- 机器学习与深度学习间关系与区别
ℒℴѵℯ心·动ꦿ໊ོ꫞
人工智能学习深度学习python
一、机器学习概述定义机器学习(MachineLearning,ML)是一种通过数据驱动的方法,利用统计学和计算算法来训练模型,使计算机能够从数据中学习并自动进行预测或决策。机器学习通过分析大量数据样本,识别其中的模式和规律,从而对新的数据进行判断。其核心在于通过训练过程,让模型不断优化和提升其预测准确性。主要类型1.监督学习(SupervisedLearning)监督学习是指在训练数据集中包含输入
- 网易严选官方旗舰店,优质商品,卓越服务
高省_飞智666600
网易严选官方旗舰店是网易旗下的一家电商平台,以提供优质商品和卓越服务而闻名。作为一名SEO优化师,我将为您详细介绍网易严选官方旗舰店,并重点强调其特点和优势。大家好!我是高省APP最大团队&联合创始人飞智导师。相较于其他返利app,高省APP的佣金更高,模式更好,最重要的是,终端用户不会流失!高省APP佣金更高,模式更好,终端用户不流失。【高省】是一个自用省钱佣金高,分享推广赚钱多的平台,百度有几
- 基于社交网络算法优化的二维最大熵图像分割
智能算法研学社(Jack旭)
智能优化算法应用图像分割算法php开发语言
智能优化算法应用:基于社交网络优化的二维最大熵图像阈值分割-附代码文章目录智能优化算法应用:基于社交网络优化的二维最大熵图像阈值分割-附代码1.前言2.二维最大熵阈值分割原理3.基于社交网络优化的多阈值分割4.算法结果:5.参考文献:6.Matlab代码摘要:本文介绍基于最大熵的图像分割,并且应用社交网络算法进行阈值寻优。1.前言阅读此文章前,请阅读《图像分割:直方图区域划分及信息统计介绍》htt
- nosql数据库技术与应用知识点
皆过客,揽星河
NoSQLnosql数据库大数据数据分析数据结构非关系型数据库
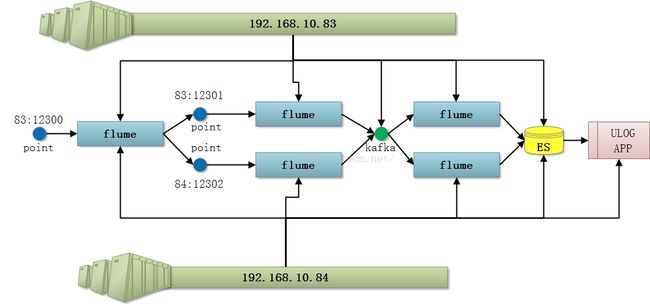
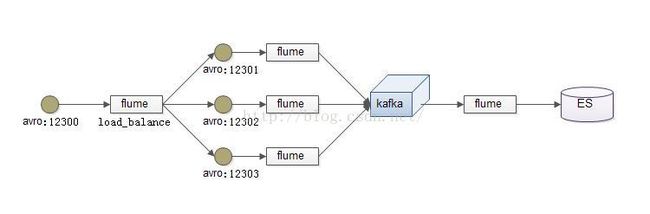
Nosql知识回顾大数据处理流程数据采集(flume、爬虫、传感器)数据存储(本门课程NoSQL所处的阶段)Hdfs、MongoDB、HBase等数据清洗(入仓)Hive等数据处理、分析(Spark、Flink等)数据可视化数据挖掘、机器学习应用(Python、SparkMLlib等)大数据时代存储的挑战(三高)高并发(同一时间很多人访问)高扩展(要求随时根据需求扩展存储)高效率(要求读写速度快)
- 关于Mysql 中 Row size too large (> 8126) 错误的解决和理解
秋刀prince
mysqlmysql数据库
提示:啰嗦一嘴,数据库的任何操作和验证前,一定要记得先备份!!!不会有错;文章目录问题发现一、问题导致的可能原因1、页大小2、行格式2.1compact格式2.2Redundant格式2.3Dynamic格式2.4Compressed格式3、BLOB和TEXT列二、解决办法1、修改页大小(不推荐)2、修改行格式3、修改数据类型为BLOB和TEXT列4、其他优化方式(可以参考使用)4.1合理设置数据
- 系统架构设计师 需求分析篇二
AmHardy
软件架构设计师系统架构需求分析面向对象分析分析模型UML和SysML
面向对象分析方法1.用例模型构建用例模型一般需要经历4个阶段:识别参与者:识别与系统交互的所有事物。合并需求获得用例:将需求分配给予其相关的参与者。细化用例描述:详细描述每个用例的功能。调整用例模型:优化用例之间的关系和结构,前三个阶段是必需的。2.用例图的三元素参与者:使用系统的用户或其他外部系统和设备。用例:系统所提供的服务。通信关联:参与者和用例之间的关系,或用例与用例之间的关系。3.识别参
