在使用R语言进行数据分析时,我们发现一个重要的部分就是对数据的处理和转化。真正的统计建模以及数据可视化均有相应的函数来完成——需要我们把数据整理(tidy)成所用函数需要的格式。
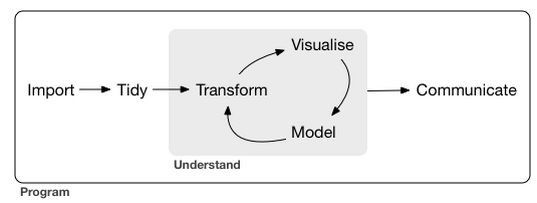
对于非开发者而言,所以大部分的数据分析师的大部分时间都是在转化数据。关于数据的转化(或者叫提取摘要)R 也出现了很多针对数据转化的R包:reshape2,tidyverse,magrittr,等等。其用途就是从某个矩阵(数据框或者列表)中按照某种规则(函数)来构造一个新的矩阵,通常的办法是遍历行或者列,既然是遍历当然会用到for或者while循环了。在Andrew Lim关于R和Python的对比回答中,R是一种面向数组(array-oriented)的语法,它更像数学,方便科学家将数学公式转化为R代码。而Python是一种通用编程语言,更工程化。在使用R时,要尽量用array的方式思考,避免for循环(运行效率也是一方面考虑)。不用循环怎么实现迭代呢?这就需要用到apply函数族。它不是一个函数,而是一族功能类似的函数。
网上已经有大量的关于apply家族的帖子,写的都很好。实话实说,我不打算做的比他们还好。只是为了让自己走进这个家族,了解它们,为了以后更好地调遣它们。也许你会说现在有更好的迭代工具purrr包,语法要比apply好懂速度也不差,是的你说的一点不差,但是那是另一篇文章的事了。apply函数簇提供一种计算框架,我们把这个框架记住了,编写相应的函数放进去可以循环地实现我们的目的。编写处理函数,也就是解决问题的核心应该是我们应该关心的,而不是如何来执行这个函数,这个功能交给apply家族(当然还有一些其他的函数)。
apply函数族是R语言中数据处理的一组核心函数,通过使用apply函数,我们可以实现对数据的循环、分组、过滤、类型控制等操作。

对于每一个函数,我们需要知道的是他的:
- 功能是什么
- 输入是什么
- 输出是什么
apply
apply函数是最常用的代替for循环的函数。apply函数可以对矩阵、数据框、数组(二维、多维),按行或列进行循环计算,对子元素进行迭代,并把子元素以参数传递的形式给自定义的FUN函数中,并以返回计算结果。
Description
Returns a vector or array or list of values obtained by applying a function to margins of an array or matrix.
Usage
apply(X, MARGIN, FUN, ...)
Arguments
X an array, including a matrix.
MARGIN # 按行计算或按按列计算,1表示按行,2表示按列 .记忆:行列行列行列,先行后列。
FUN the function to be applied: see ‘Details’. In the case of functions like +, %*%, etc., the function name must be backquoted or quoted.
... optional arguments to FUN.
