到服务器,并进入SYN_SENT状态,等待服务器确认;SYN:同步序列编号(Synchronize Sequence Numbers)。
第二次握手:服务器收到syn包,必须确认客户的SYN(ack=j+1),同时自己也发送一个SYN包(syn=k),即SYN+ACK包,此时服务器进入SYN_RECV状态;
第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=k+1),此包发送完毕,客户端和服务器进入ESTABLISHED(TCP连接成功)状态,完成三次握手。
四次挥手过程理解:
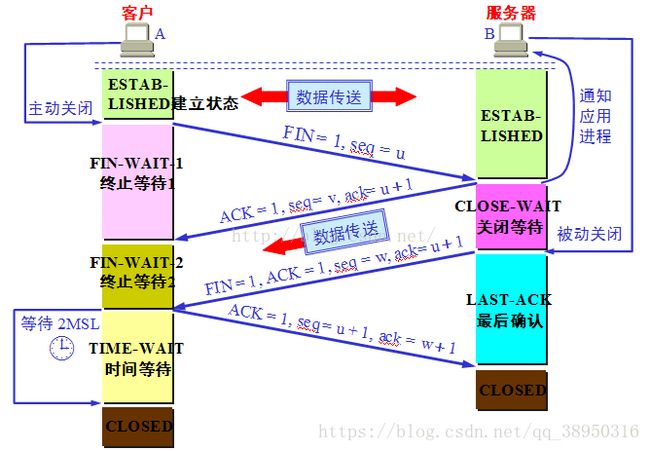
1)客户端进程发出连接释放报文,并且停止发送数据。释放数据报文首部,FIN=1,其序列号为seq=u(等于前面已经传送过来的数据的最后一个字节的序号加1),此时,客户端进入FIN-WAIT-1(终止等待1)状态。 TCP规定,FIN报文段即使不携带数据,也要消耗一个序号。
2)服务器收到连接释放报文,发出确认报文,ACK=1,ack=u+1,并且带上自己的序列号seq=v,此时,服务端就进入了CLOSE-WAIT(关闭等待)状态。TCP服务器通知高层的应用进程,客户端向服务器的方向就释放了,这时候处于半关闭状态,即客户端已经没有数据要发送了,但是服务器若发送数据,客户端依然要接受。这个状态还要持续一段时间,也就是整个CLOSE-WAIT状态持续的时间。
3)客户端收到服务器的确认请求后,此时,客户端就进入FIN-WAIT-2(终止等待2)状态,等待服务器发送连接释放报文(在这之前还需要接受服务器发送的最后的数据)。
4)服务器将最后的数据发送完毕后,就向客户端发送连接释放报文,FIN=1,ack=u+1,由于在半关闭状态,服务器很可能又发送了一些数据,假定此时的序列号为seq=w,此时,服务器就进入了LAST-ACK(最后确认)状态,等待客户端的确认。
5)客户端收到服务器的连接释放报文后,必须发出确认,ACK=1,ack=w+1,而自己的序列号是seq=u+1,此时,客户端就进入了TIME-WAIT(时间等待)状态。注意此时TCP连接还没有释放,必须经过2∗∗MSL(最长报文段寿命)的时间后,当客户端撤销相应的TCB后,才进入CLOSED状态。
6)服务器只要收到了客户端发出的确认,立即进入CLOSED状态。同样,撤销TCB后,就结束了这次的TCP连接。可以看到,服务器结束TCP连接的时间要比客户端早一些。
备注:
【问题1】为什么连接的时候是三次握手,关闭的时候却是四次握手?
答:因为当Server端收到Client端的SYN连接请求报文后,可以直接发送SYN+ACK报文。其中ACK报文是用来应答的,SYN报文是用来同步的。但是关闭连接时,当Server端收到FIN报文时,很可能并不会立即关闭SOCKET,所以只能先回复一个ACK报文,告诉Client端,"你发的FIN报文我收到了"。只有等到我Server端所有的报文都发送完了,我才能发送FIN报文,因此不能一起发送。故需要四步握手。
【问题2】为什么TIME_WAIT状态需要经过2MSL(最大报文段生存时间)才能返回到CLOSE状态?
答:虽然按道理,四个报文都发送完毕,我们可以直接进入CLOSE状态了,但是我们必须假象网络是不可靠的,有可以最后一个ACK丢失。所以TIME_WAIT状态就是用来重发可能丢失的ACK报文。在Client发送出最后的ACK回复,但该ACK可能丢失。Server如果没有收到ACK,将不断重复发送FIN片段。所以Client不能立即关闭,它必须确认Server接收到了该ACK。Client会在发送出ACK之后进入到TIME_WAIT状态。Client会设置一个计时器,等待2MSL的时间。如果在该时间内再次收到FIN,那么Client会重发ACK并再次等待2MSL。所谓的2MSL是两倍的MSL(Maximum Segment Lifetime)。MSL指一个片段在网络中最大的存活时间,2MSL就是一个发送和一个回复所需的最大时间。如果直到2MSL,Client都没有再次收到FIN,那么Client推断ACK已经被成功接收,则结束TCP连接。
【问题3】为什么不能用两次握手进行连接?
答:3次握手完成两个重要的功能,既要双方做好发送数据的准备工作(双方都知道彼此已准备好),也要允许双方就初始序列号进行协商,这个序列号在握手过程中被发送和确认。
现在把三次握手改成仅需要两次握手,死锁是可能发生的。作为例子,考虑计算机S和C之间的通信,假定C给S发送一个连接请求分组,S收到了这个分组,并发 送了确认应答分组。按照两次握手的协定,S认为连接已经成功地建立了,可以开始发送数据分组。可是,C在S的应答分组在传输中被丢失的情况下,将不知道S 是否已准备好,不知道S建立什么样的序列号,C甚至怀疑S是否收到自己的连接请求分组。在这种情况下,C认为连接还未建立成功,将忽略S发来的任何数据分 组,只等待连接确认应答分组。而S在发出的分组超时后,重复发送同样的分组。这样就形成了死锁。
【问题4】如果已经建立了连接,但是客户端突然出现故障了怎么办?
TCP还设有一个保活计时器,显然,客户端如果出现故障,服务器不能一直等下去,白白浪费资源。服务器每收到一次客户端的请求后都会重新复位这个计时器,时间通常是设置为2小时,若两小时还没有收到客户端的任何数据,服务器就会发送一个探测报文段,以后每隔75秒钟发送一次。若一连发送10个探测报文仍然没反应,服务器就认为客户端出了故障,接着就关闭连接。
HTTPS和HTTP的区别:
Http:超文本传输协议(Http,HyperText Transfer Protocol)是互联网上应用最为广泛的一种网络协议。设计Http最初的目的是为了提供一种发布和接收HTML页面的方法。它可以使浏览器更加高效。Http协议是以明文方式发送信息的,如果黑客截取了Web浏览器和服务器之间的传输报文,就可以直接获得其中的信息。
Https:是以安全为目标的Http通道,是Http的安全版。Https的安全基础是SSL。SSL协议位于TCP/IP协议与各种应用层协议之间,为数据通讯提供安全支持。SSL协议可分为两层:SSL记录协议(SSL Record Protocol),它建立在可靠的传输协议(如TCP)之上,为高层协议提供数据封装、压缩、加密等基本功能的支持。SSL握手协议(SSL Handshake Protocol),它建立在SSL记录协议之上,用于在实际的数据传输开始前,通讯双方进行身份认证、协商加密算法、交换加密密钥等。
二、Http与Https的区别
1、https协议需要到CA申请证书,一般免费证书较少,因而需要一定费用。(原来网易官网是http,而网易邮箱是https。)
2、http是超文本传输协议,信息是明文传输,https则是具有安全性的ssl加密传输协议。
3、http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
4、http的连接很简单,是无状态的。Https协议是由SSL+Http协议构建的可进行加密传输、身份认证的网络协议,比http协议安全。(无状态的意思是其数据包的发送、传输和接收都是相互独立的。无连接的意思是指通信双方都不长久的维持对方的任何信息。)
三、Https的优点
1、使用Https协议可认证用户和服务器,确保数据发送到正确的客户机和服务器。
2、Https协议是由SSL+Http协议构建的可进行加密传输、身份认证的网络协议,要比http协议安全,可防止数据在传输过程中不被窃取、修改,确保数据的完整性。
3、Https是现行架构下最安全的解决方案,虽然不是绝对安全,但它大幅增加了中间人攻击的成本。
四、Https的缺点(对比优点)
1、Https协议握手阶段比较费时,会使页面的加载时间延长近。
2、Https连接缓存不如Http高效,会增加数据开销,甚至已有的安全措施也会因此而受到影响;
3、SSL证书通常需要绑定IP,不能在同一IP上绑定多个域名,IPv4资源不可能支撑这个消耗。
4、Https协议的加密范围也比较有限。最关键的,SSL证书的信用链体系并不安全,特别是在某些国家可以控制CA根证书的情况下,中间人攻击一样可行。
五、Https的连接过程:https://blog.csdn.net/kobejayandy/article/details/52433660
图片中的过程是按8个步骤分的,但是网上有更详细的步骤,所以我把详细的过程和这个图片配在一起。
①客户端的浏览器向服务器发送请求,并传送客户端SSL 协议的版本号,加密算法的种类,产生的随机数,以及其他服务器和客户端之间通讯所需要的各种信息。
②服务器向客户端传送SSL 协议的版本号,加密算法的种类,随机数以及其他相关信息,同时服务器还将向客户端传送自己的证书。
③客户端利用服务器传过来的信息验证服务器的合法性,服务器的合法性包括:证书是否过期,发行服务器证书的CA 是否可靠,发行者证书的公钥能否正确解开服务器证书的“发行者的数字签名”,服务器证书上的域名是否和服务器的实际域名相匹配。如果合法性验证没有通过,通讯将断开;如果合法性验证通过,将继续进行第四步。
④用户端随机产生一个用于通讯的“对称密码”,然后用服务器的公钥(服务器的公钥从步骤②中的服务器的证书中获得)对其加密,然后将加密后的“预主密码”传给服务器。
⑤如果服务器要求客户的身份认证(在握手过程中为可选),用户可以建立一个随机数然后对其进行数据签名,将这个含有签名的随机数和客户自己的证书以及加密过的“预主密码”一起传给服务器。
⑥如果服务器要求客户的身份认证,服务器必须检验客户证书和签名随机数的合法性,具体的合法性验证过程包括:客户的证书使用日期是否有效,为客户提供证书的CA 是否可靠,发行CA 的公钥能否正确解开客户证书的发行CA 的数字签名,检查客户的证书是否在证书废止列表(CRL)中。检验如果没有通过,通讯立刻中断;如果验证通过,服务器将用自己的私钥解开加密的“预主密码”,然后执行一系列步骤来产生主通讯密码(客户端也将通过同样的方法产生相同的主通讯密码)。
⑦服务器和客户端用相同的主密码即“通话密码”,一个对称密钥用于SSL 协议的安全数据通讯的加解密通讯。同时在SSL 通讯过程中还要完成数据通讯的完整性,防止数据通讯中的任何变化。
⑧客户端向服务器端发出信息,指明后面的数据通讯将使用的步骤⑦中的主密码为对称密钥,同时通知服务器客户端的握手过程结束。
⑨服务器向客户端发出信息,指明后面的数据通讯将使用的步骤⑦中的主密码为对称密钥,同时通知客户端服务器端的握手过程结束。
⑩SSL 的握手部分结束,SSL 安全通道的数据通讯开始,客户和服务器开始使用相同的对称密钥进行数据通讯,同时进行通讯完整性的检验。
15、Jmeter分布式测试