- MongoDB知识概括
GeorgeLin98
持久层mongodb
MongoDB知识概括MongoDB相关概念单机部署基本常用命令索引-IndexSpirngDataMongoDB集成副本集分片集群安全认证MongoDB相关概念业务应用场景:传统的关系型数据库(如MySQL),在数据操作的“三高”需求以及应对Web2.0的网站需求面前,显得力不从心。解释:“三高”需求:①Highperformance-对数据库高并发读写的需求。②HugeStorage-对海量数
- matlab mle 优化,MLE+: Matlab Toolbox for Integrated Modeling, Control and Optimization for Buildings...
Simon Zhong
matlabmle优化
摘要:FollowingunilateralopticnervesectioninadultPVGhoodedrat,theaxonguidancecueephrin-A2isup-regulatedincaudalbutnotrostralsuperiorcolliculus(SC)andtheEphA5receptorisdown-regulatedinaxotomisedretinalgan
- Android应用性能优化
轻口味
Android
Android手机由于其本身的后台机制和硬件特点,性能上一直被诟病,所以软件开发者对软件本身的性能优化就显得尤为重要;本文将对Android开发过程中性能优化的各个方面做一个回顾与总结。Cache优化ListView缓存:ListView中有一个回收器,Item滑出界面的时候View会回收到这里,需要显示新的Item的时候,就尽量重用回收器里面的View;每次在getView函数中inflate新
- 《 C++ 修炼全景指南:九 》打破编程瓶颈!掌握二叉搜索树的高效实现与技巧
Lenyiin
C++修炼全景指南技术指南c++算法stl
摘要本文详细探讨了二叉搜索树(BinarySearchTree,BST)的核心概念和技术细节,包括插入、查找、删除、遍历等基本操作,并结合实际代码演示了如何实现这些功能。文章深入分析了二叉搜索树的性能优势及其时间复杂度,同时介绍了前驱、后继的查找方法等高级功能。通过自定义实现的二叉搜索树类,读者能够掌握其实际应用,此外,文章还建议进一步扩展为平衡树(如AVL树、红黑树)以优化极端情况下的性能退化。
- 深入浅出 -- 系统架构之负载均衡Nginx的性能优化
xiaoli8748_软件开发
系统架构系统架构负载均衡nginx
一、Nginx性能优化到这里文章的篇幅较长了,最后再来聊一下关于Nginx的性能优化,主要就简单说说收益最高的几个优化项,在这块就不再展开叙述了,毕竟影响性能都有多方面原因导致的,比如网络、服务器硬件、操作系统、后端服务、程序自身、数据库服务等,对于性能调优比较感兴趣的可以参考之前《JVM性能调优》中的调优思想。优化一:打开长连接配置通常Nginx作为代理服务,负责分发客户端的请求,那么建议开启H
- 粒子群优化 (PSO) 在三维正弦波函数中的应用
subject625Ruben
机器学习人工智能matlab算法