> ## Compute row and column sums for a matrix:
> x <- cbind(x1 = 3, x2 = c(4:1, 2:5))
> dimnames(x)[[1]] <- letters[1:8]
> head(x)
x1 x2
a 3 4
b 3 3
c 3 2
d 3 1
e 3 2
f 3 3
> apply(x, 2, mean, trim = .2)
x1 x2
3 3
> col.sums <- apply(x, 2, sum)
> row.sums <- apply(x, 1, sum)
> (stopifnot( apply(x, 2, is.vector)))
NULL
> rbind(cbind(x, Rtot = row.sums), Ctot = c(col.sums, sum(col.sums)))
x1 x2 Rtot
a 3 4 7
b 3 3 6
c 3 2 5
d 3 1 4
e 3 2 5
f 3 3 6
g 3 4 7
h 3 5 8
Ctot 24 24 48
> ## Sort the columns of a matrix
> apply(x, 2, sort)
x1 x2
[1,] 3 1
[2,] 3 2
[3,] 3 2
[4,] 3 3
[5,] 3 3
[6,] 3 4
[7,] 3 4
[8,] 3 5
> ## keeping named dimnames
> names(dimnames(x)) <- c("row", "col")
> x3 <- array(x, dim = c(dim(x),3),
+ dimnames = c(dimnames(x), list(C = paste0("cop.",1:3))))
> identical(x, apply( x, 2, identity))
[1] TRUE
> identical(x3, apply(x3, 2:3, identity))
[1] TRUE
> ##- function with extra args:
> cave <- function(x, c1, c2) c(mean(x[c1]), mean(x[c2]))
> apply(x, 1, cave, c1 = "x1", c2 = c("x1","x2"))
row
a b c d e f g h
[1,] 3.0 3 3.0 3 3.0 3 3.0 3
[2,] 3.5 3 2.5 2 2.5 3 3.5 4
> ma <- matrix(c(1:4, 1, 6:8), nrow = 2)
> ma
[,1] [,2] [,3] [,4]
[1,] 1 3 1 7
[2,] 2 4 6 8
> apply(ma, 1, table) #--> a list of length 2
[[1]]
1 3 7
2 1 1
[[2]]
2 4 6 8
1 1 1 1
> apply(ma, 1, stats::quantile) # 5 x n matrix with rownames
[,1] [,2]
0% 1 2.0
25% 1 3.5
50% 2 5.0
75% 4 6.5
100% 7 8.0
> stopifnot(dim(ma) == dim(apply(ma, 1:2, sum)))
> ## Example with different lengths for each call
> z <- array(1:24, dim = 2:4)
> zseq <- apply(z, 1:2, function(x) seq_len(max(x)))
> zseq ## a 2 x 3 matrix
[,1] [,2] [,3]
[1,] Integer,19 Integer,21 Integer,23
[2,] Integer,20 Integer,22 Integer,24
> typeof(zseq) ## list
[1] "list"
> dim(zseq) ## 2 3
[1] 2 3
> zseq[1,]
[[1]]
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
[[2]]
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
[[3]]
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
值得注意的是,apply函数时可以针对数组进行计算你的,就是说数组未必是2维的!!比如我们对z可以进行这样的操作:
> z
, , 1
[,1] [,2] [,3]
[1,] 1 3 5
[2,] 2 4 6
, , 2
[,1] [,2] [,3]
[1,] 7 9 11
[2,] 8 10 12
, , 3
[,1] [,2] [,3]
[1,] 13 15 17
[2,] 14 16 18
, , 4
[,1] [,2] [,3]
[1,] 19 21 23
[2,] 20 22 24
> apply(z, 1, function(x) max(x))
[1] 23 24
> apply(z, 2, function(x) max(x))
[1] 20 22 24
> apply(z, 3, function(x) max(x))
[1] 6 12 18 24
> apply(z, 2:3, function(x) max(x))
[,1] [,2] [,3] [,4]
[1,] 2 8 14 20
[2,] 4 10 16 22
[3,] 6 12 18 24
> apply(z, 1:3, function(x) max(x))
, , 1
[,1] [,2] [,3]
[1,] 1 3 5
[2,] 2 4 6
, , 2
[,1] [,2] [,3]
[1,] 7 9 11
[2,] 8 10 12
, , 3
[,1] [,2] [,3]
[1,] 13 15 17
[2,] 14 16 18
, , 4
[,1] [,2] [,3]
[1,] 19 21 23
[2,] 20 22 24
> apply(z, 1:2, function(x) max(x))
[,1] [,2] [,3]
[1,] 19 21 23
[2,] 20 22 24
对一个矩阵的行列进行过滤
ma <- matrix(c(rnorm(100), 1, 6:8), nrow = 10)
ma
dat<-ma
table(apply(dat,2,function(x) sum(x>0.5) )>2)
table(apply(dat,1,function(x) sum(x>0.5) )>3)
dat=dat[apply(dat,1,function(x) sum(x>.5) )>3,
apply(dat,2,function(x) sum(x>.5) )>2]
> dim(dat)
[1] 6 8
> dim(ma)
[1] 10 11
按行列求平均值和标准差
> sumfn<- function(x)c(n=sum(!is.na(x)),mean=mean(x),sd=sd(x))
> x=apply(ma, 2, sumfn)
> t(x)
n mean sd
[1,] 10 -0.81989256 1.0101641
[2,] 10 -0.02861924 0.6222009
[3,] 10 0.92534442 0.9118387
[4,] 10 -0.22463996 0.7247355
[5,] 10 0.20232703 0.8488190
[6,] 10 -0.22969541 1.4147416
[7,] 10 -0.22737983 1.3954562
[8,] 10 -0.22072175 1.2582542
[9,] 10 0.84735558 0.7582425
[10,] 10 0.21163342 0.9653582
[11,] 10 1.95826460 3.6227635
lapply
lapply函数是一个最基础循环操作函数之一,用来对list、data.frame数据集进行循环,并返回和X长度同样的list结构作为结果集,通过lapply的开头的第一个字母’l’就可以判断返回结果集的类型。
Usage
lapply(X, FUN, ...)