JMeter分布式测试前提条件:系统的防火墙关闭,或者开放正确的端口;所有的客户端在相同的子网内;确定JMeter可以访问服务器;确保所有系统都适用相同的JMeter和Java版本;混合版本将不能正确工作;
搭建步骤:
在子系统中,进入JMeter/bin目录,并执行JMeter-server.bat(在Unix系统上执行JMeter-server);
主系统作为控制台,打开资源管理器,进入到JMeter/bin目录,在文本编辑器中打开JMeter.properties编辑remote_hosts=127.0.0.0.1这行添加子系统的IP的地址,多个用","隔开;
在顶部导航栏单击运行可以指定运行特定机器或者所有的;
控制机运用多台Jmeter负载机进行性能测试,被选中作为管理机的那台机器即控制机。Jmeter控制机也可以参与脚本的运行,同时它也可以担负着管理远程负载机指挥远程负载机运行的任务,并且收集远程负载机的测试结果;
负载机向应用服务器发起负载的机器,控制机同时也是一台负载机。Jmeter负载机受控制机管理。与其他支持远程运行的测试工具一样,负载机受控制机的管理首先要启动一个客户端程序(Jmeter-server.bat),这样控制机才可以接管负载机。控制机会把运行的脚本隐蔽的发送到远程负载机上。但是如果运行的测试脚本有参数文件及依赖的jar包时,控制机并不能把他们发送到远程负载机,这时就需要手动拷贝了。
运行的逻辑:
远程负载机首先启动Agent程序,待控制机连接;
控制机连接到远程负载机;
控制机发送指令(脚本及启动命令)启动线程;
负载机运行脚本,回传状态即测试结果;
控制机收集结果并显示;
16、Jmeter中Beanshell脚本编写
Jmeter中提供一种函数__time可以打印时间戳,用于获取当前时间;
年: yyyy 月:MM 日:dd
时: HH 分: mm 秒:ss
关于时间戳的格式,可以自由组合定义,这里我写成这样 yyyy-MM-dd HH:mm:ss
生成的函数是这样的:${__time(yyyy-MM-dd HH:mm:ss,)}
如果时间偏移需要打印,这时候不光想打印当前时间,还想打印明天,后天,甚至明年的时间就需要我们用BeanShell Sampler处理了。使用时直接${orderDate}和${senderDate}引用
import java.text.SimpleDateFormat;
import java.util.Calendar;
import java.util.Date;
try{
Date date =new Date(); //获取当前时间
SimpleDateFormat sf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String nowDate = sf.format(date);
Calendar cal = Calendar.getInstance();
cal.setTime(sf.parse(nowDate));
cal.add(Calendar.DAY_OF_YEAR,+0); #此处0指当前时间,+1为加一天,依次类推
String orderDate = sf.format(cal.getTime());
cal.add(Calendar.DAY_OF_YEAR,+365);
String senderDate = sf.format(cal.getTime());
vars.put("orderDate",orderDate);
vars.put("senderDate",senderDate);
}
catch(Exception e){
}Jmeter上传:
Jmeter上传文件首先确认参数名称、MIME类型、文件名称,或者直接在页面抓包后从请求头里面查看;打开HTTP请求在Files Upload中填写相应的参数。其次在Advanced里面选择Java类型;
Jmeter下载:
首先确定你的下载文件接口,确保接口响应正确;
其次Jmeter本身不支持将文件保存到本地的,需要写一点Java。添加beanshell sample写入Java:
import java.io.*;
byte[] result = prev.getResponseData();
String file_name = "D:\\gongju\\apache-jmeter-3.2\\bin\\download\\sqlEnt_${id}.zip";
File file = new File(file_name);
FileOutputStream out = new FileOutputStream(file);
out.write(result);
out.close();17、Jmeter断言
JMeter支持断言,断言、响应断言等;
18、Jmeter关联
通过正则表达式
19、JMeter相关知识
若请求参数为json串,则需要在HTTP信息头管理器中添加如下配置,而后在HTTP请求Content encoding字段值填写:utf-8,而后在Body Data中放入请求参数:Content-Type:application/json。
JMeter中Parameter和Body Data区别:前者为GET或者POST请求中URL中带的参数值;
JMeter中参数化的方法:
方法一:使用JMeter中的函数获取参数值,函数如:__Random,__threadNum,__CSVRead,__StringFromFile,具体调用方法如:${__Random(,,)}。
方法二:用户自定义变量,添加配置元件、用户自定义变量;
方法三:从CSV文件中读取,添加方式配置元件、CSV SET Config;
方法四:从数据库中读取:当参数的值没有规律且量比较大时可以选择这种方法;该方法需要下载mysql-connector的jar包,而后添加JDBC连接配置、添加JDBC连接请求;而后可以添加后置处理器如正则表达式获取查询到的结果;
做JDBC请求,首先需要两个jar包:首先需要两个jar包:mysql驱动-mysql-connector-java-5.1.13-bin.jar 和 sqlServer驱动-sqljdbc4.jar,将这两个jar包放到Jmeter目录中的lib文件下,然后重启Jmeter。而后:添加线程组、添加D+JDBC Connection Configuration、配置 JDBC Connection Configuration 基本参数(注意Variable Name命名必须和之后JDBC Request中的Variable Name 命名一致)Driver Class 可写成org.gjt.mm.mysql.Driver,也可写成com.mysql.jdbc.Driver,以响应正确为基准、添加JDBCrequest。
获取JDBC响应做接口关联,在JDBC request中添加变量及变量名如var_id,在新的JDBC request请求中输入Var_id_1即取第一行数据。
JMeter正则表达式提取器:
引用名称即变量名${name},()中表示你想要的值;模板$$表示你要用哪个正则表达式模板获取的值,-1代表全部、0代表随机、1代表第一个、2代表第二个,如果只有一个正则表达式一般就写1;$1$表示解析到的第一个值,若正则表达式有多个则可以$2$$3$等等。缺省值代表如果没匹配到给一个默认值;
正则表达式:.代表匹配任何字符串、+表示匹配一次或者多次、?表示不要太贪婪,在找到第一个匹配项后停止;
举例说明:
提取单个字符串:
假如想匹配Web页面的如下部分:name = "file" value = "readme.txt">并提取readme.txt。一个合适的正则表达式:name = "file" value = "(.+?)">。
():封装了待返回的匹配字符串。
.:匹配任何单个字符串。
+:一次或多次。
?:不要太贪婪,在找到第一个匹配项后停止。
提取多个字符串:
假如想匹配Web页面的如下部分:name = "file.name" value = "readme.txt">并提取file.name和readme.txt。一个合适的正则表达式:name = "(.+?)" value = "(.+?)"。这样就会创建2个组,分别用于$1$和$2$
比如:
引用名称:MYREF
模板:$1$$2$
如下变量的值将会被设定:
MYREF: file.namereadme.txt
MYREF_g0: name = "file.name"value = "readme.txt"
MYREF_g1: file.name
MYREF_g2: readme.txt
注意事项:
正则表达式提取中Apply to应该选择:Main sample only;
正则表达式中要检查的响应字段应该选择:主题;
响应断言中Apply to应该选择Main sample only;
响应断言中要测试的响应字段应该选择:响应文本;
响应断言中模式匹配规则:可以任意选择;
响应断言中要测试的模式:应为"success":${test};
20、JMeter之集合点
集合点实现仿真高并发测试,常见问题线程启动后就会直接发送测试请求,如果要模拟一瞬间高并发量测试的时候,需要调高线程数量,这很耗测试机的性能,往往无法支持较大的并发数,无法控制每次测试的瞬间并发量;如果使用constant throuput timer可以模拟较长时间的并发,但无法满足稳定的瞬间高并发测试;
针对该问题的解决办法:使用集合点:作用是阻塞线程直到指定的线程数量达到后一起释放,可以瞬间产生很大的压力;操作步骤:添加线程组、添加定时器、添加Synchronizing Timer。
Number of Simulated Users to Group by:即每集合够多少个模拟用户后发送一次测试请求;如果设置为0则等同于设置为线程组中的线程数;确保设置的值不大于它所在线程组包含的用户数;
Timeout in milliseconds:超时时间,即多少毫秒后同时释放已集结的的线程,发送测试请求;如果设置为0,Timer将等待线程数达到了"Number of Simultaneous Users to Group"中设置的值才释放。如果大于0,那么如果超过Timeout in milliseconds中设置的最大等待时间(毫秒为单位)后还没达到"Number of Simultaneous Users to Group"中设置的值,Timer将不再等待,释放已到达的线程。
21、JMeter配置元件
HTTP Cookie Manager用来存储浏览器产生的用户信息;
HTTP Header Manager信息头管理,常用信息头如下:
Accept:text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8
Accept-Encoding:gzip,deflate,br