在这篇博客中,我们将展示如何使用粒子群优化(PSO)算法求解三维正弦波函数,并通过增加正弦波扰动,使优化过程更加复杂和有趣。本文将介绍目标函数的定义、PSO参数设置以及算法执行的详细过程,并展示搜索空间中的动态过程和收敛曲线。1.目标函数定义我们使用的目标函数是一个三维正弦波函数,定义如下:objectiveFunc=@(x)sin(sqrt(x(1).^2+x(2).^2))+0.5*sin(5
- 补充元象二面
Redstone Monstrosity
前端面试
1.请尽可能详细地说明,防抖和节流的区别,应用场景?你的回答中不要写出示例代码。防抖(Debounce)和节流(Throttle)是两种常用的前端性能优化技术,它们的主要区别在于如何处理高频事件的触发。以下是防抖和节流的区别和应用场景的详细说明:防抖和节流的定义防抖:在一段时间内,多次执行变为只执行最后一次。防抖的原理是,当事件被触发后,设置一个延迟定时器。如果在这个延迟时间内事件再次被触发,则重
- 自动写论文的网站推荐这5款实用类工具
小猪包333
写论文人工智能深度学习计算机视觉AI写作
在当今学术研究和写作领域,AI论文写作工具的出现极大地提高了写作效率和质量。这些工具不仅能够帮助研究人员快速生成论文草稿,还能进行内容优化、查重和排版等操作。以下是五款实用类工具推荐,特别是千笔-AIPassPaper。1.千笔-AIPassPaper千笔-AIPassPaper是一款功能强大且全面的AI论文写作助手,用户只需输入基本的研究需求和关键词,便能迅速生成一篇完整的论文。该工具利用先进的
- 推荐3家毕业AI论文可五分钟一键生成!文末附免费教程!
小猪包333
写论文人工智能AI写作深度学习计算机视觉
在当前的学术研究和写作领域,AI论文生成器已经成为许多研究人员和学生的重要工具。这些工具不仅能够帮助用户快速生成高质量的论文内容,还能进行内容优化、查重和排版等操作。以下是三款值得推荐的AI论文生成器:千笔-AIPassPaper、懒人论文以及AIPaperPass。千笔-AIPassPaper千笔-AIPassPaper是一款基于深度学习和自然语言处理技术的AI写作助手,旨在帮助用户快速生成高质
- AI论文写作推荐哪个好?分享5款AI论文写作带数据图表网站
小猪包333
写论文人工智能深度学习计算机视觉
在当今学术研究和写作领域,AI论文写作工具的出现极大地提高了写作效率和质量。这些工具不仅能够帮助研究人员快速生成论文草稿,还能进行内容优化、查重和排版等操作。以下是五款推荐的AI论文写作工具,包括千笔-AIPassPaper。千笔-AIPassPaper千笔-AIPassPaper是一款功能强大的AI论文写作助手,旨在帮助用户快速生成高质量的论文内容。AI论文,免费大纲,10分钟3万字https:
- MyBatis 详解
阿贾克斯的黎明
javamybatis
目录目录一、MyBatis是什么二、为什么使用MyBatis(一)灵活性高(二)性能优化(三)易于维护三、怎么用MyBatis(一)添加依赖(二)配置MyBatis(三)创建实体类和接口(四)使用MyBatis一、MyBatis是什么MyBatis是一个优秀的持久层框架,它支持自定义SQL、存储过程以及高级映射。MyBatis免除了几乎所有的JDBC代码以及设置参数和获取结果集的工作。它可以通过简
- 华为云分布式缓存服务DCS 8月新特性发布
华为云PaaS服务小智
华为云分布式缓存
分布式缓存服务(DistributedCacheService,简称DCS)是华为云提供的一款兼容Redis的高速内存数据处理引擎,为您提供即开即用、安全可靠、弹性扩容、便捷管理的在线分布式缓存能力,满足用户高并发及数据快速访问的业务诉求。此次为大家带来DCS8月的特性更新内容,一起来看看吧!