Arguments
X a vector (atomic or list) or an `[expression](http://127.0.0.1:22572/help/library/base/help/expression)` object. Other objects (including classed objects) will be coerced by`base::[as.list](http://127.0.0.1:22572/help/library/base/help/as.list)`.
FUN the function to be applied to each element of `X`: see ‘Details’. In the case of functions like `+`, `%*%`, the function name must be backquoted or quoted.
# Examples
require(stats); require(graphics)
x <- list(a = 1:10, beta = exp(-3:3), logic = c(TRUE,FALSE,FALSE,TRUE))
x
# compute the list mean for each list element
lapply(x, mean)
$`a`
[1] 5.5
$beta
[1] 4.535125
$logic
[1] 0.5
> sapply(x, mean)
a beta logic
5.500000 4.535125 0.500000
> # median and quartiles for each list element
> lapply(x, quantile, probs = 1:3/4)
$`a`
25% 50% 75%
3.25 5.50 7.75
$beta
25% 50% 75%
0.2516074 1.0000000 5.0536690
$logic
25% 50% 75%
0.0 0.5 1.0
> sapply(x, quantile)
a beta logic
0% 1.00 0.04978707 0.0
25% 3.25 0.25160736 0.0
50% 5.50 1.00000000 0.5
75% 7.75 5.05366896 1.0
100% 10.00 20.08553692 1.0
lapply就可以很方便地把list数据集进行循环操作,还可以用data.frame数据集按列进行循环,但如果传入的数据集是一个向量或矩阵对象,那么直接使用lapply就不能达到想要的效果了。
> x <- cbind(x1=3, x2=c(2:1,4:5))
> x; class(x)
x1 x2
[1,] 3 2
[2,] 3 1
[3,] 3 4
[4,] 3 5
[1] "matrix"
> lapply(x, quantile, probs = 1:3/4)
[[1]]
25% 50% 75%
3 3 3
[[2]]
25% 50% 75%
3 3 3
[[3]]
25% 50% 75%
3 3 3
[[4]]
25% 50% 75%
3 3 3
[[5]]
25% 50% 75%
2 2 2
[[6]]
25% 50% 75%
1 1 1
[[7]]
25% 50% 75%
4 4 4
[[8]]
25% 50% 75%
5 5 5
lapply会分别循环矩阵中的每个值,而不是按行或按列进行分组计算。
sapply
sapply函数是一个简化版的lapply,sapply增加了2个参数simplify和USE.NAMES,主要就是让输出看起来更友好,返回值为向量,而不是list对象。
在上面lapply中已经演示过了,如果saplly中simplify=FALSE和USE.NAMES=FALSE,那么完全sapply函数就等于lapply函数了。
vapply
vapply类似于sapply,提供了FUN.VALUE参数,用来控制返回值的行名,这样可以让程序更健壮。可以对数据框的数据进行累计求和,并对每一行设置行名row.names,就比spply多一个命名的功能。
> i39 <- sapply(3:9, seq) # list of vectors
> i39
[[1]]
[1] 1 2 3
[[2]]
[1] 1 2 3 4
[[3]]
[1] 1 2 3 4 5
[[4]]
[1] 1 2 3 4 5 6
[[5]]
[1] 1 2 3 4 5 6 7
[[6]]
[1] 1 2 3 4 5 6 7 8
[[7]]
[1] 1 2 3 4 5 6 7 8 9
> sapply(i39, fivenum)
[,1] [,2] [,3] [,4] [,5] [,6] [,7]
[1,] 1.0 1.0 1 1.0 1.0 1.0 1
[2,] 1.5 1.5 2 2.0 2.5 2.5 3
[3,] 2.0 2.5 3 3.5 4.0 4.5 5
[4,] 2.5 3.5 4 5.0 5.5 6.5 7
[5,] 3.0 4.0 5 6.0 7.0 8.0 9
> vapply(i39, fivenum,
+ c(Min. = 0, "1st Qu." = 0, Median = 0, "3rd Qu." = 0, Max. = 0))
[,1] [,2] [,3] [,4] [,5] [,6] [,7]
Min. 1.0 1.0 1 1.0 1.0 1.0 1
1st Qu. 1.5 1.5 2 2.0 2.5 2.5 3
Median 2.0 2.5 3 3.5 4.0 4.5 5
3rd Qu. 2.5 3.5 4 5.0 5.5 6.5 7