Accept-Language:zh-CN,zh;q=0.8
Connection:keep-alive
User-Agent:Mozilla/5.0
Content-Type:
application/w-www-form-urlencoded:from表单数据被编码为key/value格式发送到服务器,是表单默认的提交数据格式;
mutiipart/form-data:需要在表单中进行文件上传时,就需要使用该格式;
application/json:JSON数据格式;
22、JMeter逻辑控制器
循环控制器:指定其子节点运行的次数,可以使用具体的数值,也可以设置为变量;如果设置了具体值的同时设置了线程组的循环次数和循环控制其的循环次数,那循环控制器的子节点运行的次数为两个数值相乘;
Foreeach控制器:
其一般和用户自定义变量一起使用,用于可以便利读取相关的返回值。该控制器下的采样器或控制器都会被执行一次或多次,每次读取不同的变量值;foreeach控制器通常和表达式提取器一起使用。表达式提取值为-1,表示取全部值,然后sampler在foreeach控制器下执行;
23、JMeter函数
__BeanShell:beanshell函数,其有两个参数,第一个参数是要执行的语句,可以是beanshell语句或者是文件地址,是必选参数;第二个参数是保存结果的变量名称,非必选参数。示例如下:
${__BeanShell(123*456)}:返回值56088;
${__BeanShell(source("function.bsh"))}:会执行外部脚本function.bsh,并返回结果;
${__BeanShell(import java.util.*;Properties props = System.getProperties();String osName = props.getProperty("os.name");if(osName.contains("Windows"))return 443;return 8443;)}:判断端口
与beanshell元件比较:
该函数与beanshell元件(beanshell sampler、beanshell preprocess等)作用是一样的,只是beanshell函数更常用于一些简单的判断或计算等,可以把少量的脚本放在函数中直接赋值给一个变量,而不用总是添加beanshell元件。
__regexFunction:正则表达式函数,该函数使用用户提供的正则表达式来解析前面的服务器响应(或者是某个变量值)。函数会返回一个有模板的字符串,其中携带有可变的值。
__counter:计数器函数
每次调用计数器函数都会产生一个新值,从1开始每次加1。计数器既可以被配置成针对每个虚拟用户是独立的,也可以被配置成所有虚拟用户公用的。
如果每个虚拟用户的计数器是独立增长的,那么通常被用于记录测试计划运行了多少遍。全局计数器通常被用于记录发送了多少次请求。
计数器使用一个整数值来记录,允许的最大值为2,147,483,647。
目前计数器函数实例是独立实现的(JMeter 2.1.1及其以前版本,使用一个固定的线程变量来跟踪每个用户的计数器,因此多个计数器函数会操作同一个值)。全局计数器(FALSE)每个计数器实例都是独立维护的。
该函数也有对应的配置元件:计数器,功能类似。
__intSum:整数求和函数,函数__intSum可以被用来计算两个或者更多整数值的合。至少需要两个整数,如果指定变量名则名称中必须包含一个非数字字母,否则它会被当成另一个整数值,而被函数用于计算。当有多个整数时点击添加按钮来增加参数,但是需要注意的是,添加完参数后,点击”生成”的函数默认是把手动添加的函数放在后面,这时需要手动调整变量名的位置,把它放到最后,否则会报错。
__longSum:长整型求和函数,该函数用来计算两个或更多长整型值的和,使用方法跟上面的__intSum函数一样。
__StringFormFile:读取文件中的字符串函数
该函数用来从文本文件中读取字符串。支持读取多个文件。
使用配置元件CSV Data Set Config ,也能达到相同的目的,而且方法更简单,但是它目前不支持多个输入文件。
每次调用函数,都会从文件中读取下一行。当到达文件末尾时,函数又会从文件开始处重新读取,直到最大循环次数。如果在一个测试脚本中对该函数有多次引用,那么每一次引用都会独立打开文件,即使文件名是相同的(如果函数读取的值,在脚本其他地方也有使用,那么就需要为每一次函数调用指定不同的变量名)。
如果在打开或者读取文件时发生错误,那么函数就会返回字符串"**ERR**"。
示例
${_StringFromFile(demo.txt,,,)} 读取demo.txt
${_StringFromFile(PIN#'.'DAT,,1,2)} 读取demo1.txt, demo2.txt
${_StringFromFile(PIN.DAT,,,2)} 读取demo.txt两次
函数的第三个参数:初始的序列号,如果省略,那么结束序列号就代表文件的循环读取次数。
函数的第四个参数:结束序列号,如果省略,那么序列号会无限增长。
需要在文件名中使用序列号:当使用序列号时,文件名需要使用格式字符串java.text.DecimalFormat。当前的序列号会作为唯一的参数。如果不指明可选的初始序列号,就使用文件名作为起始值。一些有用的格式序列如下:
#:插入数字,不从零开始,不包含空格。
000:插入数字,包含3个数字组合,不从零开始。
例如:
pin#'.'dat -> pin1.dat, ... pin9.dat, pin10.dat, ... pin9999.dat
pin000'.'dat -> pin001.dat ... pin099.dat ... pin999.dat ... pin9999.dat
pin'.'dat# -> pin.dat1, ... pin.dat9 ... pin.dat999
如果不希望某个格式字符被翻译,需要为它加上单引号。注意上面的"."是格式字符,必须被单引号所包含。
比如现在要同时读取两个文件,分别是PIN1.DAT, PIN2.DAT:
${_StringFromFile(PIN#'.'DAT,,1,2)}:同时读取 PIN1.DAT, PIN2.DAT。
${_StringFromFile(PIN.DAT,,,2)}:读取 PIN.DAT 两次。
${_StringFromFile(test#'.'txt,,1,2)}:同时读取test1.txt,test2.txt
__javaScript:函数__javaScript可以用来执行JavaScript代码片段(非Java),并返回结果值。JMeter的_javaScript函数会调用标准的JavaScript解释器,还可以直接调用jmeter的内置函数。请记得为文本字符串添加必要的引号。另外,如果表达式中有逗号,请确保对其转义。例如,${__javaScript('${sp}'.slice(7\,99999))},对7之后的逗号进行了转义。
__Random:随机数函数,函数__Random会返回指定最大值和最小值之间的随机数。
__split:字符串分割函数,函数__split会通过分隔符来拆分传递给它的字符串,并返回原始的字符串。如果分隔符紧挨在一起,那么函数就会以变量值的形式返回"?"。拆分出来的字符串,以变量${VAR_1}、{VAR_2}…以此类推的形式加以返回。分隔符默认是逗号,如果你想要多此一举,明确指定使用逗号,需要对逗号转义,如“\,”。例如,在测试计划中定义变量VAR="a||c|":
${__split(${VAR},VAR),|} :该函数调用会返回VAR变量的值,例如"a||c|",并设定VAR_n=4、VAR_1=a、VAR_2=?、VAR_3=c、VAR_4=?、VAR_5=null变量的值。
__setProperty:函数__setProperty用于设置JMeter属性的值。函数的默认返回值是空字符串,因此该函数可以被用在任何地方,只要对函数本身调用是正确的。通过将函数可选的第3个参数设置为"true",函数就会返回属性的原始值。属性对于JMeter是全局的,因此可以被用来在线程和线程组之间通信。
__time:函数__time可以通过多种格式返回当前时间。如果省略了格式字符串,那么函数会以毫秒的形式返回当前时间。其他情况下,当前时间会被转成简单日期格式。
__evalVar:函数__evalVar可以用来执行保存在变量中的表达式,并返回执行结果。如此一来,用户可以从文件中读取一行字符串,并处理字符串中引用的变量。2、例如,假设变量"query"中包含有"select ${column} from ${table}",而 "column"和"table"中分别包含有"name"和"customers",那么${__evalVar(query)}将会执行"select name from customers"。
__eval:函数__eval可以用来执行一个字符串表达式,并返回执行结果。如此一来,用户就可以对字符串(存储在变量中)中的变量和函数引用做出修改。例如,给定变量name=Smith、column=age、table=birthdays、SQL=select ${column} from ${table} where name='${name}',那么通过${__eval(${SQL})},就能执行"select age from birthdays where name='Smith'"。这样一来,就可以与CSV数据集相互配合,例如,将SQL语句和值都定义在数据文件中。
__escapeHtml:函数__escapeHtml用于转义字符串中的字符(使用HTML实体)。支持HTML 4.0实体
__unescapeHtml:函数__unescapeHtml用于反转义一个包含HTML实体的字符串,将其变为包含实际Unicode字符的字符串。支持HTML 4.0实体。如果函数不认识某个实体,就会将实体保留下来,并一字不差地插入结果字符串中。例如,">&zzzz;x"会变为">&zzzz;x"。
__FileToString:函数__FileToString可以被用来读取整个文件。每次对该函数的调用,都会读取整个文件。如果在打开或者读取文件时发生错误,那么函数就会返回字符串"**ERR**"。
24、JMeter正则表达式提取器
Jmeter接口自动化关键在于参数关联,比如需要登陆的接口,如何调用登陆口令,一个增删改查的闭环,接口参数的上下传递;
如登陆接口,在响应中返回一串token,则可在登陆接口后添加后置处理器-正则表达式提取,正则表达式中设置如下:
要检查的响应字段:主题
引用名称:center-token
正则表达式:"token":"(.*?)"
