跨域预训练语言模型(XLM)
XLM来自于Facebook ai的论文《Cross-lingual Language Model Pretraining》。目前多数语言模型都是单语义(monolingual)模型,比如BERT、XLNET、google的T5等等。期望有一种语言模型可以实现多种语言的融合,然后在一种语言训练模型,通过XLM迁移到其他语言上。比如标注语料较多的英语,我们训练好EN-》DE的翻译模型,但是,像印地语这种比较少见的语言怎么训练它到DE的翻译呢?这种情况下通过XLM就可以实现印地语到英语的迁移,然后再翻译到DE的模型。
以上是XLM一个大致的描述。训练XLM使用两种方式:
1、无监督学习方式,仅仅依赖于各种语言的预料文本。
2、监督学习方式,使用平行语料的一个新的跨域语言模型。
我们通过XLM将任何句子编码到一个共享的embedding空间。之前很多工作达到这样的效果都需要大量的平行语料,也就是类似于翻译语料的东西。但是发现有些人提出的无监督机器翻译,不使用平行语料也可以获得较高的BLEU。所以XLM也借鉴了这种思想。
接下来介绍XLM的三个重要组成部分:
其中的两个完全无监督方式学习,其中的一个需要平行语料(parallel sentences)也就是需要通过监督的方式学习。如果无特殊说明,我们默认有N中语言 { C i } , i = 1... N {\{C_i\},i=1...N} {Ci},i=1...N, n i n_i ni代表 C i C_i Ci中句子的数量。
1、共享分词词典
所有语言通过BPE(Byte Pair Encoding)创建共享词典,这样共享了一些词或者一些恰当的发音。学习BPE的时候,通过一定的概率在各个语言的数据集上采样。然后将采样的这些句子串联起来。每一种语言的采样概率如下:
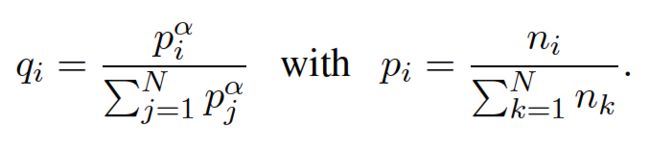
上面的 α = 0.5 \alpha=0.5 α=0.5,按照上面采样增加了低资源语言的tokens数量,避免了字典向高资源语言偏移。
2、因果语言模型(CLM)
CLM模型就是通过前面的序列预测当前词出现的概率。公式: P ( w t ∣ w 1 , . . . w t − 1 , θ ) P(w_t|w_1,...w_t-1,\theta) P(wt∣w1,...wt−1,θ)。
3、掩码语言模型(MLM)
这个任务和BERT的处理方式类似,仍然是随机掩盖句子中15%的token,80%的时间使用[MASK]掩盖,10%的时间从字典中随机挑选一个词,10%的时间保持不变。与BERT不同的是,输入不再是一个句子对,而是一个256的长句子,去除了BERT的NSP任务。
4、翻译语言模型(TLM)
CLM和MLM都是无监督学习方式,但是当存在平行语料时候,使用他们并不合适。这时候就需要翻译语言模型TLM(Translation Language Modeling),TLM的引入可以提高XLM的效果。本文的TLM是MLM的一个扩展。我们将翻译语料对连接,然后在源语言和目标语言中均做随机mask。如下图:

如上图所示,如果预测英语中的mask,模型既可以关注周围的英文单词,也可以关注法语的翻译,这样可以使得模型将英语和法语对齐。并且在预测某个MASK英语单词时候,如果英文信息不足以预测出这个单词,法语上下文可以辅助预测。为了便于对齐,mask法语时候,我们会对其中位置进行错开。
5、跨域语言模型(XLM)
XLM的训练如果是纯无监督方式则,使用CLM、MLM。使用batch size为64,每个句子由连续的256个字符组成。每个batch的数据采样自同一种语言,采样概率公式和1中的类似,只是 α = 0.7 \alpha=0.7 α=0.7
XLM使用有监督方式则是MLM结合TLM或者CLM结合TLM。
以上是XLM中使用到的关键技术。
Facebook的最新论文《Unsupervised Cross-lingual Representation Learning at Scale》中使用RoBERTa,其中相对于本文的改进就是MLM那块,一个是使用了动态masking技术。把预训练的数据复制10份,每一份都随机选择15%的Tokens进行Masking,也就是说,同样的一句话有10种不同的mask方式。
另一个是每次输入连续的多个句子,直到最大长度512。
还有就是batch size增加到了8k。
使用更大容量的多语言文本数据集CommonCrawl data。训练时间更久。在各种迁移任务上又获得了state-of-art的效果。
接下来看看XLM怎么应用:
1、跨语言分类
首先看在多语言分类上的表现,这里使用数据集XNLI,它里面有15种不同的语言,包括英语、法语、西班牙语、德语、希腊语、保加利亚语、俄语、土耳其语、阿拉伯语、越南语、泰语、中文、印地语、斯瓦希里语和乌尔都语。数据集中的部分示例如下:

这里的fine-tuning与bert的调优类似。取预训练模型最后一层的第一个隐状态送入线性分类器。我们首先利用XLM在英语NLI训练数据集上进行调优,然后我们在其他语言上测试。测试结果如下:
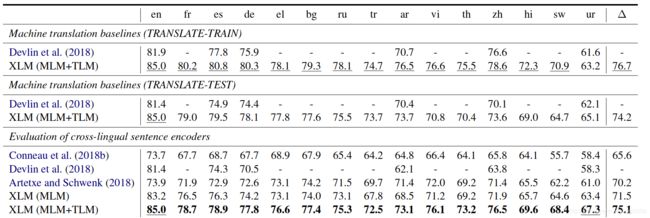
这个表显示了两种类型的结果:无监督地利用单语义语料和利用平行语料的有监督MLM结合TLM。做了两种baseline:TRANSLATE-TRAIN这一个是英语NLI训练数据集翻译成每种NLI,TRANSLATE-TEST是每个待测试的数据集翻译成英文。这里我们和mBert(multilingual BERT)做对比。
最后一组是衡量跨语言迁移的效果,这里以Conneau的模型作为baseline。可以看到XLM均获得比较高的提升。
2、无监督机器翻译
无监督机器翻译做了三组:
英语-》法语;
英语-〉德语;
英语-》罗马尼亚语。
训练方法跟Lample提出方法一样。与仅查找词向量表不同,我们使用跨语言模型初始化整个模型。对于编码器和解码器,我们考虑使用不同方式的初始化方法:CLM预训练,MLM预训练,随机初始化。这样的话就有九种对比实验。以使用跨语言词向量(EMB)作为baseline。

3、监督学习翻译
监督学习对比了罗马尼亚语和英语的翻译效果。
分为三组:
罗马尼亚语翻译成英文
罗马尼亚语与英文互翻
使用反向翻译技术的罗马尼亚语与英语翻译,模型在训练语言模型时候使用单语语料。

4、低资源语言模型
这里以尼泊尔语为例,这种语言在维基数据上只有100K句话,大约是海地语的6倍。Nepali和Hindi之间字母表上有很大重叠,语言关系比较近,而跟英语之间则关系不大,所以引入英语对于Nepali带来的提升没有引入Hindi带来的提升多。

5、无监督跨域词嵌入
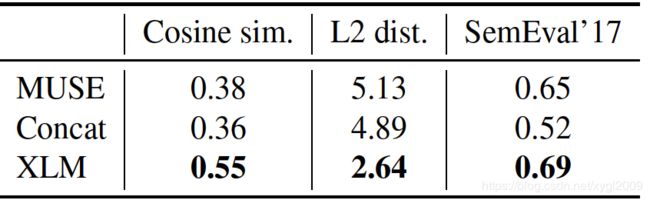
这里对比了三种方法:MUSE(facebook在2017年提出的一种语言模型)、Concat、XLM。三种评估方法:词翻译之间的cosine相似度、L2距离。还有一种新的评估跨语言cosine相似度方法SemEval’17。实验发现XLM表现依然非常好。
项目地址:https://github.com/facebookresearch/XLM