Max. 3.0 4.0 5 6.0 7.0 8.0 9
> ## sapply(*, "array") -- artificial example
> (v <- structure(10*(5:8), names = LETTERS[1:4]))
A B C D
50 60 70 80
> f2 <- function(x, y) outer(rep(x, length.out = 3), y)
> (a2 <- sapply(v, f2, y = 2*(1:5), simplify = "array"))
, , A
[,1] [,2] [,3] [,4] [,5]
[1,] 100 200 300 400 500
[2,] 100 200 300 400 500
[3,] 100 200 300 400 500
, , B
[,1] [,2] [,3] [,4] [,5]
[1,] 120 240 360 480 600
[2,] 120 240 360 480 600
[3,] 120 240 360 480 600
, , C
[,1] [,2] [,3] [,4] [,5]
[1,] 140 280 420 560 700
[2,] 140 280 420 560 700
[3,] 140 280 420 560 700
, , D
[,1] [,2] [,3] [,4] [,5]
[1,] 160 320 480 640 800
[2,] 160 320 480 640 800
[3,] 160 320 480 640 800
> a.2 <- vapply(v, f2, outer(1:3, 1:5), y = 2*(1:5))
> a.2
, , A
[,1] [,2] [,3] [,4] [,5]
[1,] 100 200 300 400 500
[2,] 100 200 300 400 500
[3,] 100 200 300 400 500
, , B
[,1] [,2] [,3] [,4] [,5]
[1,] 120 240 360 480 600
[2,] 120 240 360 480 600
[3,] 120 240 360 480 600
, , C
[,1] [,2] [,3] [,4] [,5]
[1,] 140 280 420 560 700
[2,] 140 280 420 560 700
[3,] 140 280 420 560 700
, , D
[,1] [,2] [,3] [,4] [,5]
[1,] 160 320 480 640 800
[2,] 160 320 480 640 800
[3,] 160 320 480 640 800
> stopifnot(dim(a2) == c(3,5,4), all.equal(a2, a.2),
+ identical(dimnames(a2), list(NULL,NULL,LETTERS[1:4])))
mapply
mapply也是sapply的变形函数,类似多变量的sapply,但是参数定义有些变化。第一参数为自定义的FUN函数,第二个参数’…’可以接收多个数据,作为FUN函数的参数调用。
Usage
mapply(FUN, ..., MoreArgs = NULL, SIMPLIFY = TRUE,
USE.NAMES = TRUE)
MoreArgs: 参数列表
SIMPLIFY: 是否数组化,当值array时,输出结果按数组进行分组
USE.NAMES: 如果X为字符串,TRUE设置字符串为数据名,FALSE不设置
比如,比较3个向量大小,按索引顺序取较大的值。
> mapply(rep, 1:4, 4:1)
[[1]]
[1] 1 1 1 1
[[2]]
[1] 2 2 2
[[3]]
[1] 3 3
[[4]]
[1] 4
> mapply(rep, times = 1:4, x = 4:1)
[[1]]
[1] 4
[[2]]
[1] 3 3
[[3]]
[1] 2 2 2
[[4]]
[1] 1 1 1 1
> mapply(rep, times = 1:4, MoreArgs = list(x = 42))
[[1]]
[1] 42
[[2]]
[1] 42 42
[[3]]
[1] 42 42 42
[[4]]
[1] 42 42 42 42
> mapply(function(x, y) seq_len(x) + y,
+ c(a = 1, b = 2, c = 3), # names from first
+ c(A = 10, B = 0, C = -10))
$`a`
[1] 11
$b
[1] 1 2
$c
[1] -9 -8 -7
> word <- function(C, k) paste(rep.int(C, k), collapse = "")
> word
function(C, k) paste(rep.int(C, k), collapse = "")
> utils::str(mapply(word, LETTERS[1:6], 6:1, SIMPLIFY = FALSE))
List of 6
$ A: chr "AAAAAA"
$ B: chr "BBBBB"
$ C: chr "CCCC"
$ D: chr "DDD"
$ E: chr "EE"
$ F: chr "F"
tapply
tapply用于分组的循环计算,通过INDEX参数可以把数据集X进行分组,相当于group by的操作。INDEX 一个或多个因子的列表,每个因子的长度都与x相同。
Usage
tapply(X, INDEX, FUN = NULL, ..., default = NA, simplify = TRUE)
