基于深度学习的推荐(七):DeepCTR经典模型DeepFM分析及实战
文章目录
- 公众号
- 前言
- 1.低阶特征与高阶特征
- 2.DeepFM结构
- 3.实战
- 3.1 多值离散特征的处理
- 3.2 ROC
- 3.3 DeepFM模型实现
- 参考
公众号
关注公众号:推荐算法工程师,输入"进群",加入交流群,和小伙伴们一起讨论机器学习,深度学习,推荐算法.
前言
推荐算法越来越收到互联网公司和学者的重视。在深度学习大行其是之前,推荐算法一度被认为进入了瓶颈期。在将深度学习应用到推荐领域的初期尝试中,一些不错的CTR预估模型接连问世,DeepFM便是其中的翘楚。DeepFM实现简单,运行高效,在不少知名的互联网公司中都有落地的场景。据笔者了解,面试中最常被问到的DeepCTR模型就是DeepFM模型。
论文链接:https://arxiv.org/pdf/1703.04247.pdf
1.低阶特征与高阶特征
CTR(click through rate)问题实质上是一个二分类问题,其中的重点和难点都在特征这一块。如何获得更好的representation是非常核心的一个问题。
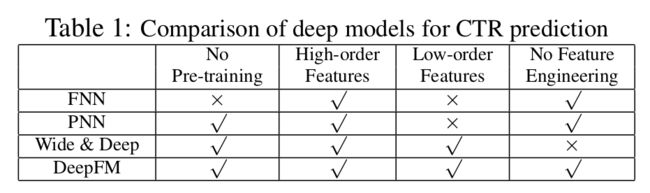
作者认为,在CTR中,特征交叉是获得好的representation的一个重点,而且二阶特征交叉和多阶特征交叉显然都起着非常重要的作用。而广义的线性模型(如FTRL)缺少学习交叉特征的能力;而FM虽然擅长处理稀疏数据下的特征交叉,且理论上可以处理高阶特征交叉,然而由于较高的计算复杂度,现实中基本只能实现二阶特征交叉。
而DNN显然有获得复杂特征的能力。但是CNN更擅长处理临近特征的交互,在处理图像获取纹理等特征时更有优势;而RNN更适合处理依赖时序关系的点击关系,一般场景用不到;同时期的其他尝试见Table 1,如Wide&&Deep模型,可以同时处理低阶和高阶特征交叉,然而仍需要专业的特征工程处理;FNN和PNN几乎没有学习低阶交叉特征的能力,其中FNN还需要预训练FM获得隐向量后再作为DNN的输入embedding的初始化,不能做到端到端学习。工业应用中,更喜欢端到端学习,简单粗暴又高效。
2.DeepFM结构
DeepFM将FM的embedding和DNN部分共享,什么意思呢?看过FNN模型的应该很容易理解这一点。实际上,FM也可以看成一种特殊的embedding,特殊在哪呢,只有非零特征xi对应的连接权重wij(j=1,2,…隐藏层节点数)起了作用。
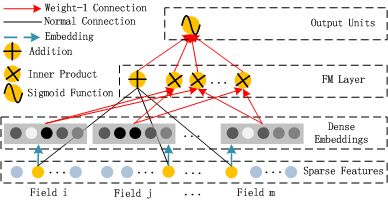
首先看下上图所示FM部分,获得每个特征的隐向量,然后做二阶特征交叉(Inner Product).如果为离散特征,xj为1,连续特征,xj为特征值.从下图中我们可以看出FM其实就是一种特殊的embedding,将其用神经网络的形式展现了出来,实际上还是在做FM的事情:
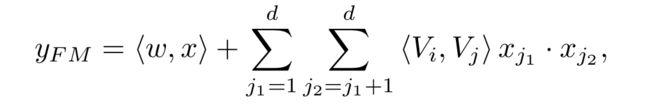
然后就是下图所示的DNN部分,中间是几层神经网络,输入的Dense Embeddings就是FM的隐向量,这里就是DeepFM所谓的共享。
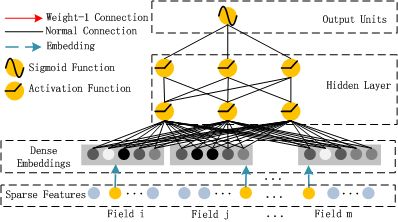
DNN这部分的计算就是常见的前向传播,假设有l层隐藏层,那么记a(0)为输入,则输出a(l+1)为:
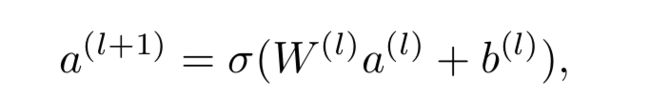
然后把两者结合在一起,即下图中的FM+DNN==》DeepFM。具体怎么结合的呢,后面再说。

3.实战
3.1 多值离散特征的处理
多值离散特征代码中没有涉及到,但仍需要提一下.每个field都是单值离散特征时,在tensorflow中很容易处理(本文代码就是),而当某个field是多值离散特征时,输入的X的维度不确定,这时可以使用SparseTensor张量,有两种方式.