模板:$1$
匹配数字:0代表随机取值、1代表取第一个值、2代表取第二个值,依次类推;
此处正则表达式的写法是贪婪匹配token之后两个双引号之间的所有数据;
而后在接下来的接口中可以将获取的token作为变量调用,变量名为${center-token}。
正则表达式简要说明:
() 括起来的部分就是需要提取的,对于你要提的内容需要用小括号括起来
. 点号表示匹配任何字符串
+ 表示一次或多次匹配,*表示匹配所有
? 在找到第一个匹配项后停止,不加?表示找到最后一个匹配项停止
模板:用$$引用起来,如果在正则表达式中有多个正则表达式(多个括号括起来的东东),则可以是$2$,$3$等等,表示解析到的第几个值给user_id。例如:$1$表示匹配到的第一个值
匹配数字:0代表随机取值,-1代表所有值,此时提取结果是一个数组,其余正整数代表第几个匹配的内容提取出来。如果匹配数字选择的是-1,还可以通过${XX_1}的方式来取第1个匹配的内容,${XX_2}来取第2个匹配的内容。
25、JMeter自动生成测试报告
环境要求:
Jmeter3.0版本之后开始支持动态生成测试报告;
JDK版本1.7以上;
需要JMX脚本文件;
基本操作:
在脚本文件路径下,执行CMD命令:jmeter -n -t test.jmx -l result.jtl -e -o /tmp/ResultReport
参数说明:
-n:非GUI模式执行Jmeter;
-t:执行测试文件所在的位置;
-l:指定生成测试结果的保存文件,jtl文件格式;
-e:测试结束后,生成测试报告;
-o:指定测试报告的存放位置;
备注:结尾的ResultReport是自己手动创建的报告文件夹。每次启动命令之前,文件夹内容必须金额jtl文件一起清空;
考虑到每次执行命令都要先去目录下清空报告文件夹和jtl,还要敲命令,所以后续写了一个bat文件,每次执行bat都自动去清空之前的报告,然后执行命令:
接口运行自动化.bat代码如下:
del /s /Q D:\gongju\apache-jmeter-3.2\bin\result.jtl
rd /s /Q D:\gongju\apache-jmeter-3.2\bin\HttpReport
md D:\gongju\gongju\apache-jmeter-3.2\bin\HttpReport
jmeter -n -t D:\gongju\apache-jmeter-3.2\bin\lsmsp.jmx -l result.jtl -e -0 D:\gongju\apche-jmeter-3.2\bin\HttpReportdel是删除jtl
rd是删除报告文件夹
md是重建报告文件夹
26、Selenium原理
Selenium1.0和2.0,前者基于Selenium RC Server,后者加入了webdriver,前者每次起都要先Start Selenium Server然后再stop Selenium Server较为麻烦;
Selenium Grid组件专门用于远程分布式测试或并发测试,通过并发执行测试用例的方式可以提高测试用例的执行速度和效率,解决界面自动化测试执行速度过慢的问题;
为什么使用Selenium Grid?
A、在自动化测试用例不多的情况下,一台计算机可以在较短的时间内运行完所有的测试用例,并给出测试报告。但是随着目前计算机行业的发展,越来越多的项目横空出世,需要测试人员在较短的时间内完成成千上百个测试用例,此时仅依靠一台机器运行将无法满足实际需求;
B、越来越多的项目对浏览器兼容性要求也越来越高,需要在多种操作系统和各种流行的浏览器以及不同版本间进行兼容性测试,单个机器很难完成,我们可以使用分布式来执行大量的测试用例以满足短测试时间和兼容性测试的要求。
Selenium Grid的产生就是为了解决分布式运行自动化测试用例的需求,使用此组件可以在一台计算机上给多台计算机(不同操作系统和不同版本浏览器环境)分发多个测试用例从而并发执行,大大提高了测试用例执行效率。
Selenium Grid使用Hub和Node模式,一台计算机作为Hub(管理中心)管理其他多个Node节点计算机,Hub负责将测试用例分发给多台Node计算机执行,并收集多台Node计算机执行结果的报告,汇总后提交一份总的测试报告。
Hub:
- 在分布式测试模式中,只能有一台作为Hub的计算机;
- Hub负责管理测试脚本,并负责发送脚本给其他Node节点;
- 所有的Node节点计算机必须先在Hub的计算机中进行注册,注册成功后再和Hub计算机通信,Node节点计算机会告之Hub自己的相关信息,例如Node节点的操作系统和浏览器相关版本;
- Hub计算机可以给自己分配执行测试用例的任务;
- Hub计算机分发的测试用例任务会在各个Node计算机节点执行;
Node:
- 在分布式测试环境中,可以有一个或者多个Node节点;
- Node节点会打开本地的浏览器完成测试任务并返回测试结果给Hub;
- Node节点的操作系统和浏览器版本无须和Hub保持一致;
- 在Node节点上可以同时打开多个浏览器并执行测试任务;
分布式自动化测试环境准备:
A、下载JDK1.8安装文件,并配置环境变量,CMD命令窗口中执行java -version验证环境信息是否OK;
B、下载selenium-server-standalone-3.141.59.jar,并在Hub和Node中相同位置放置该文件,比如:D盘根目录下;
C、在Hub机上切换到selenium-server-standalone-3.141.59.jar所在的文件目录后执行如下语句:java -jar selenium-server-standalone-3.141.59.jar -role hub,其中-role hub参数用于启动一个hub服务,作为分布式管理中心,等待WebDriver客户端进行注册和请求,默认注册请求的地址为http://localhost:4444/grid/register,默认端口号为4444。该语句表示使用java命令把JAR文件作为程序执行,并将role参数值传递给JAR文件的函数,以此启动管理中心。
D、在Hub机(假如IP地址为192.168.1.107)中的Firefox浏览器地址栏中访问http://localhost:4444/grid/console,如果访问的网页中显示了“view config”的链接,表示Hub已经成功启动了。默认情况下,Selenium Grid使用4444作为服务端口号,在Node节点上也可以访问此网址,只要将localhost换成Hub的IP地址即可。
E、在Node节点(假如IP地址为192.168.1.113)中打开CMD切换到selenium-server-standalone-3.141.59.jar下,输入如下命令:
java -jar selenium-server-standalone-3.141.59.jar -role webdriver -hub http://192.168.1.107:4444/grid/register-Dwebdriver.firefox.driver="D:\geckodriver.exe" -port 6655 -maxSession 5 -browser browserName="firefox", maxInstances=5并执行;
F、再次访问网址http://localhost:4444/grid/console,验证Node节点是否已经在Hub上注册成功;
分布式脚本如下:
# coding:utf-8
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
driver = webdriver.Remote(
# 设定Node节点的URL地址,后续将通过访问这个地址连接到Node计算机
command_executor='http://10.118.52.25:6655/wd/hub',
desired_capabilities={
# 指定远程计算机执行使用的浏览器
"browserName":"firefox",
"video":"True",
# 远程计算机的平台
"platform":"WINDOWS"
}
)
print("Video:"+"http://www.biadu.com"+driver.session_id)
try:
driver.implicitly_wait(30)
driver.maximize_window()
driver.get("http://www.baidu.com")
assert u"百度" in driver.title
finally:
driver.quit()启动Hub时的参数如下:
| 参数名称 | 参数含义 |
| -role hub | 启动一个hub服务,等待node进行注册和请求 |
| -hubConfig [filename] | 设置一个符合Selenium Grid2规则的json格式的Hub配置文件 |
| -port | 指定Hub监听的端口 |
| -host | ip或host,指定Hub机的ip或者host值 |
| -newSessionWaitTimeout | 指定一个新的测试session等待执行的间隔时间,即一个代理节点上前后两个测试间的时间间隔,单位毫秒,默认为-1,即没有超时 |
| -browserTimeout | 浏览器无响应的超时时间 |
| -servlets xxx | 在hub上注册一个新的Servlet,访问地址为/grid/admin/xxx |
启用Node节点参数如下:
| 参数名称 | 参数含义 |
| -port | 节点计算机提供远程连接服务器的端口号,也是Hub监听的端口 |
| -role [node|wd|rc] | 为node时表示注册的RC可以支持所有版本的Selenium 为wd时表示注册的RC不支持Selenium1,也可以写成webdriver 为rc时表示注册的RC仅支持Selenium1 |
| -hub url_to_hub | -hub url_to_hub值为Hub启动的注册地址,默认为http://hub_ip:4444/grid/register,该选项包含了-hubHost和-hostPort两个选项 |
| -timeout | Hub在无法收到Node节点的任何请求后,在等待timeout设定的时间后会自动释放和Node节点的连接 注意:此参数不是WebDriver定位页面元素最大的等待时间 |
| -maxSession | 在一台节点计算机中,允许同时最多打开多少个浏览器窗口 |