> require(stats)
> groups <- as.factor(rbinom(32, n = 5, prob = 0.4))
> groups
[1] 14 11 12 9 9
Levels: 9 11 12 14
> tapply(groups, groups, length) #- is almost the same as
9 11 12 14
2 1 1 1
> table(groups)
groups
9 11 12 14
2 1 1 1
> ## contingency table from data.frame : array with named dimnames
> head(warpbreaks)
breaks wool tension
1 26 A L
2 30 A L
3 54 A L
4 25 A L
5 70 A L
6 52 A L
> tapply(warpbreaks$breaks, warpbreaks[,-1], sum)
tension
wool L M H
A 401 216 221
B 254 259 169
> tapply(warpbreaks$breaks, warpbreaks[, 3, drop = FALSE], sum)
tension
L M H
655 475 390
> n <- 17; fac <- factor(rep_len(1:3, n), levels = 1:5)
> fac
[1] 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2
Levels: 1 2 3 4 5
> table(fac)
fac
1 2 3 4 5
6 6 5 0 0
> tapply(1:n, fac, sum)
1 2 3 4 5
51 57 45 NA NA
> tapply(1:n, fac, sum, default = 0) # maybe more desirable
1 2 3 4 5
51 57 45 0 0
> tapply(1:n, fac, sum, simplify = FALSE)
$`1`
[1] 51
$`2`
[1] 57
$`3`
[1] 45
$`4`
NULL
$`5`
NULL
> tapply(1:n, fac, range)
$`1`
[1] 1 16
$`2`
[1] 2 17
$`3`
[1] 3 15
$`4`
NULL
$`5`
NULL
> tapply(1:n, fac, quantile)
$`1`
0% 25% 50% 75% 100%
1.00 4.75 8.50 12.25 16.00
$`2`
0% 25% 50% 75% 100%
2.00 5.75 9.50 13.25 17.00
$`3`
0% 25% 50% 75% 100%
3 6 9 12 15
$`4`
NULL
$`5`
NULL
> tapply(1:n, fac, length) ## NA's
1 2 3 4 5
6 6 5 NA NA
> tapply(1:n, fac, length, default = 0) # == table(fac)
1 2 3 4 5
6 6 5 0 0
> ## example of ... argument: find quarterly means
> tapply(presidents, cycle(presidents), mean, na.rm = TRUE)
1 2 3 4
58.44828 56.43333 57.22222 53.07143
> ind <- list(c(1, 2, 2), c("A", "A", "B"))
> ind
[[1]]
[1] 1 2 2
[[2]]
[1] "A" "A" "B"
> table(ind)
ind.2
ind.1 A B
1 1 0
2 1 1
> tapply(1:3, ind) #-> the split vector
[1] 1 2 4
> tapply(1:3, ind, sum)
A B
1 1 NA
2 2 3
> ## Some assertions (not held by all patch propsals):
> nq <- names(quantile(1:5))
> stopifnot(
+ identical(tapply(1:3, ind), c(1L, 2L, 4L)),
+ identical(tapply(1:3, ind, sum),
+ matrix(c(1L, 2L, NA, 3L), 2, dimnames = list(c("1", "2"), c("A", "B")))),
+ identical(tapply(1:n, fac, quantile)[-1],
+ array(list(`2` = structure(c(2, 5.75, 9.5, 13.25, 17), .Names = nq),
+ `3` = structure(c(3, 6, 9, 12, 15), .Names = nq),
+ `4` = NULL, `5` = NULL), dim=4, dimnames=list(as.character(2:5))))
+ )
>
rapply
rapply是一个递归版本的lapply,它只处理list类型数据,对list的每个元素进行递归遍历,如果list包括子元素则继续遍历。
### Description
`rapply` is a recursive version of `[lapply](http://127.0.0.1:22572/help/library/base/help/lapply)`.