- [实践应用] 深度学习之优化器
YuanDaima2048
深度学习工具使用pytorch深度学习人工智能机器学习python优化器
文章总览:YuanDaiMa2048博客文章总览深度学习之优化器1.随机梯度下降(SGD)2.动量优化(Momentum)3.自适应梯度(Adagrad)4.自适应矩估计(Adam)5.RMSprop总结其他介绍在深度学习中,优化器用于更新模型的参数,以最小化损失函数。常见的优化函数有很多种,下面是几种主流的优化器及其特点、原理和PyTorch实现:1.随机梯度下降(SGD)原理:随机梯度下降通过
- [实验室服务器使用]使用VSCode、PyCharm、MobaXterm和CMD连接远程服务器
YuanDaima2048
工具使用服务器vscodepycharmcmd代理模式机器学习实验
文章总览:YuanDaiMa2048博客文章总览实验室服务器使用:使用VSCode、PyCharm、MobaXterm和CMD连接远程服务器在进行实验室工作时,远程连接服务器是常见的需求之一。本篇文章根据个人的一些使用介绍使用不同工具连接服务器的方法,并提供优化功能,使服务器能够使用本机代理的说明。准备服务器账号信息Host(主机):10.XXX.XX.XXXPort(端口):[SSHPort]U
- 效率神器来了:AI工具手把手教你快速提升工作效能
kkai人工智能
人工智能学习媒体aichatgpt
随着科技的进步,AI工具已经成为提升工作效率的关键手段。本文将介绍一些实用的AI工具和方法,帮助你自动化繁琐的重复性任务、优化数据管理、促进团队协作与沟通,并提升决策质量。背景:OOPAI-免费问答学习交流-GPT自动化重复性任务Zapier:Zapier可以自动化多个应用程序之间的工作流程。例如,它能自动将Gmail中的附件保存至GoogleDrive,或在你发布新文章时,自动分享至社交媒体平台
- APQP,ASPICE,敏捷,功能安全,预期安全,这些汽车行业的一堆标准
二大宝贝
安全架构
前言APQP,ASPICE,敏捷,功能安全,预期安全,PMP,PRICE2汽车行业的有这样一堆标准。我是半路出家来到汽车行业做项目经理的,对几个标准的感觉是,看了文档和各种解析之后还是一头雾水,不知道到底说了个啥,别人问我还是一脸懵逼。APQP(TS16949的最重要工具),ASPICE(软件)这些是质量标准,是优化整个公司体系的,但这套体系对项目管理有要求;敏捷,PMP这些是项目管理的标准;项目
- 程序员如何在AI时代保持核心竞争力
nfgo
chatgpt人工智能
程序员如何在AI时代保持核心竞争力随着AIGC(如ChatGPT、MidJourney、Claude等)大语言模型的相继涌现,AI辅助编程工具逐渐普及,程序员的工作方式正在发生深刻的变革。AI不仅能够自动生成代码,还能优化、调试、甚至提出解决方案。这一趋势让许多人担心:AI会不会最终取代部分编程工作?然而,也有人认为AI是提升效率的得力助手。那么,程序员在这个AI崛起的时代该如何应对?是专注某个领
- 广东麻将开发
红匣子实力推荐
在中国,麻将作为一种深受人们喜爱的传统娱乐活动,已经有着数百年的历史。随着互联网和移动设备的普及,麻将游戏也从实体桌面转移到了数字平台,其中广东麻将因其独特的地方特色和玩法而备受青睐。本文将介绍广东麻将的开发过程,包括其设计理念、技术实现以及用户体验优化等方面。一、设计理念:广东麻将开发的核心理念是保留传统麻将的精髓,同时融入现代科技元素,使游戏既具有亲切感又不失趣味性。开发者通常会深入研究广东地
- Redis:缓存击穿
我的程序快快跑啊
缓存redisjava
缓存击穿(热点key):部分key(被高并发访问且缓存重建业务复杂的)失效,无数请求会直接到数据库,造成巨大压力1.互斥锁:可以保证强一致性线程一:未命中之后,获取互斥锁,再查询数据库重建缓存,写入缓存,释放锁线程二:查询未命中,未获得锁(已由线程一获得),等待一会,缓存命中互斥锁实现方式:redis中setnxkeyvalue:改变对应key的value,仅当value不存在时执行,以此来实现互
- 3.1 损失函数和优化:损失函数
做只小考拉