| -browser | 设定节点计算机使用的浏览器信息。例如: browserName=firefox,version=3.6,firefox_binary=/home/myhomedir/firefox36/firefox,maxInstances=3,platform=LINUX version:设定浏览器版本号,当多个版本号共存的时候,需要明确使用哪个版本进行测试 platform:设定节点操作系统属性为Linux,可使用的值为Windows、Linux、Mac firefox_binary:设定Firefox浏览器的启动路径 maxInstances:最多允许同时启动3个Firefox浏览器窗口 |
| -registerCycle | 设定节点计算机间隔多少毫秒去注册一下Hub管理中心,以便重启Hub时不需要重新启动所有的代理节点 |
| -browserTimeout | 浏览器无响应的超时时间 |
| -nodeTimeout | 客户端超时时间 |
| -cleanupCycle | 代理节点检查超时的周期 |
| -nodeConfig jsonFile | 一个符合Selenium Grid2规则的Json格式的Node配置文件 |
| -proxy 代理类 | 默认指向org.openqa.grid.selenium.proxy.DefaultRemoteProxy |
| -browserTimeout | 浏览器无响应的超时时间 |
远程调用IE浏览器进行自动化测试:
Hub机器中注册命令不变;
Node节点中注册命令只需将浏览器名Firefox修改为Internet Explorer,浏览器驱动路径及名D:\geckodriver.exe修改为D:\IEDriverServer.exe即可;
java -jar selenium-server-standalone-3.141.59.jar -role webdriver -hub http://192.168.1.107:4444/grid/register-Dwebdriver.ie.driver="D:\IEDriverServer" -port 6655 -maxSession 5 -browser browserName="internet explorer", maxInstances=5
# coding:utf-8
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
driver = webdriver.Remote(
# 设定Node节点的URL地址,后续将通过访问这个地址连接到Node计算机
command_executor='http://10.118.52.25:6655/wd/hub',
desired_capabilities={
# 指定远程计算机执行使用的浏览器
# ie8以下版本写ie,ie8写iehta,ie11写internet explorer
"browserName":"internet explorer",
"video":"True",
# 远程计算机的平台
"platform":"WINDOWS" #或者写XP
}
)
print("Video:"+"http://www.biadu.com"+driver.session_id)
try:
driver.implicitly_wait(30)
driver.maximize_window()
driver.get("http://www.baidu.com")
assert u"百度" in driver.title
finally:
driver.quit()远程调用Chrome浏览器进行自动化测试
远程调用Chrome浏览器进行自动化测试的步骤和远程调用Firefox浏览器的步骤基本相同,只是节点注册Hub的命令行参数和测试程序有点变化,示例如下:
java -jar selenium-server-standalone-3.141.59.jar -role webdriver -hub http://192.168.1.107:4444/grid/register-Dwebdriver.chrome.driver="D:\chromedriver" -port 6655 -maxSession 5 -browser browserName="chrome", maxInstances=5
# coding:utf-8
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
driver = webdriver.Remote(
# 设定Node节点的URL地址,后续将通过访问这个地址连接到Node计算机
command_executor='http://10.118.52.25:6655/wd/hub',
desired_capabilities={
# 指定远程计算机执行使用的浏览器
"browserName":"chrome",
"video":"True",
# 远程计算机的平台
"platform":"WINDOWS"
}
)
print("Video:"+"http://www.biadu.com"+driver.session_id)
try:
driver.implicitly_wait(30)
driver.maximize_window()
driver.get("http://www.baidu.com")
assert u"百度" in driver.title
finally:
driver.quit()同时支持多个浏览器进行自动化测试
Selenium Grid支持同时将Node节点计算机上多个浏览器注册到Hub上,以便满足测试过程中对不同浏览器的需求;
Hub节点注册方式不变;
Node节点注册代码如下:
java -jar selenium-server-standalone-3.141.59.jar -role webdriver -hub http://192.168.1.107:4444/grid/register-Dwebdriver.ie.driver="D:\IEDriverServer" -Dwebdriver.chrome.driver="D:\chromedriver.exe" -Dwebdriver.firefox.driver="D:\geckodriver.exe" -port 6655 -maxSession 5 -browser browserName="internet explorer", maxInstances=5 -browser browserName="chrome", maxInstances=5 -browser browserName="firefox", maxInstances=5
# coding:utf-8
import random
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
browsers = ["firefox", "chrome", "internet explorer"]
driver = webdriver.Remote(
# 设定Node节点的URL地址,后续将通过访问这个地址连接到Node计算机
command_executor='http://10.118.52.25:6655/wd/hub',
desired_capabilities={
# 指定远程计算机执行使用的浏览器
"browserName":random.choice(browsers),
"video":"True",
# 远程计算机的平台
"platform":"WINDOWS"
}
)
print("Video:"+"http://www.biadu.com"+driver.session_id)
try:
driver.implicitly_wait(30)
driver.maximize_window()
driver.get("http://www.baidu.com")
assert u"百度" in driver.title
finally:
driver.quit()结合unittest实现分布式自动化测试
操作步骤:
A、在机器A和机器B的C盘根目录下均放入selenium-server-standalone-3.141.59.jar文件;
B、在机器B中打开CMD,并将CMD当前工作目录切换到C盘根目录,然后执行如下命令:
java -jar selenium-server-standalone-3.141.59.jar -role wendriver -hub http://192.168.1.107:4444/grid/register -Dwebdriver.firefox.driver="C:\geckodriver.exe" -port 6655 -maxSession 5 -browser browserName="firefox", firefox_binary="C:\Program Files\Mozilla Firefox\firefox.exe",platform="WINDOWS", maxInstances=5
# -*- coding:utf-8 -*-
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import unittest
import time
from HTMLTestRunner import HTMLTestRunner
class SeleniumGridTest(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Remote(
command_executor='http://192.168.1.113:6655/wd/hub',
desired_capabilities={
"browserName":"firefox",
"video":"True",
"platform":"WINDOWS"
}
)
self.driver.implicitly_wait(10)
print("Video:"+"http://www.baidu.com"+self.driver.session_id)
def testSogou(self):
self.driver.maximize_window()
self.driver.get("http://www.sogou.com")
assert u"搜狗" in self.driver.title
elem = self.driver.find_element_by_id("query")
elem.send_keys(u"selenium")
elem.send_keys(Keys.ENTER)
time.sleep(3)
print("done")