### Usage
rapply(object, f, classes = "ANY", deflt = NULL,
how = c("unlist", "replace", "list"), ...)
Arguments
classes : 匹配类型, ANY为所有类型
deflt: 非匹配类型的默认值
how: 3种操作方式,当为replace时,则用调用f后的结果替换原list中原来的元素;当为list时,新建一个list,类型匹配调用f函数,不匹配赋值为deflt;当为unlist时,会执行一次unlist(recursive = TRUE)的操作
> X <- list(list(a = pi, b = list(c = 1:1)), d = "a test")
> x
x1 x2
[1,] 3 2
[2,] 3 1
[3,] 3 4
[4,] 3 5
> rapply(X, function(x) x, how = "replace")
[[1]]
[[1]]$`a`
[1] 3.141593
[[1]]$b
[[1]]$b$`c`
[1] 1
$d
[1] "a test"
> rapply(X, sqrt, classes = "numeric", how = "replace")
[[1]]
[[1]]$`a`
[1] 1.772454
[[1]]$b
[[1]]$b$`c`
[1] 1
$d
[1] "a test"
> rapply(X, nchar, classes = "character",
+ deflt = as.integer(NA), how = "list")
[[1]]
[[1]]$`a`
[1] NA
[[1]]$b
[[1]]$b$`c`
[1] NA
$d
[1] 6
> rapply(X, nchar, classes = "character",
+ deflt = as.integer(NA), how = "unlist")
a b.c d
NA NA 6
> rapply(X, nchar, classes = "character", how = "unlist")
d
6
> rapply(X, log, classes = "numeric", how = "replace", base = 2)
[[1]]
[[1]]$`a`
[1] 1.651496
[[1]]$b
[[1]]$b$`c`
[1] 1
$d
[1] "a test"
eapply
对一个环境空间中的所有变量进行遍历。如果我们有好的习惯,把自定义的变量都按一定的规则存储到自定义的环境空间中,那么这个函数将会让你的操作变得非常方便。 这个用的比较少,之前我们要知道,什么是environment 以及作用。
Usage
eapply(env, FUN, ..., all.names = FALSE, USE.NAMES = TRUE)
> env <- new.env(hash = FALSE) # so the order is fixed
> env$a <- 1:10
> env$beta <- exp(-3:3)
> env$logic <- c(TRUE, FALSE, FALSE, TRUE)
> env
> str(env)
> class(env)
[1] "environment"
> # what have we there?
> utils::ls.str(env)
a : int [1:10] 1 2 3 4 5 6 7 8 9 10
beta : num [1:7] 0.0498 0.1353 0.3679 1 2.7183 ...
logic : logi [1:4] TRUE FALSE FALSE TRUE
> # compute the mean for each list element
> eapply(env, mean)
$`logic`
[1] 0.5
$beta
[1] 4.535125
$a
[1] 5.5
> unlist(eapply(env, mean, USE.NAMES = FALSE))
[1] 0.500000 4.535125 5.500000
> # median and quartiles for each element (making use of "..." passing):
> eapply(env, quantile, probs = 1:3/4)
$`logic`
25% 50% 75%
0.0 0.5 1.0
$beta
25% 50% 75%
0.2516074 1.0000000 5.0536690
$a
25% 50% 75%
3.25 5.50 7.75
> eapply(env, quantile)
$`logic`
0% 25% 50% 75% 100%
0.0 0.0 0.5 1.0 1.0
$beta
0% 25% 50% 75% 100%
0.04978707 0.25160736 1.00000000 5.05366896 20.08553692
$a
0% 25% 50% 75% 100%
1.00 3.25 5.50 7.75 10.00
R语言apply函数族笔记
掌握R语言中的apply函数族