第一种所有的特征统一编号顺序,比如5000维编为0-4999,然后使用self.X = tf.sparse_placeholder(dtype)获得SparseTensor张量;第二种方式是将每个field分开编号,然后使用tf.contrib.lookup.index_table_from_tensor获得SparseTensor**(可以参考1中的例子**).
使用第二种方式进行后面的lookup查找时有一个问题,即有n个field只能获得n个隐向量,因为tf.nn.embedding_lookup_sparse默认会将一个field的几个隐向量进行sum求和处理.
3.2 ROC
对于二分类问题,可以根据真实标签和预测标签分为四中情况,True Postive(TP), False Positive(FP), False Negative(FN), True Negative(TN)[3]:

(1) 真阳性(True Positive,TP):检测不健康,且实际不健康;正确肯定的匹配数目;
(2) 假阳性(False Positive,FP):检测不健康,但实际健康;误报,给出的匹配是不正确的;
(3) 真阴性(True Negative,TN):检测健康,且实际健康;正确拒绝的非匹配数目;
(4) 假阴性(False Negative,FN):检测健康,但实际不健康;漏报,没有正确找到的匹配的数目。
对于每个混淆矩阵,我们计算两个指标TPR和FPR,以FPR为x轴,TPR为y轴画图,就得到了ROC曲线[3]:
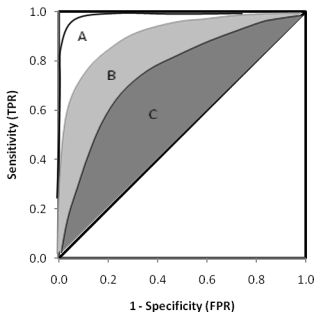
二分类中,ROC不能清晰地说明哪个效果更好,此时可以用另一个指标来评测:AUC(Area under curse),即ROC曲线下的面积,一般在0.5~1之间,越大越好。源代码中用的评测指标是AUC,本实验中改成了logloss。读者可自行尝试。
3.3 DeepFM模型实现
下面看下DeepFM的代码.
首先是特征下标和特征值的记录:
self.feat_index = tf.placeholder(tf.int32,shape=[None,None],name='feat_index')
self.feat_value = tf.placeholder(tf.float32,shape=[None,None],name='feat_value')
然后是计算embeddings:
self.embeddings = tf.nn.embedding_lookup(self.weights['feature_embeddings'],self.feat_index)
feat_value = tf.reshape(self.feat_value,shape=[-1,self.field_size,1])
self.embeddings = tf.multiply(self.embeddings,feat_value)
一阶线性部分如下:
self.y_first_order = tf.nn.embedding_lookup(self.weights['feature_bias'],self.feat_index)
self.y_first_order = tf.reduce_sum(tf.multiply(self.y_first_order,feat_value),2)
self.y_first_order = tf.nn.dropout(self.y_first_order,self.dropout_keep_fm[0])
二阶交叉的计算:
self.summed_features_emb = tf.reduce_sum(self.embeddings,1) # None * k
self.summed_features_emb_square = tf.square(self.summed_features_emb) # None * K
self.squared_features_emb = tf.square(self.embeddings)
self.squared_sum_features_emb = tf.reduce_sum(self.squared_features_emb, 1) # None * K
self.y_second_order = 0.5 * tf.subtract(self.summed_features_emb_square,self.squared_sum_features_emb)
self.y_second_order = tf.nn.dropout(self.y_second_order,self.dropout_keep_fm[1])
然后是DNN部分:
self.y_deep = tf.reshape(self.embeddings,shape=[-1,self.field_size * self.embedding_size])
self.y_deep = tf.nn.dropout(self.y_deep,self.dropout_keep_deep[0])
for i in range(0,len(self.deep_layers)):
self.y_deep = tf.add(tf.matmul(self.y_deep,self.weights["layer_%d" %i]), self.weights["bias_%d"%i])
self.y_deep = self.deep_layers_activation(self.y_deep)
self.y_deep = tf.nn.dropout(self.y_deep,self.dropout_keep_deep[i+1])
最后把输出结果concatenate,然后接上一层全连接:
concat_input = tf.concat([self.y_first_order, self.y_second_order, self.y_deep], axis=1)
self.out = tf.add(tf.matmul(concat_input,self.weights['concat_projection']),self.weights['concat_bias'])
最后输出层的实现其实需要说道说道。两种模型输出结果的结合一般有两种方式,第一种是输出结果为概率值这种,将多个模型的结果加权,可以直接用w和1-w配置权重,也可以将两种概率结果concatenate,然后接个全连接层;第二种是输出结果是多维特征,此时最简单的方法是将特征串联,然后接几层全连接层进行计算。更深入的内容大家可以去看看多模态融合,跨模态检索,模型融合,集成学习这块。代码中用的是第二种。大家可以试着调试调试代码~
完整数据和代码:https://github.com/wyl6/Recommender-Systems-Samples/tree/master/RecSys%20And%20Deep%20Learning/DNN/deepfm
模型实现参考代码:https://github.com/ChenglongChen/tensorflow-DeepFM
数据处理参考代码:https://github.com/princewen/tensorflow_practice/blob/master/recommendation/Basic-DeepFM-model/main.py
参考
[1] https://www.jianshu.com/p/63359e928b99
[2] DeepFM: A Factorization-Machine based Neural Network for CTR Prediction
[3] https://www.plob.org/article/12476.html