python工具包: pandas
引言
Pandas具有超强的数据处理能力,似乎是目前处理日常csv和Excel文件中最好用的工具包。结合Matplotlib工具包,基本可以满足上述两种文件的处理和显示工作。
数据结构
我们介绍Pandas中的两种主要数据结构:Series与DataFrame,其示意图如下所示:

从上图可以看出,Series由一个一维数组(values)和与之对应的索引(index)组成。这个结构看起来和python中的字典(dict)类似,但两者有很多不同:
- 字典是无序的数据结构,Series相当于定长有序的字典;
- 字典中key和value是绑定的,Series中values和index是独立的;
- 字典中key值不可变,Series中index是可变的
Series的定义可以从官网查看,下面以一个简单的例子介绍Series的初始化:
In [23]: import pandas as pd
In [24]: data = pd.Series([1,2,3,4], index=['a', 'b', 'c', 'd'])
In [25]: data
Out[25]:
a 1
b 2
c 3
d 4
dtype: int64
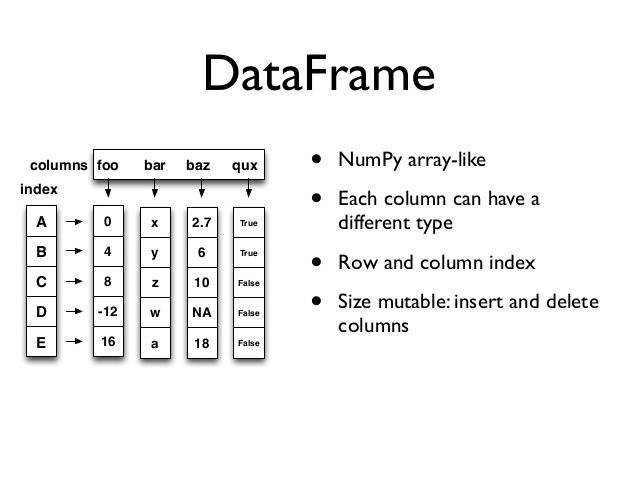
从上图可以看出,DataFrame有点像打开Excel文件的样子:一个二维数据加上行(index)和列(columns)标签。还可以将DataFrame看作是同一index的不同Series集合。有趣的是,DataFrame中每一列的数据类型还可以不同。
我们继续从官网学习DataFrame的定义以及初始化:
# 这里直接copy了官网上的一种初始化方式感受下
In [27]: import numpy as np
In [28]: df2 = pd.DataFrame(np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]),^M
...: ... columns=['a', 'b', 'c'])
In [29]: df2
Out[29]:
a b c
0 1 2 3
1 4 5 6
2 7 8 9
常用属性及方法
Series
在我的应用中,基本接触不到Series,因此这里就不介绍了
DataFrame
| 属性 | 描述 |
|---|
| 函数 | 描述 |
|---|---|
| df.to_csv(‘text.csv’) | 保存dataframe到csv文件中 |
| df = pd.read_csv(‘text.csv’) | 读csv文件到dataframe中 |
#参考资料
数据分析三剑客之pandas
pandas用法总结