def tearDown(self):
self.driver.quit()
def suite():
suite1 = unittest.TestLoader.loadTestsFromTestCase(SeleniumGridTest)
return unittest.TestSuite(suite1)
def run(suite,report="d:\seleniumGridTest.html"):
with open(report, 'wb') as fp:
runner = HTMLTestRunner(stream=fp,verbosity=2,title=u"分布式自动化测试",description=u"测试报告描述")
runner.run(suite)
if __name__=='__main__':
run(suite())Selenium Grid实现并发的分布式自动化测试
Selenium Grid不仅支持在同一台机器上同时启动好几个浏览器并发跑测试用例,也支持同时在多台机器上启动不同的浏览器并发跑测试用例;
操作步骤如下:
A、在机器A、B、C的C盘根目录下均放入selenium-server-standalone-3.141.59.jar文件;
B、在机器A中启动Node节点服务:java -jar selenium-server-standalone-3.141.59.jar -role hub;重新打开一个CMD执行如下命令:java -jar selenium-server-standalone-3.141.59.jar -role webdriver -hub http://192.168.1.107:4444/grid/register-Dwebdriver.ie.driver="D:\IEDriverServer" -port 6655 -maxSession 5 -browser browserName="internet explorer", maxInstances=5;
C、在机器B中启动Node节点服务:java -jar selenium-server-standalone-3.141.59.jar -role webdriver -hub http://192.168.1.107:4444/grid/register-Dwebdriver.firefox.driver="D:\geckodriver.exe" -port 6655 -maxSession 5 -browser browserName="firefox", maxInstances=5
D、在机器C中启动Node节点服务:java -jar selenium-server-standalone-3.141.59.jar -role webdriver -hub http://192.168.1.107:4444/grid/register-Dwebdriver.chrome.driver="D:\chromedriver" -port 6655 -maxSession 5 -browser browserName="chrome", maxInstances=5
备注:注册的A、B和C机器节点的端口号必须一致;
27、Pytest原理
Python通用测试框架大多用Unittest+HTMLTestRunner,而pytest相对该框架有丰富的plugins;
pytest是一个非常成熟的全功能的Python测试框架,主要有以下几个特点:
A、简单灵活,容易上手,自动化加载函数与模块;
B、支持参数化,支持运行由nose、unittest编写的测试用例,支持失败重跑,支持多线程跑用例;
C、能够支持简单的单元测试和复杂的功能测试,还可以用来做selenium/appuium等自动化测试、接口测试(pytest+requests);
D、pytest具有很多第三方插件,并且可以自定义扩展,比较好用的pytest-selenium(集成selenium)、pytest-html(完美html测试报告生成)、pytest-rerunfailures(失败case重复执行)、pytest-xdist(多CPU分发)等;
E、测试用例的skip和xfail处理;
F、可以很好的和Jenkins集成;
G、report---allure也支持pytest。
pytest测试样例:
A、测试文件以test_开头(以_test结尾也可以);
B、测试类以Test开头,并且不能带有init方法;
C、测试函数以test_开头;
D、断言使用基本的assert即可;
pytest运行模式:
pytest的多种运行模式,让测试和调试变得更加得心应手,运行pytest时会找当前目录及其目录中的所有test_*.py或者*_test.py格式的文件及以test开头的方法或者class,不然就会提示找不到可以运行的case;
运行后生成测试报告:
安装pytest-html:pip install -U pytest-html
运行模式:pytest --html=report.html
运行指定的case:
当我们写了较多的cases时,如果每次都要全部运行以便,无疑是浪费时间,通过指定case来运行就很方便;
运行模式:
模式1:直接运行test_se.py文件的所有cases;
模式2:运行rest_se.py文件中TestClassOne这个class下的两个cases;
模式3:运行test_se.py文件中TestClassTwo这个class下的test_one。
定义class时,需要以T开头,不然pytest是不会去执行该class的。
多进程运行cases:
当cases量很多时,运行时间也会变的很长,如果想缩短脚本运行的时长,就可以用多进程来运行;
安装pytest-xdist:pip install -U pytest-xdist
运行模式:pytest test_se.py -n NUM,其中NUM是填写并发的进程数;
重试运行cases:
在做接口测试时,有时会遇到503或短时的网络波动,导致case运行失败,此时可以通过重试运行cases的方式来解决
安装pytest-rerunfailures:pip install -U pytest-rerunfailures;
运行模式:pytest test_se.py --reruns NUM;
显示print内容:
在运行测试脚本时,为了调试或打印一些内容,我们会在代码加些print内容,但在运行pytest时,这些内容不会显示出来,如果带上-s就可以显示了;
pytest test_se.py -s
此外,pytest的多种运行模式是可以叠加的比如让4个进程运行:
pytest test_se.py -s -n 4
测试函数标记:
一个标记可以应用在多个函数上;
一个函数可以有多个标记;
被标记的在不同文件夹下也可以被执行;
应用场景:我们的目的是只做冒烟测试,没必要对全量的case进行执行,我们就可以把需要smoke的case标记为smoke就可以了,到时候我们用pytest -m "smoke" 就ok;
具体标记如下:
语法:@pytest.mark.marker_value,如果标记smoke可以用@pytest.mark.smoke
举例为:
test_assert.py
import tasks,pytest
@pytest.mark.single
@pytest.mark.smoke
def test_smoke1():
with pytest.raises(TypeError):
tasks.add(task="string")
@pytest.mark.smoke
def test_smoke2():
with pytest.raises(TypeError):
tasks.add(task="string")
def test_except():
with pytest.raises(TypeError):
tasks.add(task="string")
@pytest.mark.smoke
def test_smoke03():
with pytest.raises(TypeError):
tasks.add(task="string")
@pytest.mark.smoke
def test_smoke04():
with pytest.raises(TypeError):
tasks.add(task="string")
test_task.py
import tasks
import pytest
@pytest.mark.smoke
def test_add_exception():
with pytest.raises(ValueError):
tasks.start_tasks_db('/','mysql')
def test_smoke05():
with pytest.raises(TypeError):
tasks.add(task="string")
执行结果:

也可以标记之间使用and、or、not关键字
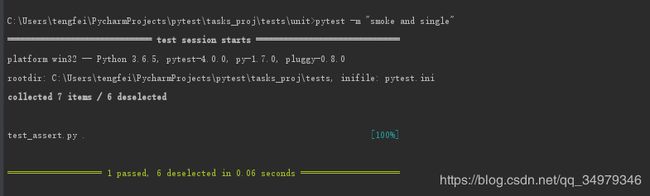
使用and是要有smoke和single标签才能被运行;
or是运行smoke和single标签的全部case;
not smoke是运行没有含smoke的标签;
跳过测试(skip、skipif、xfail)
skip只要标记skip不管是什么都要skip;
skipif是有条件的skip;
xfail是前两个标记之后,不会执行,xfail标记会执行,只是提前告诉pytest预期失败;
from collections import namedtuple
import pytest
Task=namedtuple('Task',['summary','owner','done','id'])
Task.__new__.__defaults__=(None,None,False,None)
@pytest.mark.skip(reason=" please skip,unsupport this case now")
#养成良好的习惯,当跳过的时候一定要加 reason ,同事看了就很明白了
def test_01():
t1=Task()
t2=Task()
assert t1 == t2
@pytest.mark.skipif(1>0,reason="不想执行")
#这个是条件执行,当表达式 True 就跳过,fail 就执行 ,同样也要加上reason
def test_02():
t1=Task()
t2=Task()
assert t1 == t2
@pytest.mark.xfail
#预期是失败的,结果执行通过, 会被标记为 Xpass
def test_03():
t1=Task()