用一个函数把W当做输入,然后看一下得分,定量地估计W的好坏,这个函数被称为“损失函数”。损失函数用于度量W的好坏。有了损失函数的概念后,就可以定量的衡量W到底是好还是坏,要找到一种有效的方法来从W的可行域里,找到W取何值时情况最不坏,,这个过程将会是一个优化过程。损失函数L_i定义:通过函数f给出预测的分数和真实的目标(或者说是标签y),可以定量的描述训练样本预测的好不好,最终的损失函数是在整个数
- metaRTC8.0,一个全新架构的webRTC SDK库
metaRTC
webrtc音视频
概述metaRTC8.0是metaRTC开源以来架构变化最大的一个版本,是metaIPC3.0等高性能的基础。metaRTC8.0是一个全新架构版本,并非在metaRTC7.0版本上简单升级,在QOS/语音对讲/内存占用/视频文件录制读取等方面新增多个模块,在弱网对抗/语音对讲/内存优化等效果上有显著提升。metaRTC8.0在一年多的开发中进行了近200次迭代,metaRTC8.0社区版计划在2
- 如何在电商平台上使用API接口数据优化商品价格
weixin_43841111
api数据挖掘人工智能pythonjava大数据前端爬虫
利用API接口数据来优化电商商品价格是一个涉及数据收集、分析、策略制定以及实时调整价格的过程。这不仅能提高市场竞争力,还能通过精准定价最大化利润。以下是一些关键步骤和策略,用于通过API接口数据优化电商商品价格:1.数据收集竞争对手价格监控:使用API接口(如Scrapy、BeautifulSoup等工具结合Python进行网页数据抓取,或使用专门的API服务如PriceIntelligence、
- 未来软件市场是怎么样的?做开发的生存空间如何?
cesske
软件需求
目录前言一、未来软件市场的发展趋势二、软件开发人员的生存空间前言未来软件市场是怎么样的?做开发的生存空间如何?一、未来软件市场的发展趋势技术趋势:人工智能与机器学习:随着技术的不断成熟,人工智能将在更多领域得到应用,如智能客服、自动驾驶、智能制造等,这将极大地推动软件市场的增长。云计算与大数据:云计算服务将继续普及,大数据技术的应用也将更加广泛。企业将更加依赖云计算和大数据来优化运营、提升效率,并
- 《Mesh 组网和 AC+AP 组网的优缺点》
jiyiwangluokeji
网络工程网络
Mesh组网和AC+AP组网的优缺点。Mesh组网的优点:1.部署灵活:节点之间可以通过无线方式连接,新增节点比较方便,无需事先规划布线。2.自我修复和优化:如果某个节点出现故障,网络可以自动重新路由数据,保证网络的稳定性。3.覆盖范围广:可以通过添加节点轻松扩展覆盖区域。4.设备选型多样:市面上有多种不同品牌和型号的Mesh路由器可供选择。Mesh组网的缺点:1.无线回程可能存在性能瓶颈:如果节
- Spring4.1新特性——综述
jinnianshilongnian
spring 4.1
目录
Spring4.1新特性——综述
Spring4.1新特性——Spring核心部分及其他
Spring4.1新特性——Spring缓存框架增强
Spring4.1新特性——异步调用和事件机制的异常处理
Spring4.1新特性——数据库集成测试脚本初始化
Spring4.1新特性——Spring MVC增强
Spring4.1新特性——页面自动化测试框架Spring MVC T
- Schema与数据类型优化
annan211
数据结构mysql
目前商城的数据库设计真是一塌糊涂,表堆叠让人不忍直视,无脑的架构师,说了也不听。
在数据库设计之初,就应该仔细揣摩可能会有哪些查询,有没有更复杂的查询,而不是仅仅突出
很表面的业务需求,这样做会让你的数据库性能成倍提高,当然,丑陋的架构师是不会这样去考虑问题的。
选择优化的数据类型
1 更小的通常更好
更小的数据类型通常更快,因为他们占用更少的磁盘、内存和cpu缓存,
- 第一节 HTML概要学习
chenke
htmlWebcss
第一节 HTML概要学习
1. 什么是HTML
HTML是英文Hyper Text Mark-up Language(超文本标记语言)的缩写,它规定了自己的语法规则,用来表示比“文本”更丰富的意义,比如图片,表格,链接等。浏览器(IE,FireFox等)软件知道HTML语言的语法,可以用来查看HTML文档。目前互联网上的绝大部分网页都是使用HTML编写的。
打开记事本 输入一下内
- MyEclipse里部分习惯的更改
Array_06
eclipse
继续补充中----------------------
1.更改自己合适快捷键windows-->prefences-->java-->editor-->Content Assist-->
Activation triggers for java的右侧“.”就可以改变常用的快捷键
选中 Text
- 近一个月的面试总结
cugfy
面试
本文是在学习中的总结,欢迎转载但请注明出处:http://blog.csdn.net/pistolove/article/details/46753275
前言
打算换个工作,近一个月面试了不少的公司,下面将一些面试经验和思考分享给大家。另外校招也快要开始了,为在校的学生提供一些经验供参考,希望都能找到满意的工作。
- HTML5一个小迷宫游戏
357029540
html5
通过《HTML5游戏开发》摘抄了一个小迷宫游戏,感觉还不错,可以画画,写字,把摘抄的代码放上来分享下,喜欢的同学可以拿来玩玩!
<html>
<head>
<title>创建运行迷宫</title>
<script type="text/javascript"
- 10步教你上传githib数据
张亚雄
git
官方的教学还有其他博客里教的都是给懂的人说得,对已我们这样对我大菜鸟只能这么来锻炼,下面先不玩什么深奥的,先暂时用着10步干净利索。等玩顺溜了再用其他的方法。
操作过程(查看本目录下有哪些文件NO.1)ls
(跳转到子目录NO.2)cd+空格+目录
(继续NO.3)ls
(匹配到子目录NO.4)cd+ 目录首写字母+tab键+(首写字母“直到你所用文件根就不再按TAB键了”)
(查看文件
- MongoDB常用操作命令大全
adminjun
mongodb操作命令
成功启动MongoDB后,再打开一个命令行窗口输入mongo,就可以进行数据库的一些操作。输入help可以看到基本操作命令,只是MongoDB没有创建数据库的命令,但有类似的命令 如:如果你想创建一个“myTest”的数据库,先运行use myTest命令,之后就做一些操作(如:db.createCollection('user')),这样就可以创建一个名叫“myTest”的数据库。
一
- bat调用jar包并传入多个参数
aijuans
下面的主程序是通过eclipse写的:
1.在Main函数接收bat文件传递的参数(String[] args)
如: String ip =args[0]; String user=args[1]; &nbs
- Java中对类的主动引用和被动引用
ayaoxinchao
java主动引用对类的引用被动引用类初始化
在Java代码中,有些类看上去初始化了,但其实没有。例如定义一定长度某一类型的数组,看上去数组中所有的元素已经被初始化,实际上一个都没有。对于类的初始化,虚拟机规范严格规定了只有对该类进行主动引用时,才会触发。而除此之外的所有引用方式称之为对类的被动引用,不会触发类的初始化。虚拟机规范严格地规定了有且仅有四种情况是对类的主动引用,即必须立即对类进行初始化。四种情况如下:1.遇到ne
- 导出数据库 提示 outfile disabled
BigBird2012
mysql
在windows控制台下,登陆mysql,备份数据库:
mysql>mysqldump -u root -p test test > D:\test.sql
使用命令 mysqldump 格式如下: mysqldump -u root -p *** DBNAME > E:\\test.sql。
注意:执行该命令的时候不要进入mysql的控制台再使用,这样会报
- Javascript 中的 && 和 ||
bijian1013
JavaScript&&||
准备两个对象用于下面的讨论
var alice = {
name: "alice",
toString: function () {
return this.name;
}
}
var smith = {
name: "smith",
- [Zookeeper学习笔记之四]Zookeeper Client Library会话重建
bit1129
zookeeper
为了说明问题,先来看个简单的示例代码:
package com.tom.zookeeper.book;