t2=Task()
assert t1 == t2
@pytest.mark.xfail
#预期失败,确实执行失败了,会被标记为 xfail ,
def test_04():
t1=Task()
t2=Task()
assert t1 != t2

python运行脚本的三种模式
通过查阅资料才发现,原来python的运行脚本的方式有多种:
例如普通模式运行,不会自动去加载测试用例执行
unittest 测试框架运行模式,可以自动去发现testcase并执行
pytest 测试框架运行模式,就是我们上面2个步骤都是使用pytest测试框架运行的
重要原则:第一次按照何种模式执行测试用例,后续都会按照这种方式去执行
28、存储过程
create procedure 过程名([in|out|inout] 参数名 数据类型) 过程体;
参数:
IN:该参数的值必须在调用存储过程时指定,在存储过程中修改该参数的值不能被返回,为默认值;
OUT:该参数值可在存储过程中被改变,并可返回;
INOUT:该参数值调用时可指定和返回;
过程体起开始和结束使用BEGIN和END标识符;
变量:declare 变量名1 数据类型 [默认值];
变量赋值:set 变量名=变量值;
删除存储过程:drop procedure 过程名;
存储过程的作用:
生成批量测试数据、增强SQL语言的功能和灵活性、减少网络流量和提高执行速度;
MySQL默认以";"为分隔符,如果没有声明分割符,则编译器会把存储过程当成SQL语句进行处理,因此编译过程会报错,所以要事先用“DELIMITER //”声明当前段分隔符,让编译器把两个"//"之间的内容当做存储过程的代码,不会执行这些代码;“DELIMITER ;”的意为把分隔符还原。
IN参数例子
DELIMITER //
CREATE PROCEDURE in_param(IN p_in int)
BEGIN
SELECT p_in;
SET p_in=2;
SELECT p_in;
END;
//
DELIMITER ;
#调用
SET @p_in=1;
CALL in_param(@p_in);
SELECT @p_in;OUT参数例子
#存储过程OUT参数
DELIMITER //
CREATE PROCEDURE out_param(OUT p_out int)
BEGIN
SELECT p_out;
SET p_out=2;
SELECT p_out;
END;
//
DELIMITER ;
#调用
SET @p_out=1;
CALL out_param(@p_out);
SELECT @p_out;INOUT参数例子
#存储过程INOUT参数
DELIMITER //
CREATE PROCEDURE inout_param(INOUT p_inout int)
BEGIN
SELECT p_inout;
SET p_inout=2;
SELECT p_inout;
END;
//
DELIMITER ;
#调用
SET @p_inout=1;
CALL inout_param(@p_inout) ;
SELECT @p_inout;#变量作用域
DELIMITER //
CREATE PROCEDURE proc()
BEGIN
DECLARE x1 VARCHAR(5) DEFAULT 'outer';
BEGIN
DECLARE x1 VARCHAR(5) DEFAULT 'inner';
SELECT x1;
END;
SELECT x1;
END;
//
DELIMITER ;
#调用
CALL proc();
IF-THEN-ELSE语句
#条件语句IF-THEN-ELSE
DROP PROCEDURE IF EXISTS proc3;
DELIMITER //
CREATE PROCEDURE proc3(IN parameter int)
BEGIN
DECLARE var int;
SET var=parameter+1;
IF var=0 THEN
INSERT INTO t VALUES (17);
END IF ;
IF parameter=0 THEN
UPDATE t SET s1=s1+1;
ELSE
UPDATE t SET s1=s1+2;
END IF ;
END ;
//
DELIMITER ;
CASE-WHEN-THEN-ELSE语句
#CASE-WHEN-THEN-ELSE语句
DELIMITER //
CREATE PROCEDURE proc4 (IN parameter INT)
BEGIN
DECLARE var INT;
SET var=parameter+1;
CASE var
WHEN 0 THEN
INSERT INTO t VALUES (17);
WHEN 1 THEN
INSERT INTO t VALUES (18);
ELSE
INSERT INTO t VALUES (19);
END CASE ;
END ;
//
DELIMITER ;
循环语句
WHILE-DO…END-WHILE
DELIMITER //
CREATE PROCEDURE proc5()
BEGIN
DECLARE var INT;
SET var=0;
WHILE var<6 DO
INSERT INTO t VALUES (var);
SET var=var+1;
END WHILE ;
END;
//
DELIMITER ;
REPEAT...END REPEAT
此语句的特点是执行操作后检查结果
DELIMITER //
CREATE PROCEDURE proc6 ()
BEGIN
DECLARE v INT;
SET v=0;
REPEAT
INSERT INTO t VALUES(v);
SET v=v+1;
UNTIL v>=5
END REPEAT;
END;
//
DELIMITER ;
LOOP...END LOOP
DELIMITER //
CREATE PROCEDURE proc7 ()
BEGIN
DECLARE v INT;
SET v=0;
LOOP_LABLE:LOOP
INSERT INTO t VALUES(v);
SET v=v+1;
IF v >=5 THEN
LEAVE LOOP_LABLE;
END IF;
END LOOP;
END;
//
DELIMITER ;29、数据库常见关键字
查询单个列、全部列;
消除重复列及对查询结果命名;
大小值比较、大于及小于以及确定具体范围;
确定集合是否有空值,in、not in、null及not null;
字符匹配:%和_;
结果排序及分组统计order by和group by;分组筛选后建议用having关键字;
聚集函数:count、sum、avg、max及min;
集合函数:union、intersect、except;
连接查询:join、left join、right join及full join;
30、视图的创建及作用
create view 视图名 as select 语句;
删除语句:drop view 视图名;
视图的作用:数据库视图允许简化复杂查询、有助于限制对特定用户的数据访问提供额外的安全层、数据库视图能够实现向后兼容;
注意事项:性能方面视图查询数据可能会很慢,特别是如果视图是基于其他视图创建的;表依赖关系:每当更改与其他相关的表结构时都必须更改视图;
31、索引的创建及用途
create [无|unique|fulltext] index 索引名(字段名)
删除索引:drop index 索引名 on 表名;
索引的作用:加快数据检索速度、在分组和排序语句中可以减少查询中分组和排序时所消耗的时间;在表连接时可以加速表与表之间的连接;
缺点:过多的使用索引提高了索引速度,但却降低了表的更新速度;创建和维护索引会耗费时间且随数据量的增加而增加;
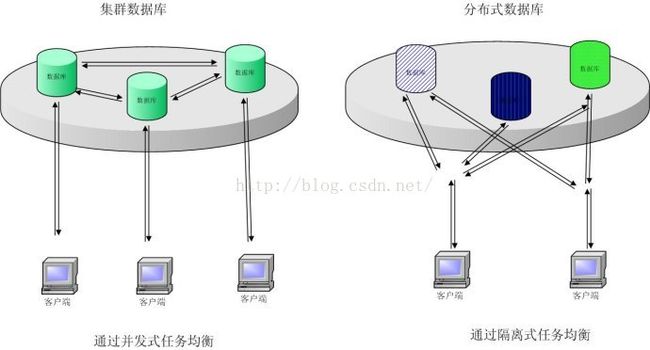
32、数据库集群
数据库集群的作用:通过使用数据库集群可以使读写分离、提高数据库的性能和可靠性;
其原理:MySQL是支持分布式的,其强大的一个功能就是实现读写分离,原理是让主数据库处理事务性查询,而从数据库处理select查询。数据库复制被用来把事务性查询导致的变更同步到集群中的从数据库中,从而使主数据库与从数据库的数据保持一致;

数据库集群和分布式的区别:
分布式是将不同的业务分布在不同的地方。集群是将几台服务器集中在一起,实现同一业务。分布式的每个节点都可以做集群,而集群并不一定是分布式;
分布式是以缩短单个任务的执行时间来提升效率,集群则是通过提高单位时间内的执行任务数来提升效率;
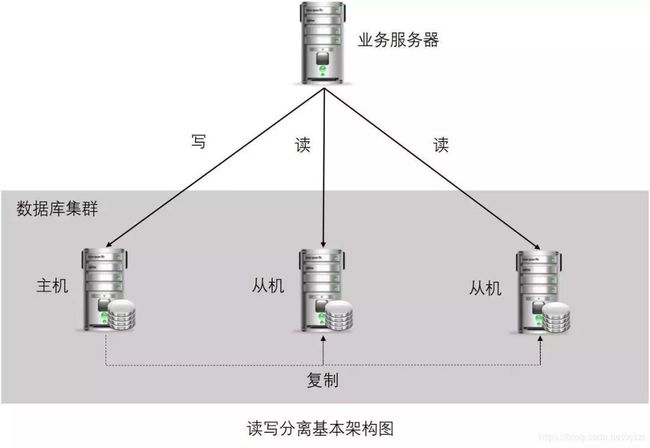
数据库读写分离:
原理:通过数据冗余将数据库读写操作分散到不同的节点上;
基本实现:数据库搭建主从服务器,一主一从或一主多从;数据库主机负责写操作,从机负责读操作;数据库主机通过复制将数据同步到从机,每台数据库服务器都存储了所有的业务数据;业务数据将写操作发给数据库主机,读操作发给数据库主机;
读写分离适用场景:并发量大、单机已经不能响应数量的并发请求、读远大于写的场景、数据实时性要求不那么严格的业务;
数据库分库分表:
基本思想:把一个数据库切分成多个部分放到不同的数据库上,从而缓解单一数据库的性能问题;
单台数据库存在的瓶颈:
数据量太大读写性能下降,即使有索引、索引也变得很大性能同样下降;
数据文件变大,数据库备份和恢复需要耗费很长的时间;
数据文件越大、极端情况下丢失数据的风险越高;
读写分离分散数据库读写的压力、分库分表分散存储压力;
适用场景优化顺序:
硬件优化、数据库调优例如增加索引和优化慢查询;引入缓存减少数据库压力、程序和数据库表优化重构、读写分离和分库;
33、Linux常用命令
ps 命令:给出当前系统中进程的快照,-a参数代表all,其通常使用管道结合grep命令进行过滤;比如:
查找Java相关的进程:ps -ax|grep java;
根据CPU的使用升序排序:ps -aux --sort -pcpu;;
只显示前10个:head -n 10;
pstree命令:以树状图显示进程之间的关系,方便监控目标服务关联的资源实行情况,增加性能分析的准确性;
top命令:实时显示当前进程和其他状况,且是一个动态的不断刷新的过程;
free -m命令:能够让你清楚的了解当前系统内存消耗情况;
vmstat命令是最常见的Linux监控工具,可以展示给定时间间隔的服务器状态值,包括服务器的CPU使用率、内存使用情况、虚拟交换情况、IO读写情况;一般有两个参数:第一个采样的时间间隔数,第二个采样的次数;
sar命令:目前Linux机上最全面的系统性能分析工具之一,包括:文件的读写情况、系统的使用情况、磁盘IO、CPU效率、内存使用情况等;