import com.tom.Host;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.Wat
- 【Scala十一】Scala核心五:case模式匹配
bit1129
scala
package spark.examples.scala.grammars.caseclasses
object CaseClass_Test00 {
def simpleMatch(arg: Any) = arg match {
case v: Int => "This is an Int"
case v: (Int, String)
- 运维的一些面试题
yuxianhua
linux
1、Linux挂载Winodws共享文件夹
mount -t cifs //1.1.1.254/ok /var/tmp/share/ -o username=administrator,password=yourpass
或
mount -t cifs -o username=xxx,password=xxxx //1.1.1.1/a /win
- Java lang包-Boolean
BrokenDreams
boolean
Boolean类是Java中基本类型boolean的包装类。这个类比较简单,直接看源代码吧。
public final class Boolean implements java.io.Serializable,
- 读《研磨设计模式》-代码笔记-命令模式-Command
bylijinnan
java设计模式
声明: 本文只为方便我个人查阅和理解,详细的分析以及源代码请移步 原作者的博客http://chjavach.iteye.com/
import java.util.ArrayList;
import java.util.Collection;
import java.util.List;
/**
* GOF 在《设计模式》一书中阐述命令模式的意图:“将一个请求封装
- matlab下GPU编程笔记
cherishLC
matlab
不多说,直接上代码
gpuDevice % 查看系统中的gpu,,其中的DeviceSupported会给出matlab支持的GPU个数。
g=gpuDevice(1); %会清空 GPU 1中的所有数据,,将GPU1 设为当前GPU
reset(g) %也可以清空GPU中数据。
a=1;
a=gpuArray(a); %将a从CPU移到GPU中
onGP
- SVN安装过程
crabdave
SVN
SVN安装过程
subversion-1.6.12
./configure --prefix=/usr/local/subversion --with-apxs=/usr/local/apache2/bin/apxs --with-apr=/usr/local/apr --with-apr-util=/usr/local/apr --with-openssl=/
- sql 行列转换
daizj
sql行列转换行转列列转行
行转列的思想是通过case when 来实现
列转行的思想是通过union all 来实现
下面具体例子:
假设有张学生成绩表(tb)如下:
Name Subject Result
张三 语文 74
张三 数学 83
张三 物理 93
李四 语文 74
李四 数学 84
李四 物理 94
*/
/*
想变成
姓名 &
- MySQL--主从配置
dcj3sjt126com
mysql
linux下的mysql主从配置: 说明:由于MySQL不同版本之间的(二进制日志)binlog格式可能会不一样,因此最好的搭配组合是Master的MySQL版本和Slave的版本相同或者更低, Master的版本肯定不能高于Slave版本。(版本向下兼容)
mysql1 : 192.168.100.1 //master mysq
- 关于yii 数据库添加新字段之后model类的修改
dcj3sjt126com
Model
rules:
array('新字段','safe','on'=>'search')
1、array('新字段', 'safe')//这个如果是要用户输入的话,要加一下,
2、array('新字段', 'numerical'),//如果是数字的话
3、array('新字段', 'length', 'max'=>100),//如果是文本
1、2、3适当的最少要加一条,新字段才会被
- sublime text3 中文乱码解决
dyy_gusi
Sublime Text
sublime text3中文乱码解决
原因:缺少转换为UTF-8的插件
目的:安装ConvertToUTF8插件包
第一步:安装能自动安装插件的插件,百度“Codecs33”,然后按照步骤可以得到以下一段代码:
import urllib.request,os,hashlib; h = 'eb2297e1a458f27d836c04bb0cbaf282' + 'd0e7a30980927
- 概念了解:CGI,FastCGI,PHP-CGI与PHP-FPM
geeksun
PHP
CGI
CGI全称是“公共网关接口”(Common Gateway Interface),HTTP服务器与你的或其它机器上的程序进行“交谈”的一种工具,其程序须运行在网络服务器上。
CGI可以用任何一种语言编写,只要这种语言具有标准输入、输出和环境变量。如php,perl,tcl等。 FastCGI
FastCGI像是一个常驻(long-live)型的CGI,它可以一直执行着,只要激活后,不
- Git push 报错 "error: failed to push some refs to " 解决
hongtoushizi
git
Git push 报错 "error: failed to push some refs to " .
此问题出现的原因是:由于远程仓库中代码版本与本地不一致冲突导致的。
由于我在第一次git pull --rebase 代码后,准备push的时候,有别人往线上又提交了代码。所以出现此问题。
解决方案:
1: git pull
2:
- 第四章 Lua模块开发
jinnianshilongnian
nginxlua
在实际开发中,不可能把所有代码写到一个大而全的lua文件中,需要进行分模块开发;而且模块化是高性能Lua应用的关键。使用require第一次导入模块后,所有Nginx 进程全局共享模块的数据和代码,每个Worker进程需要时会得到此模块的一个副本(Copy-On-Write),即模块可以认为是每Worker进程共享而不是每Nginx Server共享;另外注意之前我们使用init_by_lua中初
- java.lang.reflect.Proxy
liyonghui160com
1.简介
Proxy 提供用于创建动态代理类和实例的静态方法
(1)动态代理类的属性
代理类是公共的、最终的,而不是抽象的
未指定代理类的非限定名称。但是,以字符串 "$Proxy" 开头的类名空间应该为代理类保留
代理类扩展 java.lang.reflect.Proxy
代理类会按同一顺序准确地实现其创建时指定的接口
- Java中getResourceAsStream的用法
pda158
java
1.Java中的getResourceAsStream有以下几种: 1. Class.getResourceAsStream(String path) : path 不以’/'开头时默认是从此类所在的包下取资源,以’/'开头则是从ClassPath根下获取。其只是通过path构造一个绝对路径,最终还是由ClassLoader获取资源。 2. Class.getClassLoader.get
- spring 包官方下载地址(非maven)
sinnk
spring
SPRING官方网站改版后,建议都是通过 Maven和Gradle下载,对不使用Maven和Gradle开发项目的,下载就非常麻烦,下给出Spring Framework jar官方直接下载路径:
http://repo.springsource.org/libs-release-local/org/springframework/spring/
s
- Oracle学习笔记(7) 开发PLSQL子程序和包
vipbooks
oraclesql编程
哈哈,清明节放假回去了一下,真是太好了,回家的感觉真好啊!现在又开始出差之旅了,又好久没有来了,今天继续Oracle的学习!
这是第七章的学习笔记,学习完第六章的动态SQL之后,开始要学习子程序和包的使用了……,希望大家能多给俺一些支持啊!
编程时使用的工具是PLSQL