df -h:显示磁盘使用情况;
mkdir命令新建目录:
同时创建多个目录,如a、b和c:mkdir a b c或者mkdir {a,b,c};
使用-p级联创建目录:mkdir -p a/b/c;
删除目录命令:rmdir或者rm;
删除目录可以同时删除多个:rmdir a b c;
删除目录且不需要目录为空:rm -r a;
文件类型查看命令:file,在不确定文件类型的时候通过该命令可以查看文件类型,如文本文件、二进制文件和压缩文件;
新建文件命令:touch命令;若文件不存在则创建该文件,若文件存在则更改文件的时间戳,不修改文件内容;
复制文件命令:cp 源文件名 目标文件名;
复制目录命令:cp -r 目录1 目录2;
删除文件命令:rm;
删除目录:rm -r,强制删除rm -rf;
文件移动和文件重命名:mv a b,即将文件a移动到b,若b已存在则覆盖;
将文件a和b移动到目录lzl下:mv a b lzl
从前到后逐页显示文件内容,但不可分页:more 文件名;
逐页显示文件内容,但可上下分页:less 文件名;
显示整个文件内容:cat 文件名;
显示指定行数的头内容:head -10 文件名;
显示指定行数的尾内容:tail -10 文件名;
文件搜索命令:find
查找文件名和目录,查找cotp下的system.log文件:find cotp -name system.log;
根据文件大小搜索,搜索大于100M的文件:find cotp -size +100M;
根据子符搜索:find cotp -type d,查找目录文件;
文本编辑命令:vim
输入“:!q”命令回车强制退出;
行间快速移动:使用set nu在编辑器中显示行号,set nonu取消行号显示;gg快速跳转到文件首行,shift+g跳到文件末尾,#快速跳转到文件的#行;
34、自动化部署
引入自动化部署的原因:项目模块多服务多、迭代发布频繁一天发几十个包、手动部署易出错;
自动化部署的步骤:拉取代码,从GIT或者SVN上、编译打包maven,gradle、远程部署,将打好的包部署到目标服务器上;
自动化构建工具:Jenkins;
构建过程:新建job即名项目名称后选择自由项目模式、拉去Git管理的源代码,输入git库的地址和拉取代码的账号信息、编译打包(因公司使用maven打包,所以需要maven插件以及版本)并输入maven打包命令(clean package -U -Dmaven.test.skip=true表示跳过单元测试减少打包时间),构建后操作即大送到目标服务器并执行相应的脚本;
备注:上述为简单过程,实际操作过程还要动态替换配置文件、全局变量等需要使用sed命令执行相应的替换;
异常处理:
编译失败:失败原因可能是依赖包没提交、缺少类文件、符号错误;
文件或目录不存在:修改Jenkins配置;
工程目录变更导致失败:清理工作区间后再构建;
服务器没启动:检查日志文件查看错误;常见问题:disconf配置问题,如kafka连接、数据库连接、Redis连接等;或者依赖的基础环境不通如网络环境、数据库环境、中间件环境;代码问题;
包没更新:多见于docker平台或中转机/app/appsystem/xxx/apps目录下只能有一个包,多余的就是包号识别错误,删除后重新发布下即可;
Redis异常:日志中报大量连接REDIS超时错误:找到并ping下REDIS的地址,确认目标服务器是否可以连通、Telnet判断服务是否正常;
KAFKA问题:数据没有被消费、没有到指定系统
根据业务流程检查数据流向,确定数据在哪个环节出错。根据主题在kafak平台查找信息,检查是否有大量未处理的数据(重置索引解决);
35、cookie和session的区别
cookie数据存在客户的浏览器上,session数据放在服务器上;
cookie不是很安全,别人可以分析存在本地的cookie并进行cookie欺骗;
session会在一定时间内保存在服务器上,当访问增多时,会比较占用服务器的性能;
建议将登录信息等重要信息存为session,其他信息如果需要保留存在cookie中;
36、POST和GET的却别
get请求的数据附加在URL上,以?分隔URL和传输数据,多个参数用&连接。URL的编码格式使用ASCII编码,而不是Unicode,即所有的非ASCII字符都要编码之后再传输;
POST请求会把请求的数据放置在HTTP请求包的包体中;总之就是get请求的数据暴露在地址栏中,而POST请求的则不会;
传输数据的大小:在HTTP规范中没有对URL的长度和传输的数据大小进行限制,但在实际开发过程中,对于GET,特定的浏览器和服务器对URL长度有限制;
POST的安全性更高:get请求可能会造成跨网站请求攻击;
37、Python是如何进行内存管理的
垃圾回收、引用计数
38、python中yield的用法
yield简单来说就是一个生成器,这样的函数会记住上次返回时函数体的位置;
39、迭代器和生成器的区别
答:(1)迭代器是一个更抽象的概念,任何对象,如果它的类有next方法和iter方法返回自己本身。对于string、list、dict、tuple等这类容器对象,使用for循环遍历是很方便的。在后台for语句对容器对象调用iter()函数,iter()是python的内置函数。iter()会返回一个定义了next()方法的迭代器对象,它在容器中逐个访问容器内元素,next()也是python的内置函数。在没有后续元素时,next()会抛出一个StopIteration异常
(2)生成器(Generator)是创建迭代器的简单而强大的工具。它们写起来就像是正规的函数,只是在需要返回数据的时候使用yield语句。每次next()被调用时,生成器会返回它脱离的位置(它记忆语句最后一次执行的位置和所有的数据值)
区别:生成器能做到迭代器能做的所有事,而且因为自动创建了__iter__()和next()方法,生成器显得特别简洁,而且生成器也是高效的,使用生成器表达式取代列表解析可以同时节省内存。除了创建和保存程序状态的自动方法,当发生器终结时,还会自动抛出StopIteration异常
40、大数据文件的读取
① 利用生成器generator;
②迭代器进行迭代遍历:for line in file;
41、Python中的特定方法
字符串中的前导空格就是出现在字符串中第一个非空格字符前的空格:ls.lstrip();
字符串转小写:ls.lower()
字符转大写:ls.upper()
分隔字符串:ls.split(',')
将指定字符添加到字符串中:'.'.join(ls)
计算一个文件中的大写字母数量:
>>> import os
>>> os.chdir('C:\\Users\\lifei\\Desktop')
>>> with open('Today.txt') as today:
count=0
for i in today.read():
if i.isupper():
count+=1
print(count)
复制代码42、random函数
random()是python中生成随机数的函数,是由random模块控制,random()函数不能直接访问,需要导入random模块,然后再通过相应的静态对象调用该方法才能实现相应的功能;
random.random():该方法返回一个随机数,其在0和1的范围之内;
random.uniform(start,stop):其在指定范围内生成随机数,其有两个参数,一个是范围上限,一个是范围下限;
random.randint(start,stop):随机生成指定范围内的整数;
random.randrange(6,28,3):传三个参数,上限、下限、递增增量;
random.choice():从中获取一个随机元素,如random.choice("www.oldboyedu.com")返回值为:w;
random.shuffle():讲一个列表中的元素打乱,随机排序;即:random.shuffle(ls)/print(ls)。无返回值;
random.sample():从指定序列中获取指定长度的片段,原序列不会改变,两个参数:指定序列、获取片段的长度;
43、python中多线程是如何实现的
一个线程就是一个轻量级进程,多线程能让我们一次执行多个线程。我们都知道,Python是多线程语言,其内置有多线程工具包。
Python中的GIL(全局解释器锁)确保一次执行单个线程。一个线程保存GIL并在将其传递给下个线程之前执行一些操作,这会让我们产生并行运行的错觉。但实际上,只是线程在CPU上轮流运行。当然,所有的传递会增加程序执行的内存压力。
44、python2和python3的区别
Python3 使用 print 必须要以小括号包裹打印内容,比如 print('hi')
Python2 既可以使用带小括号的方式,也可以使用一个空格来分隔打印内容,比如 print 'hi'
python2 range(1,10)返回列表,python3中返回迭代器,节约内存
python2中使用ascii编码,python中使用utf-8编码
python2中unicode表示字符串序列,str表示字节序列
python3中str表示字符串序列,byte表示字节序列
python2中为正常显示中文,引入coding声明,python3中不需要
python2中是raw_input()函数,python3中是input()函数
45、列举python中可变数据类型和不可变数据类型
不可变的数据类型:数值型、字符串型、元组型;
可变性:列表和字典类型;
46、列出5个python标准库
os、sys、re、math、datetime
47、分别从前端、后端和数据阐述Web项目的性能优化
前端优化:减少HTTP请求、html/cSS放页面上部,JS放下面因为后者加载慢页面显示不全;
后端优化:缓存存储、读写次数高变化少的数据;异步方式耗时操作采用异步形式;
数据库:存REDIS、索引、外键、主从分离、分表分库;
48、递归的优缺点
优点:
1. 简洁
2.在树的前序,中序,后序遍历算法中,递归的实现明显要比循环简单得多。
缺点:
1.递归由于是函数调用自身,而函数调用是有时间和空间的消耗的:每一次函数调用,都需要在内存栈中分配空间以保存参数、返回地址以及临时变量,而往栈中压入数据和弹出数据都需要时间。->效率
2.递归中很多计算都是重复的,由于其本质是把一个问题分解成两个或者多个小问题,多个小问题存在相互重叠的部分,则存在重复计算,如fibonacci斐波那契数列的递归实现。->效率
3.调用栈可能会溢出,其实每一次函数调用会在内存栈中分配空间,而每个进程的栈的容量是有限的,当调用的层次太多时,就会超出栈的容量,从而导致栈溢出。->性能